 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTFS : Collaborative Teacher Framework for Forward-Looking Sonar Image Semantic Segmentation with Extremely Limited Labels
Mar 22, 2026As one of the most important underwater sensing technologies, forward-looking sonar exhibits unique imaging characteristics. Sonar images are often affected by severe speckle noise, low texture contrast, acoustic shadows, and geometric distortions. These factors make it difficult for traditional teacher-student frameworks to achieve satisfactory performance in sonar semantic segmentation tasks under extremely limited labeled data conditions. To address this issue, we propose a Collaborative Teacher Semantic Segmentation Framework for forward-looking sonar images. This framework introduces a multi-teacher collaborative mechanism composed of one general teacher and multiple sonar-specific teachers. By adopting a multi-teacher alternating guidance strategy, the student model can learn general semantic representations while simultaneously capturing the unique characteristics of sonar images, thereby achieving more comprehensive and robust feature modeling. Considering the challenges of sonar images, which can lead teachers to generate a large number of noisy pseudo-labels, we further design a cross-teacher reliability assessment mechanism. This mechanism dynamically quantifies the reliability of pseudo-labels by evaluating the consistency and stability of predictions across multiple views and multiple teachers, thereby mitigating the negative impact caused by noisy pseudo-labels. Notably, on the FLSMD dataset, when only 2% of the data is labeled, our method achieves a 5.08% improvement in mIoU compared to other state-of-the-art approaches.
RSOD: Reliability-Guided Sonar Image Object Detection with Extremely Limited Labels
Jan 19, 2026Object detection in sonar images is a key technology in underwater detection systems. Compared to natural images, sonar images contain fewer texture details and are more susceptible to noise, making it difficult for non-experts to distinguish subtle differences between classes. This leads to their inability to provide precise annotation data for sonar images. Therefore, designing effective object detection methods for sonar images with extremely limited labels is particularly important. To address this, we propose a teacher-student framework called RSOD, which aims to fully learn the characteristics of sonar images and develop a pseudo-label strategy suitable for these images to mitigate the impact of limited labels. First, RSOD calculates a reliability score by assessing the consistency of the teacher's predictions across different views. To leverage this score, we introduce an object mixed pseudo-label method to tackle the shortage of labeled data in sonar images. Finally, we optimize the performance of the student by implementing a reliability-guided adaptive constraint. By taking full advantage of unlabeled data, the student can perform well even in situations with extremely limited labels. Notably, on the UATD dataset, our method, using only 5% of labeled data, achieves results that can compete against those of our baseline algorithm trained on 100% labeled data. We also collected a new dataset to provide more valuable data for research in the field of sonar.
VoiceCraft-X: Unifying Multilingual, Voice-Cloning Speech Synthesis and Speech Editing
Nov 15, 2025We introduce VoiceCraft-X, an autoregressive neural codec language model which unifies multilingual speech editing and zero-shot Text-to-Speech (TTS) synthesis across 11 languages: English, Mandarin, Korean, Japanese, Spanish, French, German, Dutch, Italian, Portuguese, and Polish. VoiceCraft-X utilizes the Qwen3 large language model for phoneme-free cross-lingual text processing and a novel token reordering mechanism with time-aligned text and speech tokens to handle both tasks as a single sequence generation problem. The model generates high-quality, natural-sounding speech, seamlessly creating new audio or editing existing recordings within one framework. VoiceCraft-X shows robust performance in diverse linguistic settings, even with limited per-language data, underscoring the power of unified autoregressive approaches for advancing complex, real-world multilingual speech applications. Audio samples are available at https://zhishengzheng.com/voicecraft-x/.
EAGLE: Episodic Appearance- and Geometry-aware Memory for Unified 2D-3D Visual Query Localization in Egocentric Vision
Nov 12, 2025Egocentric visual query localization is vital for embodied AI and VR/AR, yet remains challenging due to camera motion, viewpoint changes, and appearance variations. We present EAGLE, a novel framework that leverages episodic appearance- and geometry-aware memory to achieve unified 2D-3D visual query localization in egocentric vision. Inspired by avian memory consolidation, EAGLE synergistically integrates segmentation guided by an appearance-aware meta-learning memory (AMM), with tracking driven by a geometry-aware localization memory (GLM). This memory consolidation mechanism, through structured appearance and geometry memory banks, stores high-confidence retrieval samples, effectively supporting both long- and short-term modeling of target appearance variations. This enables precise contour delineation with robust spatial discrimination, leading to significantly improved retrieval accuracy. Furthermore, by integrating the VQL-2D output with a visual geometry grounded Transformer (VGGT), we achieve a efficient unification of 2D and 3D tasks, enabling rapid and accurate back-projection into 3D space. Our method achieves state-ofthe-art performance on the Ego4D-VQ benchmark.
RefTok: Reference-Based Tokenization for Video Generation
Jul 03, 2025Effectively handling temporal redundancy remains a key challenge in learning video models. Prevailing approaches often treat each set of frames independently, failing to effectively capture the temporal dependencies and redundancies inherent in videos. To address this limitation, we introduce RefTok, a novel reference-based tokenization method capable of capturing complex temporal dynamics and contextual information. Our method encodes and decodes sets of frames conditioned on an unquantized reference frame. When decoded, RefTok preserves the continuity of motion and the appearance of objects across frames. For example, RefTok retains facial details despite head motion, reconstructs text correctly, preserves small patterns, and maintains the legibility of handwriting from the context. Across 4 video datasets (K600, UCF-101, BAIR Robot Pushing, and DAVIS), RefTok significantly outperforms current state-of-the-art tokenizers (Cosmos and MAGVIT) and improves all evaluated metrics (PSNR, SSIM, LPIPS) by an average of 36.7% at the same or higher compression ratios. When a video generation model is trained using RefTok's latents on the BAIR Robot Pushing task, the generations not only outperform MAGVIT-B but the larger MAGVIT-L, which has 4x more parameters, across all generation metrics by an average of 27.9%.
DEAL: Data-Efficient Adversarial Learning for High-Quality Infrared Imaging
Mar 02, 2025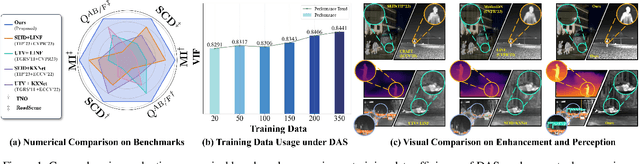
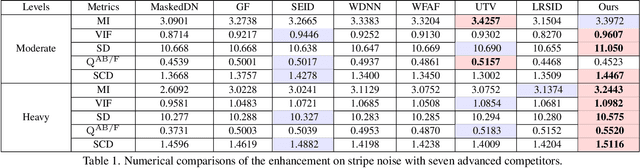
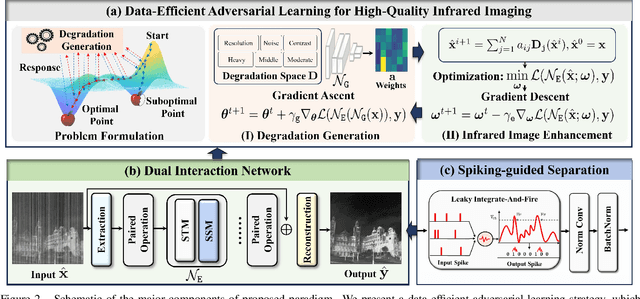
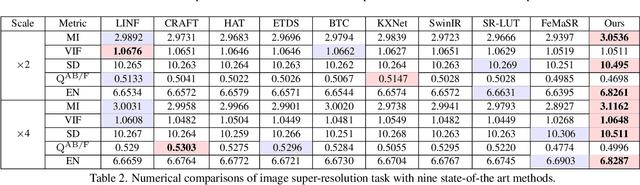
Thermal imaging is often compromised by dynamic, complex degradations caused by hardware limitations and unpredictable environmental factors. The scarcity of high-quality infrared data, coupled with the challenges of dynamic, intricate degradations, makes it difficult to recover details using existing methods. In this paper, we introduce thermal degradation simulation integrated into the training process via a mini-max optimization, by modeling these degraded factors as adversarial attacks on thermal images. The simulation is dynamic to maximize objective functions, thus capturing a broad spectrum of degraded data distributions. This approach enables training with limited data, thereby improving model performance.Additionally, we introduce a dual-interaction network that combines the benefits of spiking neural networks with scale transformation to capture degraded features with sharp spike signal intensities. This architecture ensures compact model parameters while preserving efficient feature representation. Extensive experiments demonstrate that our method not only achieves superior visual quality under diverse single and composited degradation, but also delivers a significant reduction in processing when trained on only fifty clear images, outperforming existing techniques in efficiency and accuracy. The source code will be available at https://github.com/LiuZhu-CV/DEAL.
Exploring the Small World of Word Embeddings: A Comparative Study on Conceptual Spaces from LLMs of Different Scales
Feb 17, 2025A conceptual space represents concepts as nodes and semantic relatedness as edges. Word embeddings, combined with a similarity metric, provide an effective approach to constructing such a space. Typically, embeddings are derived from traditional distributed models or encoder-only pretrained models, whose objectives directly capture the meaning of the current token. In contrast, decoder-only models, including large language models (LLMs), predict the next token, making their embeddings less directly tied to the current token's semantics. Moreover, comparative studies on LLMs of different scales remain underexplored. In this paper, we construct a conceptual space using word embeddings from LLMs of varying scales and comparatively analyze their properties. We establish a network based on a linguistic typology-inspired connectivity hypothesis, examine global statistical properties, and compare LLMs of varying scales. Locally, we analyze conceptual pairs, WordNet relations, and a cross-lingual semantic network for qualitative words. Our results indicate that the constructed space exhibits small-world properties, characterized by a high clustering coefficient and short path lengths. Larger LLMs generate more intricate spaces, with longer paths reflecting richer relational structures and connections. Furthermore, the network serves as an efficient bridge for cross-lingual semantic mapping.
GLTW: Joint Improved Graph Transformer and LLM via Three-Word Language for Knowledge Graph Completion
Feb 17, 2025Knowledge Graph Completion (KGC), which aims to infer missing or incomplete facts, is a crucial task for KGs. However, integrating the vital structural information of KGs into Large Language Models (LLMs) and outputting predictions deterministically remains challenging. To address this, we propose a new method called GLTW, which encodes the structural information of KGs and merges it with LLMs to enhance KGC performance. Specifically, we introduce an improved Graph Transformer (iGT) that effectively encodes subgraphs with both local and global structural information and inherits the characteristics of language model, bypassing training from scratch. Also, we develop a subgraph-based multi-classification training objective, using all entities within KG as classification objects, to boost learning efficiency.Importantly, we combine iGT with an LLM that takes KG language prompts as input.Our extensive experiments on various KG datasets show that GLTW achieves significant performance gains compared to SOTA baselines.
CRPO: Confidence-Reward Driven Preference Optimization for Machine Translation
Jan 23, 2025



Large language models (LLMs) have shown great potential in natural language processing tasks, but their application to machine translation (MT) remains challenging due to pretraining on English-centric data and the complexity of reinforcement learning from human feedback (RLHF). Direct Preference Optimization (DPO) has emerged as a simpler and more efficient alternative, but its performance depends heavily on the quality of preference data. To address this, we propose Confidence-Reward driven Preference Optimization (CRPO), a novel method that combines reward scores with model confidence to improve data selection for fine-tuning. CRPO selects challenging sentence pairs where the model is uncertain or underperforms, leading to more effective learning. While primarily designed for LLMs, CRPO also generalizes to encoder-decoder models like NLLB, demonstrating its versatility. Empirical results show that CRPO outperforms existing methods such as RS-DPO, RSO and MBR score in both translation accuracy and data efficiency.
Infrared and Visible Image Fusion: From Data Compatibility to Task Adaption
Jan 18, 2025Infrared-visible image fusion (IVIF) is a critical task in computer vision, aimed at integrating the unique features of both infrared and visible spectra into a unified representation. Since 2018, the field has entered the deep learning era, with an increasing variety of approaches introducing a range of networks and loss functions to enhance visual performance. However, challenges such as data compatibility, perception accuracy, and efficiency remain. Unfortunately, there is a lack of recent comprehensive surveys that address this rapidly expanding domain. This paper fills that gap by providing a thorough survey covering a broad range of topics. We introduce a multi-dimensional framework to elucidate common learning-based IVIF methods, from visual enhancement strategies to data compatibility and task adaptability. We also present a detailed analysis of these approaches, accompanied by a lookup table clarifying their core ideas. Furthermore, we summarize performance comparisons, both quantitatively and qualitatively, focusing on registration, fusion, and subsequent high-level tasks. Beyond technical analysis, we discuss potential future directions and open issues in this area. For further details, visit our GitHub repository: https://github.com/RollingPlain/IVIF_ZOO.