 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefDecoder: Enhancing Visual Generation with Conditional Video Decoding
May 14, 2026Video generation powers a vast array of downstream applications. However, while the de facto standard, i.e., latent diffusion models, typically employ heavily conditioned denoising networks, their decoders often remain unconditional. We observe that this architectural asymmetry leads to significant loss of detail and inconsistency relative to the input image. To address this, we argue that the decoder requires equal conditioning to preserve structural integrity. We introduce RefDecoder, a reference-conditioned video VAE decoder by injecting high-fidelity reference image signal directly into the decoding process via reference attention. Specifically, a lightweight image encoder maps the reference frame into the detail-rich high-dimensional tokens, which are co-processed with the denoised video latent tokens at each decoder up-sampling stage. We demonstrate consistent improvements across several distinct decoder backbones (e.g., Wan 2.1 and VideoVAE+), achieving up to +2.1dB PSNR over the unconditional baselines on the Inter4K, WebVid, and Large Motion reconstruction benchmarks. Notably, RefDecoder can be directly swapped into existing video generation systems without additional fine-tuning, and we report across-the-board improvements in subject consistency, background consistency, and overall quality scores on the VBench I2V benchmark. Beyond I2V, RefDecoder generalizes well to a wide range of visual generation tasks such as style transfer and video editing refinement.
MolmoAct2: Action Reasoning Models for Real-world Deployment
May 04, 2026Vision-Language-Action (VLA) models aim to provide a single generalist controller for robots, but today's systems fall short on the criteria that matter for real-world deployment. Frontier models are closed, open-weight alternatives are tied to expensive hardware, reasoning-augmented policies pay prohibitive latency for their grounding, and fine-tuned success rates remain below the threshold for dependable use. We present MolmoAct2, a fully open action reasoning model built for practical deployment, advancing its predecessor along five axes. We introduce MolmoER, a VLM backbone specialized for spatial and embodied reasoning, trained on a 3.3M-sample corpus with a specialize-then-rehearse recipe. We release three new datasets spanning low-to-medium cost platforms, including MolmoAct2-BimanualYAM, 720 hours of teleoperated bimanual trajectories that constitute the largest open bimanual dataset to date, together with quality-filtered Franka (DROID) and SO100/101 subsets. We provide OpenFAST, an open-weight, open-data action tokenizer trained on millions of trajectories across five embodiments. We redesign the architecture to graft a flow-matching continuous-action expert onto a discrete-token VLM via per-layer KV-cache conditioning. Finally, we propose MolmoThink, an adaptive-depth reasoning variant that re-predicts depth tokens only for scene regions that change between timesteps, retaining geometric grounding at a fraction of prior latency. In the most extensive empirical study of any open VLA to date, spanning 7 simulation and real-world benchmarks, MolmoAct2 outperforms strong baselines including Pi-05, while MolmoER surpasses GPT-5 and Gemini Robotics ER-1.5 across 13 embodied-reasoning benchmarks. We release model weights, training code, and complete training data. Project page: https://allenai.org/blog/molmoact2
OmniView: An All-Seeing Diffusion Model for 3D and 4D View Synthesis
Dec 11, 2025
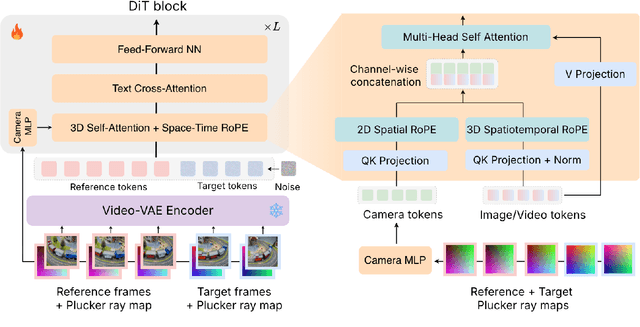
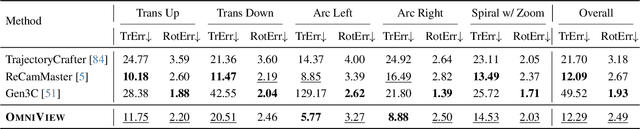

Prior approaches injecting camera control into diffusion models have focused on specific subsets of 4D consistency tasks: novel view synthesis, text-to-video with camera control, image-to-video, amongst others. Therefore, these fragmented approaches are trained on disjoint slices of available 3D/4D data. We introduce OmniView, a unified framework that generalizes across a wide range of 4D consistency tasks. Our method separately represents space, time, and view conditions, enabling flexible combinations of these inputs. For example, OmniView can synthesize novel views from static, dynamic, and multiview inputs, extrapolate trajectories forward and backward in time, and create videos from text or image prompts with full camera control. OmniView is competitive with task-specific models across diverse benchmarks and metrics, improving image quality scores among camera-conditioned diffusion models by up to 33\% in multiview NVS LLFF dataset, 60\% in dynamic NVS Neural 3D Video benchmark, 20\% in static camera control on RE-10K, and reducing camera trajectory errors by 4x in text-conditioned video generation. With strong generalizability in one model, OmniView demonstrates the feasibility of a generalist 4D video model. Project page is available at https://snap-research.github.io/OmniView/
RefTok: Reference-Based Tokenization for Video Generation
Jul 03, 2025Effectively handling temporal redundancy remains a key challenge in learning video models. Prevailing approaches often treat each set of frames independently, failing to effectively capture the temporal dependencies and redundancies inherent in videos. To address this limitation, we introduce RefTok, a novel reference-based tokenization method capable of capturing complex temporal dynamics and contextual information. Our method encodes and decodes sets of frames conditioned on an unquantized reference frame. When decoded, RefTok preserves the continuity of motion and the appearance of objects across frames. For example, RefTok retains facial details despite head motion, reconstructs text correctly, preserves small patterns, and maintains the legibility of handwriting from the context. Across 4 video datasets (K600, UCF-101, BAIR Robot Pushing, and DAVIS), RefTok significantly outperforms current state-of-the-art tokenizers (Cosmos and MAGVIT) and improves all evaluated metrics (PSNR, SSIM, LPIPS) by an average of 36.7% at the same or higher compression ratios. When a video generation model is trained using RefTok's latents on the BAIR Robot Pushing task, the generations not only outperform MAGVIT-B but the larger MAGVIT-L, which has 4x more parameters, across all generation metrics by an average of 27.9%.
Contrastive Flow Matching
Jun 05, 2025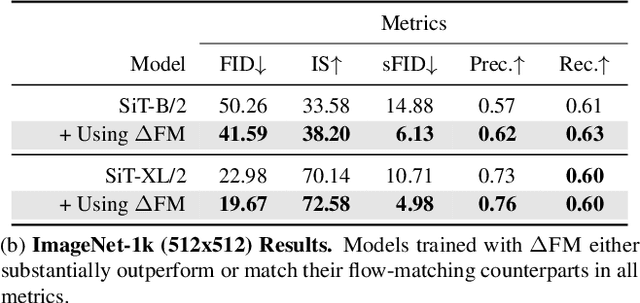

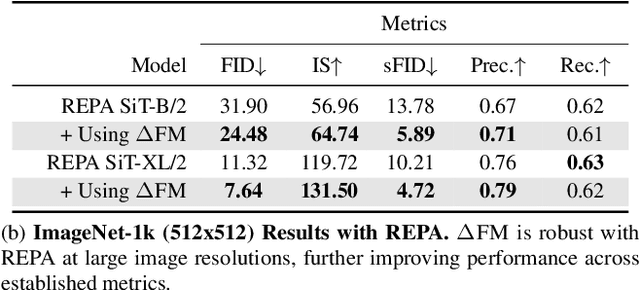
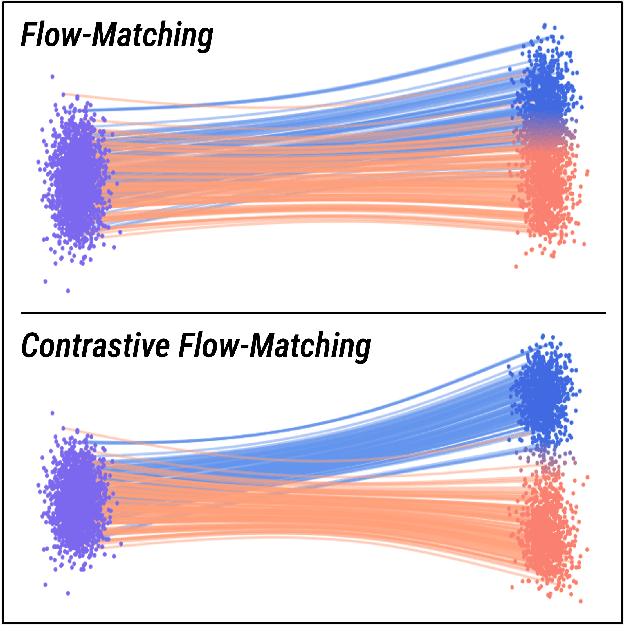
Unconditional flow-matching trains diffusion models to transport samples from a source distribution to a target distribution by enforcing that the flows between sample pairs are unique. However, in conditional settings (e.g., class-conditioned models), this uniqueness is no longer guaranteed--flows from different conditions may overlap, leading to more ambiguous generations. We introduce Contrastive Flow Matching, an extension to the flow matching objective that explicitly enforces uniqueness across all conditional flows, enhancing condition separation. Our approach adds a contrastive objective that maximizes dissimilarities between predicted flows from arbitrary sample pairs. We validate Contrastive Flow Matching by conducting extensive experiments across varying model architectures on both class-conditioned (ImageNet-1k) and text-to-image (CC3M) benchmarks. Notably, we find that training models with Contrastive Flow Matching (1) improves training speed by a factor of up to 9x, (2) requires up to 5x fewer de-noising steps and (3) lowers FID by up to 8.9 compared to training the same models with flow matching. We release our code at: https://github.com/gstoica27/DeltaFM.git.
Videoshop: Localized Semantic Video Editing with Noise-Extrapolated Diffusion Inversion
Mar 22, 2024

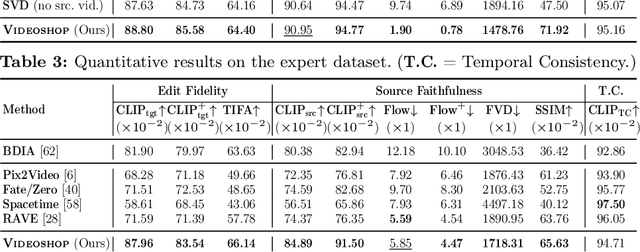
We introduce Videoshop, a training-free video editing algorithm for localized semantic edits. Videoshop allows users to use any editing software, including Photoshop and generative inpainting, to modify the first frame; it automatically propagates those changes, with semantic, spatial, and temporally consistent motion, to the remaining frames. Unlike existing methods that enable edits only through imprecise textual instructions, Videoshop allows users to add or remove objects, semantically change objects, insert stock photos into videos, etc. with fine-grained control over locations and appearance. We achieve this through image-based video editing by inverting latents with noise extrapolation, from which we generate videos conditioned on the edited image. Videoshop produces higher quality edits against 6 baselines on 2 editing benchmarks using 10 evaluation metrics.
MultiZoo & MultiBench: A Standardized Toolkit for Multimodal Deep Learning
Jun 28, 2023

Learning multimodal representations involves integrating information from multiple heterogeneous sources of data. In order to accelerate progress towards understudied modalities and tasks while ensuring real-world robustness, we release MultiZoo, a public toolkit consisting of standardized implementations of > 20 core multimodal algorithms and MultiBench, a large-scale benchmark spanning 15 datasets, 10 modalities, 20 prediction tasks, and 6 research areas. Together, these provide an automated end-to-end machine learning pipeline that simplifies and standardizes data loading, experimental setup, and model evaluation. To enable holistic evaluation, we offer a comprehensive methodology to assess (1) generalization, (2) time and space complexity, and (3) modality robustness. MultiBench paves the way towards a better understanding of the capabilities and limitations of multimodal models, while ensuring ease of use, accessibility, and reproducibility. Our toolkits are publicly available, will be regularly updated, and welcome inputs from the community.
Model Stealing Attack against Multi-Exit Networks
May 23, 2023Compared to traditional neural networks with a single exit, a multi-exit network has multiple exits that allow for early output from intermediate layers of the model, thus bringing significant improvement in computational efficiency while maintaining similar recognition accuracy. When attempting to steal such valuable models using traditional model stealing attacks, we found that conventional methods can only steal the model's classification function while failing to capture its output strategy. This results in a significant decrease in computational efficiency for the stolen substitute model, thereby losing the advantages of multi-exit networks.In this paper, we propose the first model stealing attack to extract both the model function and output strategy. We employ bayesian changepoint detection to analyze the target model's output strategy and use performance loss and strategy loss to guide the training of the substitute model. Furthermore, we designed a novel output strategy search algorithm that can find the optimal output strategy to maximize the consistency between the victim model and the substitute model's outputs. Through experiments on multiple mainstream multi-exit networks and benchmark datasets, we thoroughly demonstrates the effectiveness of our method.
Quantifying & Modeling Feature Interactions: An Information Decomposition Framework
Feb 23, 2023The recent explosion of interest in multimodal applications has resulted in a wide selection of datasets and methods for representing and integrating information from different signals. Despite these empirical advances, there remain fundamental research questions: how can we quantify the nature of interactions that exist among input features? Subsequently, how can we capture these interactions using suitable data-driven methods? To answer this question, we propose an information-theoretic approach to quantify the degree of redundancy, uniqueness, and synergy across input features, which we term the PID statistics of a multimodal distribution. Using 2 newly proposed estimators that scale to high-dimensional distributions, we demonstrate their usefulness in quantifying the interactions within multimodal datasets, the nature of interactions captured by multimodal models, and principled approaches for model selection. We conduct extensive experiments on both synthetic datasets where the PID statistics are known and on large-scale multimodal benchmarks where PID estimation was previously impossible. Finally, to demonstrate the real-world applicability of our approach, we present three case studies in pathology, mood prediction, and robotic perception where our framework accurately recommends strong multimodal models for each application.
Nano: Nested Human-in-the-Loop Reward Learning for Few-shot Language Model Control
Nov 10, 2022
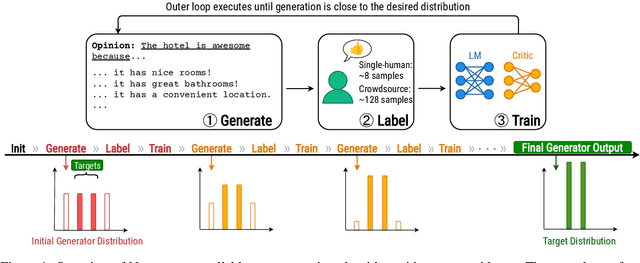
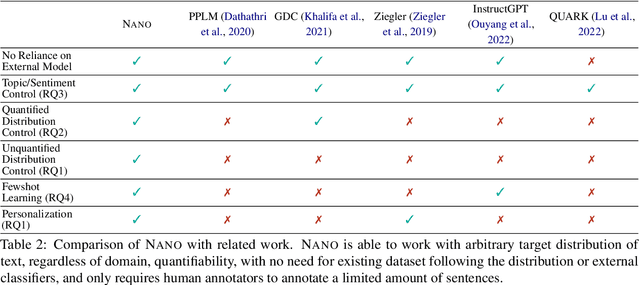
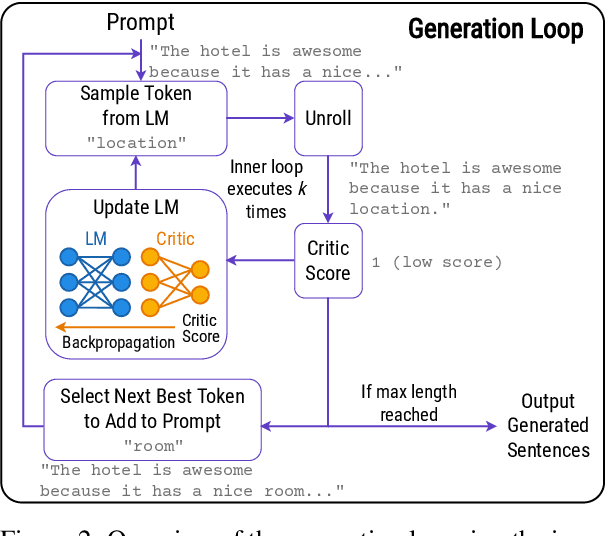
Pretrained language models have demonstrated extraordinary capabilities in language generation. However, real-world tasks often require controlling the distribution of generated text in order to mitigate bias, promote fairness, and achieve personalization. Existing techniques for controlling the distribution of generated text only work with quantified distributions, which require pre-defined categories, proportions of the distribution, or an existing corpus following the desired distributions. However, many important distributions, such as personal preferences, are unquantified. In this work, we tackle the problem of generating text following arbitrary distributions (quantified and unquantified) by proposing Nano, a few-shot human-in-the-loop training algorithm that continuously learns from human feedback. Nano achieves state-of-the-art results on single topic/attribute as well as quantified distribution control compared to previous works. We also show that Nano is able to learn unquantified distributions, achieves personalization, and captures differences between different individuals' personal preferences with high sample efficiency.