 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRTUE: Versatile Video Retrieval Through Unified Embeddings
Jan 17, 2026Modern video retrieval systems are expected to handle diverse tasks ranging from corpus-level retrieval and fine-grained moment localization to flexible multimodal querying. Specialized architectures achieve strong retrieval performance by training modality-specific encoders on massive datasets, but they lack the ability to process composed multimodal queries. In contrast, multimodal LLM (MLLM)-based methods support rich multimodal search but their retrieval performance remains well below that of specialized systems. We present VIRTUE, an MLLM-based versatile video retrieval framework that integrates corpus and moment-level retrieval capabilities while accommodating composed multimodal queries within a single architecture. We use contrastive alignment of visual and textual embeddings generated using a shared MLLM backbone to facilitate efficient embedding-based candidate search. Our embedding model, trained efficiently using low-rank adaptation (LoRA) on 700K paired visual-text data samples, surpasses other MLLM-based methods on zero-shot video retrieval tasks. Additionally, we demonstrate that the same model can be adapted without further training to achieve competitive results on zero-shot moment retrieval, and state of the art results for zero-shot composed video retrieval. With additional training for reranking candidates identified in the embedding-based search, our model substantially outperforms existing MLLM-based retrieval systems and achieves retrieval performance comparable to state of the art specialized models which are trained on orders of magnitude larger data.
What Happens Next? Next Scene Prediction with a Unified Video Model
Dec 15, 2025



Recent unified models for joint understanding and generation have significantly advanced visual generation capabilities. However, their focus on conventional tasks like text-to-video generation has left the temporal reasoning potential of unified models largely underexplored. To address this gap, we introduce Next Scene Prediction (NSP), a new task that pushes unified video models toward temporal and causal reasoning. Unlike text-to-video generation, NSP requires predicting plausible futures from preceding context, demanding deeper understanding and reasoning. To tackle this task, we propose a unified framework combining Qwen-VL for comprehension and LTX for synthesis, bridged by a latent query embedding and a connector module. This model is trained in three stages on our newly curated, large-scale NSP dataset: text-to-video pre-training, supervised fine-tuning, and reinforcement learning (via GRPO) with our proposed causal consistency reward. Experiments demonstrate our model achieves state-of-the-art performance on our benchmark, advancing the capability of generalist multimodal systems to anticipate what happens next.
VoiceCraft-X: Unifying Multilingual, Voice-Cloning Speech Synthesis and Speech Editing
Nov 15, 2025We introduce VoiceCraft-X, an autoregressive neural codec language model which unifies multilingual speech editing and zero-shot Text-to-Speech (TTS) synthesis across 11 languages: English, Mandarin, Korean, Japanese, Spanish, French, German, Dutch, Italian, Portuguese, and Polish. VoiceCraft-X utilizes the Qwen3 large language model for phoneme-free cross-lingual text processing and a novel token reordering mechanism with time-aligned text and speech tokens to handle both tasks as a single sequence generation problem. The model generates high-quality, natural-sounding speech, seamlessly creating new audio or editing existing recordings within one framework. VoiceCraft-X shows robust performance in diverse linguistic settings, even with limited per-language data, underscoring the power of unified autoregressive approaches for advancing complex, real-world multilingual speech applications. Audio samples are available at https://zhishengzheng.com/voicecraft-x/.
RefTok: Reference-Based Tokenization for Video Generation
Jul 03, 2025Effectively handling temporal redundancy remains a key challenge in learning video models. Prevailing approaches often treat each set of frames independently, failing to effectively capture the temporal dependencies and redundancies inherent in videos. To address this limitation, we introduce RefTok, a novel reference-based tokenization method capable of capturing complex temporal dynamics and contextual information. Our method encodes and decodes sets of frames conditioned on an unquantized reference frame. When decoded, RefTok preserves the continuity of motion and the appearance of objects across frames. For example, RefTok retains facial details despite head motion, reconstructs text correctly, preserves small patterns, and maintains the legibility of handwriting from the context. Across 4 video datasets (K600, UCF-101, BAIR Robot Pushing, and DAVIS), RefTok significantly outperforms current state-of-the-art tokenizers (Cosmos and MAGVIT) and improves all evaluated metrics (PSNR, SSIM, LPIPS) by an average of 36.7% at the same or higher compression ratios. When a video generation model is trained using RefTok's latents on the BAIR Robot Pushing task, the generations not only outperform MAGVIT-B but the larger MAGVIT-L, which has 4x more parameters, across all generation metrics by an average of 27.9%.
CRPO: Confidence-Reward Driven Preference Optimization for Machine Translation
Jan 23, 2025



Large language models (LLMs) have shown great potential in natural language processing tasks, but their application to machine translation (MT) remains challenging due to pretraining on English-centric data and the complexity of reinforcement learning from human feedback (RLHF). Direct Preference Optimization (DPO) has emerged as a simpler and more efficient alternative, but its performance depends heavily on the quality of preference data. To address this, we propose Confidence-Reward driven Preference Optimization (CRPO), a novel method that combines reward scores with model confidence to improve data selection for fine-tuning. CRPO selects challenging sentence pairs where the model is uncertain or underperforms, leading to more effective learning. While primarily designed for LLMs, CRPO also generalizes to encoder-decoder models like NLLB, demonstrating its versatility. Empirical results show that CRPO outperforms existing methods such as RS-DPO, RSO and MBR score in both translation accuracy and data efficiency.
Beyond Speaker Identity: Text Guided Target Speech Extraction
Jan 15, 2025Target Speech Extraction (TSE) traditionally relies on explicit clues about the speaker's identity like enrollment audio, face images, or videos, which may not always be available. In this paper, we propose a text-guided TSE model StyleTSE that uses natural language descriptions of speaking style in addition to the audio clue to extract the desired speech from a given mixture. Our model integrates a speech separation network adapted from SepFormer with a bi-modality clue network that flexibly processes both audio and text clues. To train and evaluate our model, we introduce a new dataset TextrolMix with speech mixtures and natural language descriptions. Experimental results demonstrate that our method effectively separates speech based not only on who is speaking, but also on how they are speaking, enhancing TSE in scenarios where traditional audio clues are absent. Demos are at: https://mingyue66.github.io/TextrolMix/demo/
NowYouSee Me: Context-Aware Automatic Audio Description
Dec 13, 2024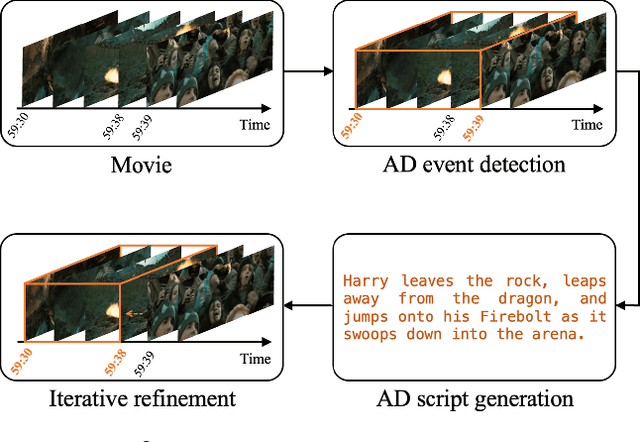
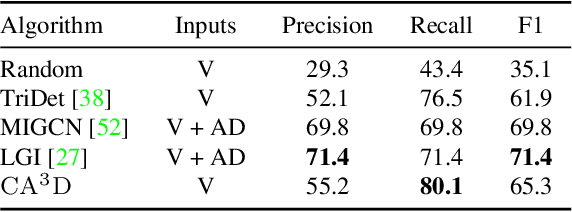
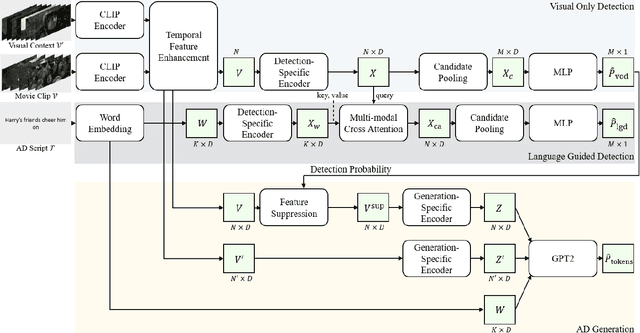

Audio Description (AD) plays a pivotal role as an application system aimed at guaranteeing accessibility in multimedia content, which provides additional narrations at suitable intervals to describe visual elements, catering specifically to the needs of visually impaired audiences. In this paper, we introduce $\mathrm{CA^3D}$, the pioneering unified Context-Aware Automatic Audio Description system that provides AD event scripts with precise locations in the long cinematic content. Specifically, $\mathrm{CA^3D}$ system consists of: 1) a Temporal Feature Enhancement Module to efficiently capture longer term dependencies, 2) an anchor-based AD event detector with feature suppression module that localizes the AD events and extracts discriminative feature for AD generation, and 3) a self-refinement module that leverages the generated output to tweak AD event boundaries from coarse to fine. Unlike conventional methods which rely on metadata and ground truth AD timestamp for AD detection and generation tasks, the proposed $\mathrm{CA^3D}$ is the first end-to-end trainable system that only uses visual cue. Extensive experiments demonstrate that the proposed $\mathrm{CA^3D}$ improves existing architectures for both AD event detection and script generation metrics, establishing the new state-of-the-art performances in the AD automation.
* 10 pages
GEXIA: Granularity Expansion and Iterative Approximation for Scalable Multi-grained Video-language Learning
Dec 10, 2024
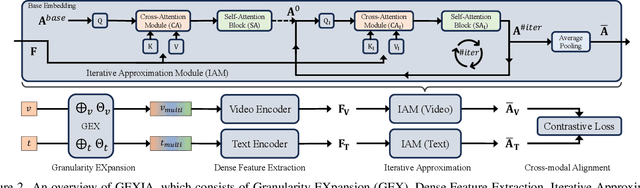
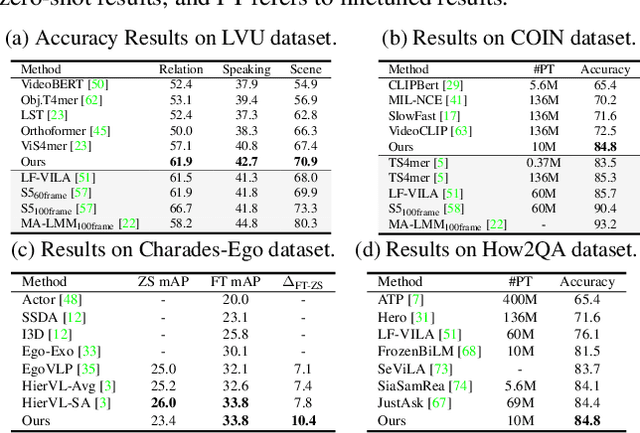
In various video-language learning tasks, the challenge of achieving cross-modality alignment with multi-grained data persists. We propose a method to tackle this challenge from two crucial perspectives: data and modeling. Given the absence of a multi-grained video-text pretraining dataset, we introduce a Granularity EXpansion (GEX) method with Integration and Compression operations to expand the granularity of a single-grained dataset. To better model multi-grained data, we introduce an Iterative Approximation Module (IAM), which embeds multi-grained videos and texts into a unified, low-dimensional semantic space while preserving essential information for cross-modal alignment. Furthermore, GEXIA is highly scalable with no restrictions on the number of video-text granularities for alignment. We evaluate our work on three categories of video tasks across seven benchmark datasets, showcasing state-of-the-art or comparable performance. Remarkably, our model excels in tasks involving long-form video understanding, even though the pretraining dataset only contains short video clips.
DiffSign: AI-Assisted Generation of Customizable Sign Language Videos With Enhanced Realism
Dec 05, 2024



The proliferation of several streaming services in recent years has now made it possible for a diverse audience across the world to view the same media content, such as movies or TV shows. While translation and dubbing services are being added to make content accessible to the local audience, the support for making content accessible to people with different abilities, such as the Deaf and Hard of Hearing (DHH) community, is still lagging. Our goal is to make media content more accessible to the DHH community by generating sign language videos with synthetic signers that are realistic and expressive. Using the same signer for a given media content that is viewed globally may have limited appeal. Hence, our approach combines parametric modeling and generative modeling to generate realistic-looking synthetic signers and customize their appearance based on user preferences. We first retarget human sign language poses to 3D sign language avatars by optimizing a parametric model. The high-fidelity poses from the rendered avatars are then used to condition the poses of synthetic signers generated using a diffusion-based generative model. The appearance of the synthetic signer is controlled by an image prompt supplied through a visual adapter. Our results show that the sign language videos generated using our approach have better temporal consistency and realism than signing videos generated by a diffusion model conditioned only on text prompts. We also support multimodal prompts to allow users to further customize the appearance of the signer to accommodate diversity (e.g. skin tone, gender). Our approach is also useful for signer anonymization.
Text-Guided Video Masked Autoencoder
Aug 01, 2024



Recent video masked autoencoder (MAE) works have designed improved masking algorithms focused on saliency. These works leverage visual cues such as motion to mask the most salient regions. However, the robustness of such visual cues depends on how often input videos match underlying assumptions. On the other hand, natural language description is an information dense representation of video that implicitly captures saliency without requiring modality-specific assumptions, and has not been explored yet for video MAE. To this end, we introduce a novel text-guided masking algorithm (TGM) that masks the video regions with highest correspondence to paired captions. Without leveraging any explicit visual cues for saliency, our TGM is competitive with state-of-the-art masking algorithms such as motion-guided masking. To further benefit from the semantics of natural language for masked reconstruction, we next introduce a unified framework for joint MAE and masked video-text contrastive learning. We show that across existing masking algorithms, unifying MAE and masked video-text contrastive learning improves downstream performance compared to pure MAE on a variety of video recognition tasks, especially for linear probe. Within this unified framework, our TGM achieves the best relative performance on five action recognition and one egocentric datasets, highlighting the complementary nature of natural language for masked video modeling.