 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceCraft-X: Unifying Multilingual, Voice-Cloning Speech Synthesis and Speech Editing
Nov 15, 2025We introduce VoiceCraft-X, an autoregressive neural codec language model which unifies multilingual speech editing and zero-shot Text-to-Speech (TTS) synthesis across 11 languages: English, Mandarin, Korean, Japanese, Spanish, French, German, Dutch, Italian, Portuguese, and Polish. VoiceCraft-X utilizes the Qwen3 large language model for phoneme-free cross-lingual text processing and a novel token reordering mechanism with time-aligned text and speech tokens to handle both tasks as a single sequence generation problem. The model generates high-quality, natural-sounding speech, seamlessly creating new audio or editing existing recordings within one framework. VoiceCraft-X shows robust performance in diverse linguistic settings, even with limited per-language data, underscoring the power of unified autoregressive approaches for advancing complex, real-world multilingual speech applications. Audio samples are available at https://zhishengzheng.com/voicecraft-x/.
Beyond Speaker Identity: Text Guided Target Speech Extraction
Jan 15, 2025Target Speech Extraction (TSE) traditionally relies on explicit clues about the speaker's identity like enrollment audio, face images, or videos, which may not always be available. In this paper, we propose a text-guided TSE model StyleTSE that uses natural language descriptions of speaking style in addition to the audio clue to extract the desired speech from a given mixture. Our model integrates a speech separation network adapted from SepFormer with a bi-modality clue network that flexibly processes both audio and text clues. To train and evaluate our model, we introduce a new dataset TextrolMix with speech mixtures and natural language descriptions. Experimental results demonstrate that our method effectively separates speech based not only on who is speaking, but also on how they are speaking, enhancing TSE in scenarios where traditional audio clues are absent. Demos are at: https://mingyue66.github.io/TextrolMix/demo/
LEMaRT: Label-Efficient Masked Region Transform for Image Harmonization
Apr 25, 2023



We present a simple yet effective self-supervised pre-training method for image harmonization which can leverage large-scale unannotated image datasets. To achieve this goal, we first generate pre-training data online with our Label-Efficient Masked Region Transform (LEMaRT) pipeline. Given an image, LEMaRT generates a foreground mask and then applies a set of transformations to perturb various visual attributes, e.g., defocus blur, contrast, saturation, of the region specified by the generated mask. We then pre-train image harmonization models by recovering the original image from the perturbed image. Secondly, we introduce an image harmonization model, namely SwinIH, by retrofitting the Swin Transformer [27] with a combination of local and global self-attention mechanisms. Pre-training SwinIH with LEMaRT results in a new state of the art for image harmonization, while being label-efficient, i.e., consuming less annotated data for fine-tuning than existing methods. Notably, on iHarmony4 dataset [8], SwinIH outperforms the state of the art, i.e., SCS-Co [16] by a margin of 0.4 dB when it is fine-tuned on only 50% of the training data, and by 1.0 dB when it is trained on the full training dataset.
Identity Enhanced Residual Image Denoising
Apr 26, 2020
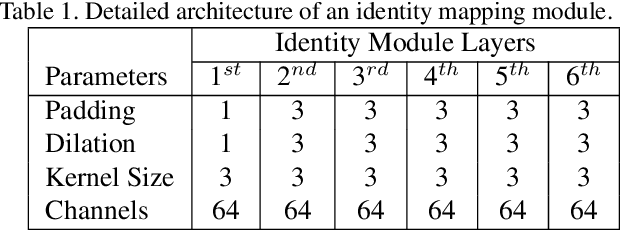

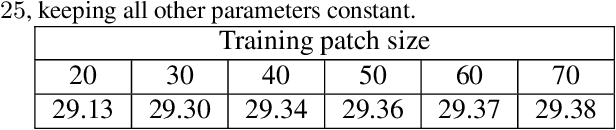
We propose to learn a fully-convolutional network model that consists of a Chain of Identity Mapping Modules and residual on the residual architecture for image denoising. Our network structure possesses three distinctive features that are important for the noise removal task. Firstly, each unit employs identity mappings as the skip connections and receives pre-activated input to preserve the gradient magnitude propagated in both the forward and backward directions. Secondly, by utilizing dilated kernels for the convolution layers in the residual branch, each neuron in the last convolution layer of each module can observe the full receptive field of the first layer. Lastly, we employ the residual on the residual architecture to ease the propagation of the high-level information. Contrary to current state-of-the-art real denoising networks, we also present a straightforward and single-stage network for real image denoising. The proposed network produces remarkably higher numerical accuracy and better visual image quality than the classical state-of-the-art and CNN algorithms when being evaluated on the three conventional benchmark and three real-world datasets.
CRAFT: Complementary Recommendations Using Adversarial Feature Transformer
Sep 10, 2018
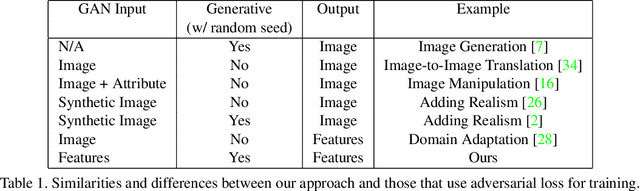
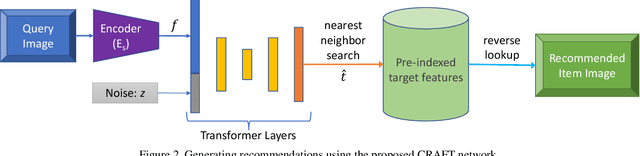
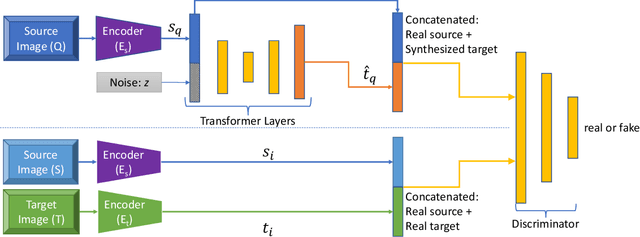
Traditional approaches for complementary product recommendations rely on behavioral and non-visual data such as customer co-views or co-buys. However, certain domains such as fashion are primarily visual. We propose a framework that harnesses visual cues in an unsupervised manner to learn the distribution of co-occurring complementary items in real world images. Our model learns a non-linear transformation between the two manifolds of source and target complementary item categories (e.g., tops and bottoms in outfits). Given a large dataset of images containing instances of co-occurring object categories, we train a generative transformer network directly on the feature representation space by casting it as an adversarial optimization problem. Such a conditional generative model can produce multiple novel samples of complementary items (in the feature space) for a given query item. The final recommendations are selected from the closest real world examples to the synthesized complementary features. We apply our framework to the task of recommending complementary tops for a given bottom clothing item. The recommendations made by our system are diverse, and are favored by human experts over the baseline approaches.
Can 3D Pose be Learned from 2D Projections Alone?
Aug 22, 2018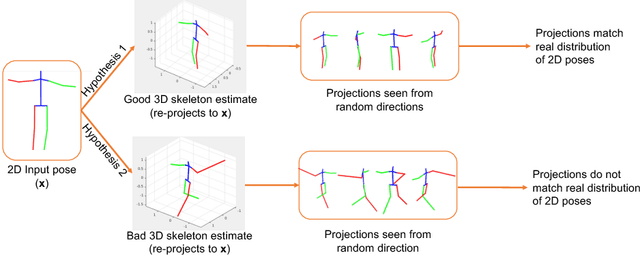
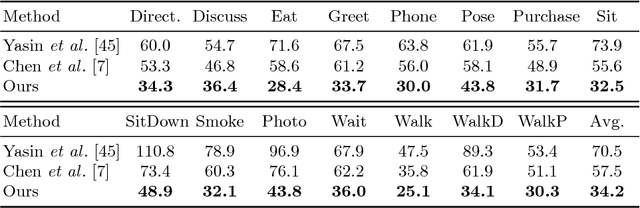
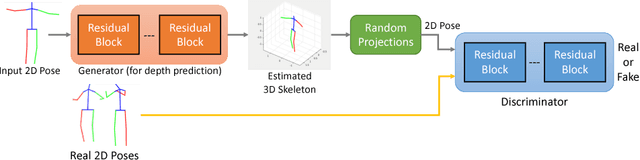
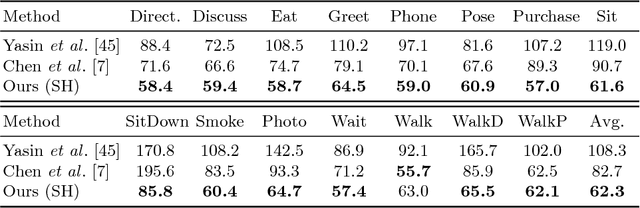
3D pose estimation from a single image is a challenging task in computer vision. We present a weakly supervised approach to estimate 3D pose points, given only 2D pose landmarks. Our method does not require correspondences between 2D and 3D points to build explicit 3D priors. We utilize an adversarial framework to impose a prior on the 3D structure, learned solely from their random 2D projections. Given a set of 2D pose landmarks, the generator network hypothesizes their depths to obtain a 3D skeleton. We propose a novel Random Projection layer, which randomly projects the generated 3D skeleton and sends the resulting 2D pose to the discriminator. The discriminator improves by discriminating between the generated poses and pose samples from a real distribution of 2D poses. Training does not require correspondence between the 2D inputs to either the generator or the discriminator. We apply our approach to the task of 3D human pose estimation. Results on Human3.6M dataset demonstrates that our approach outperforms many previous supervised and weakly supervised approaches.