 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighMMT: Towards Modality and Task Generalization for High-Modality Representation Learning
Paper and Code

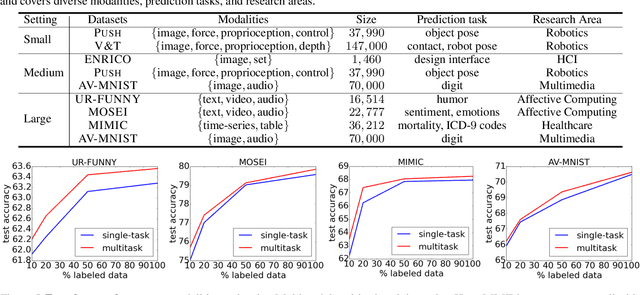

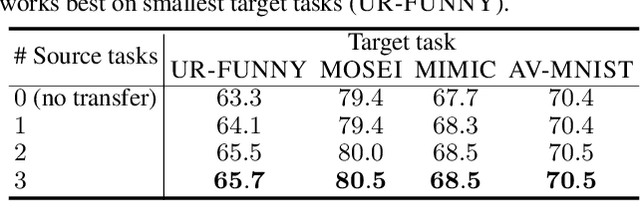
Learning multimodal representations involves discovering correspondences and integrating information from multiple heterogeneous sources of data. While recent research has begun to explore the design of more general-purpose multimodal models (contrary to prior focus on domain and modality-specific architectures), these methods are still largely focused on a small set of modalities in the language, vision, and audio space. In order to accelerate generalization towards diverse and understudied modalities, we investigate methods for high-modality (a large set of diverse modalities) and partially-observable (each task only defined on a small subset of modalities) scenarios. To tackle these challenges, we design a general multimodal model that enables multitask and transfer learning: multitask learning with shared parameters enables stable parameter counts (addressing scalability), and cross-modal transfer learning enables information sharing across modalities and tasks (addressing partial observability). Our resulting model generalizes across text, image, video, audio, time-series, sensors, tables, and set modalities from different research areas, improves the tradeoff between performance and efficiency, transfers to new modalities and tasks, and reveals surprising insights on the nature of information sharing in multitask models. We release our code and benchmarks which we hope will present a unified platform for subsequent theoretical and empirical analysis: https://github.com/pliang279/HighMMT.