 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised 3D Pose Estimation with Geometric Self-Supervision
Apr 09, 2019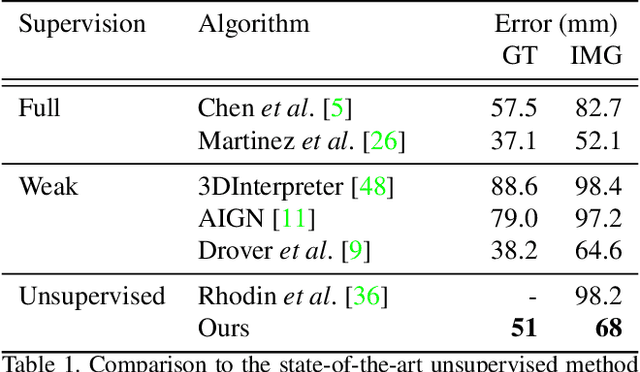
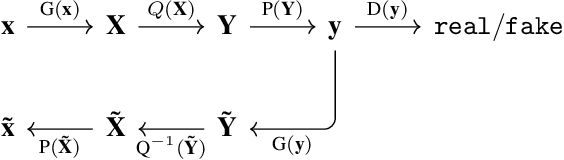
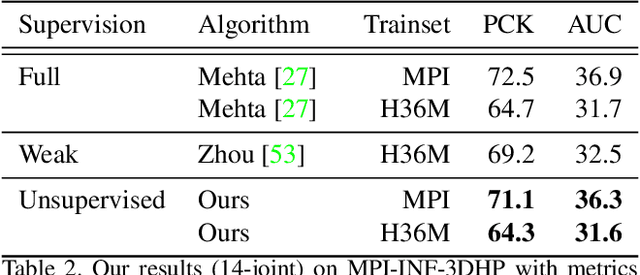
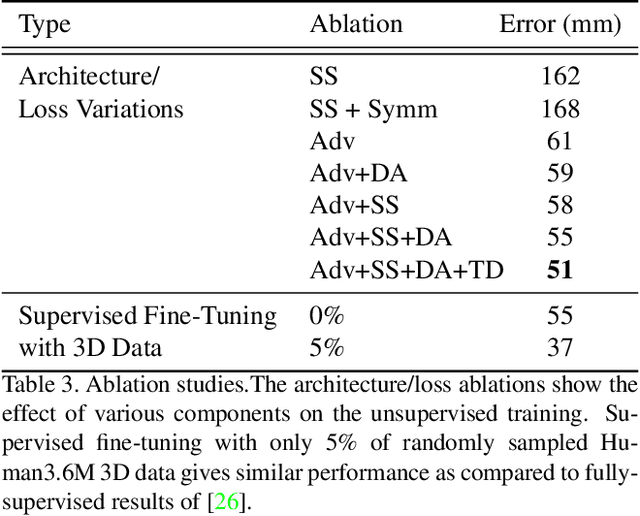
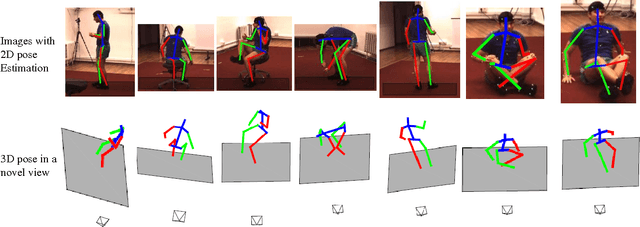
We present an unsupervised learning approach to recover 3D human pose from 2D skeletal joints extracted from a single image. Our method does not require any multi-view image data, 3D skeletons, correspondences between 2D-3D points, or use previously learned 3D priors during training. A lifting network accepts 2D landmarks as inputs and generates a corresponding 3D skeleton estimate. During training, the recovered 3D skeleton is reprojected on random camera viewpoints to generate new "synthetic" 2D poses. By lifting the synthetic 2D poses back to 3D and re-projecting them in the original camera view, we can define self-consistency loss both in 3D and in 2D. The training can thus be self supervised by exploiting the geometric self-consistency of the lift-reproject-lift process. We show that self-consistency alone is not sufficient to generate realistic skeletons, however adding a 2D pose discriminator enables the lifter to output valid 3D poses. Additionally, to learn from 2D poses "in the wild", we train an unsupervised 2D domain adapter network to allow for an expansion of 2D data. This improves results and demonstrates the usefulness of 2D pose data for unsupervised 3D lifting. Results on Human3.6M dataset for 3D human pose estimation demonstrate that our approach improves upon the previous unsupervised methods by 30% and outperforms many weakly supervised approaches that explicitly use 3D data.
Can 3D Pose be Learned from 2D Projections Alone?
Aug 22, 2018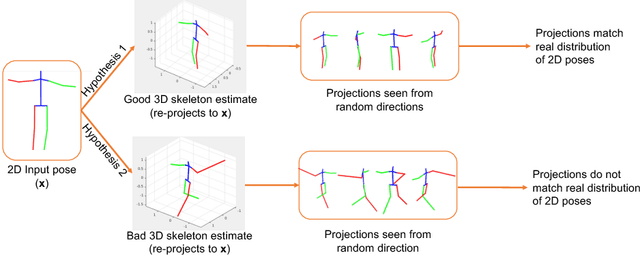
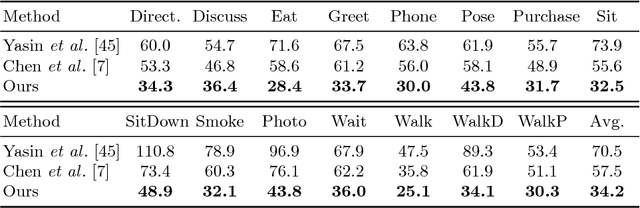
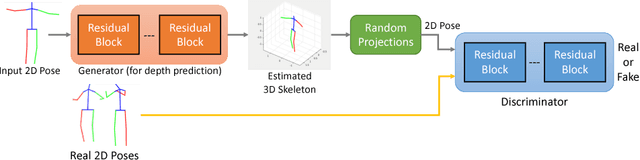
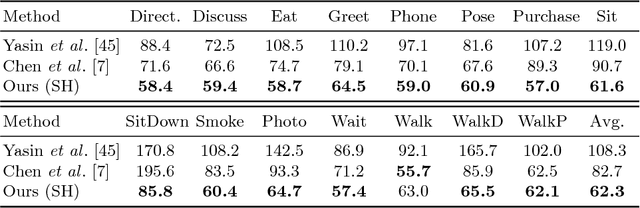
3D pose estimation from a single image is a challenging task in computer vision. We present a weakly supervised approach to estimate 3D pose points, given only 2D pose landmarks. Our method does not require correspondences between 2D and 3D points to build explicit 3D priors. We utilize an adversarial framework to impose a prior on the 3D structure, learned solely from their random 2D projections. Given a set of 2D pose landmarks, the generator network hypothesizes their depths to obtain a 3D skeleton. We propose a novel Random Projection layer, which randomly projects the generated 3D skeleton and sends the resulting 2D pose to the discriminator. The discriminator improves by discriminating between the generated poses and pose samples from a real distribution of 2D poses. Training does not require correspondence between the 2D inputs to either the generator or the discriminator. We apply our approach to the task of 3D human pose estimation. Results on Human3.6M dataset demonstrates that our approach outperforms many previous supervised and weakly supervised approaches.
Hierarchical Cross Network for Person Re-identification
Dec 19, 2017

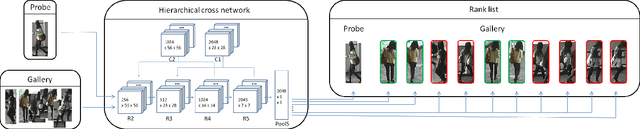
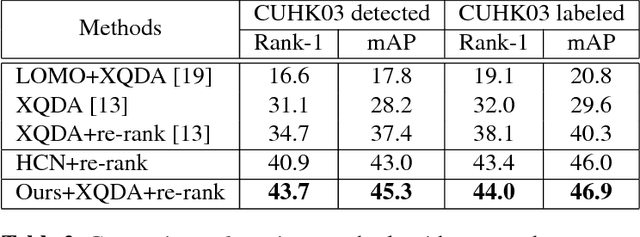
Person re-identification (person re-ID) aims at matching target person(s) grabbed from different and non-overlapping camera views. It plays an important role for public safety and has application in various tasks such as, human retrieval, human tracking, and activity analysis. In this paper, we propose a new network architecture called Hierarchical Cross Network (HCN) to perform person re-ID. In addition to the backbone model of a conventional CNN, HCN is equipped with two additional maps called hierarchical cross feature maps. The maps of an HCN are formed by merging layers with different resolutions and semantic levels. With the hierarchical cross feature maps, an HCN can effectively uncover additional semantic features which could not be discovered by a conventional CNN. Although the proposed HCN can discover features with higher semantics, its representation power is still limited. To derive more general representations, we augment the data during the training process by combining multiple datasets. Experiment results show that the proposed method outperformed several state-of-the-art methods.
3D Human Pose Estimation = 2D Pose Estimation + Matching
Apr 11, 2017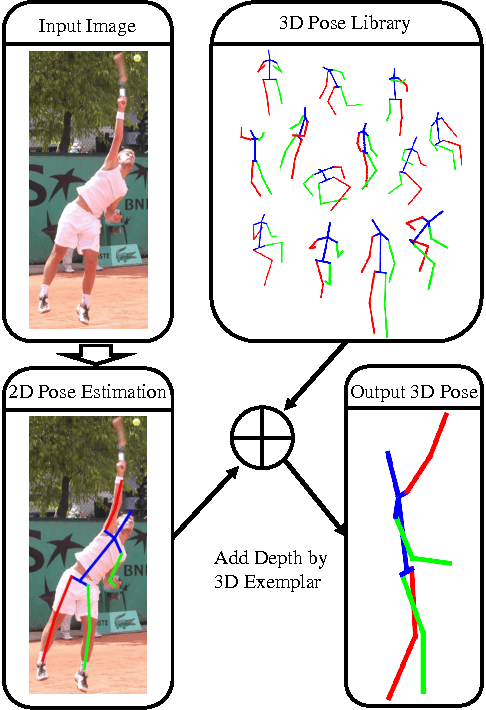
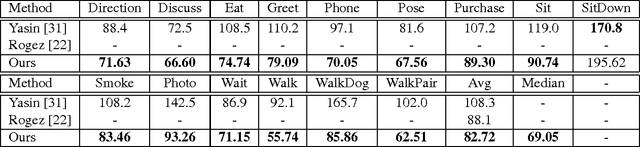

We explore 3D human pose estimation from a single RGB image. While many approaches try to directly predict 3D pose from image measurements, we explore a simple architecture that reasons through intermediate 2D pose predictions. Our approach is based on two key observations (1) Deep neural nets have revolutionized 2D pose estimation, producing accurate 2D predictions even for poses with self occlusions. (2) Big-data sets of 3D mocap data are now readily available, making it tempting to lift predicted 2D poses to 3D through simple memorization (e.g., nearest neighbors). The resulting architecture is trivial to implement with off-the-shelf 2D pose estimation systems and 3D mocap libraries. Importantly, we demonstrate that such methods outperform almost all state-of-the-art 3D pose estimation systems, most of which directly try to regress 3D pose from 2D measurements.