 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGA: Multimodal Alignment Aggregation and Distillation For Cinematic Video Segmentation
Aug 22, 2023



Previous research has studied the task of segmenting cinematic videos into scenes and into narrative acts. However, these studies have overlooked the essential task of multimodal alignment and fusion for effectively and efficiently processing long-form videos (>60min). In this paper, we introduce Multimodal alignmEnt aGgregation and distillAtion (MEGA) for cinematic long-video segmentation. MEGA tackles the challenge by leveraging multiple media modalities. The method coarsely aligns inputs of variable lengths and different modalities with alignment positional encoding. To maintain temporal synchronization while reducing computation, we further introduce an enhanced bottleneck fusion layer which uses temporal alignment. Additionally, MEGA employs a novel contrastive loss to synchronize and transfer labels across modalities, enabling act segmentation from labeled synopsis sentences on video shots. Our experimental results show that MEGA outperforms state-of-the-art methods on MovieNet dataset for scene segmentation (with an Average Precision improvement of +1.19%) and on TRIPOD dataset for act segmentation (with a Total Agreement improvement of +5.51%)
A Report on the 2020 Sarcasm Detection Shared Task
Jun 04, 2020

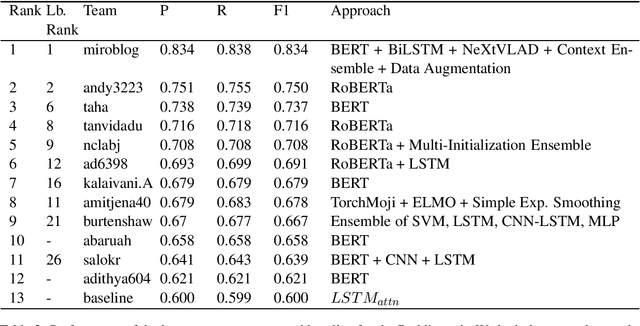
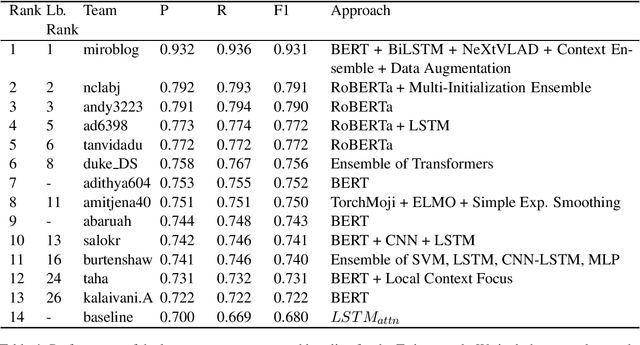
Detecting sarcasm and verbal irony is critical for understanding people's actual sentiments and beliefs. Thus, the field of sarcasm analysis has become a popular research problem in natural language processing. As the community working on computational approaches for sarcasm detection is growing, it is imperative to conduct benchmarking studies to analyze the current state-of-the-art, facilitating progress in this area. We report on the shared task on sarcasm detection we conducted as a part of the 2nd Workshop on Figurative Language Processing (FigLang 2020) at ACL 2020.
An Unsupervised Approach for Mapping between Vector Spaces
Nov 20, 2017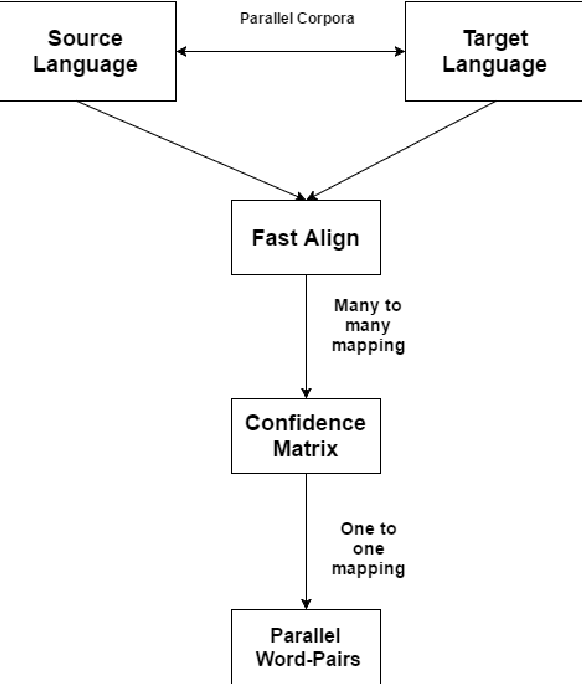
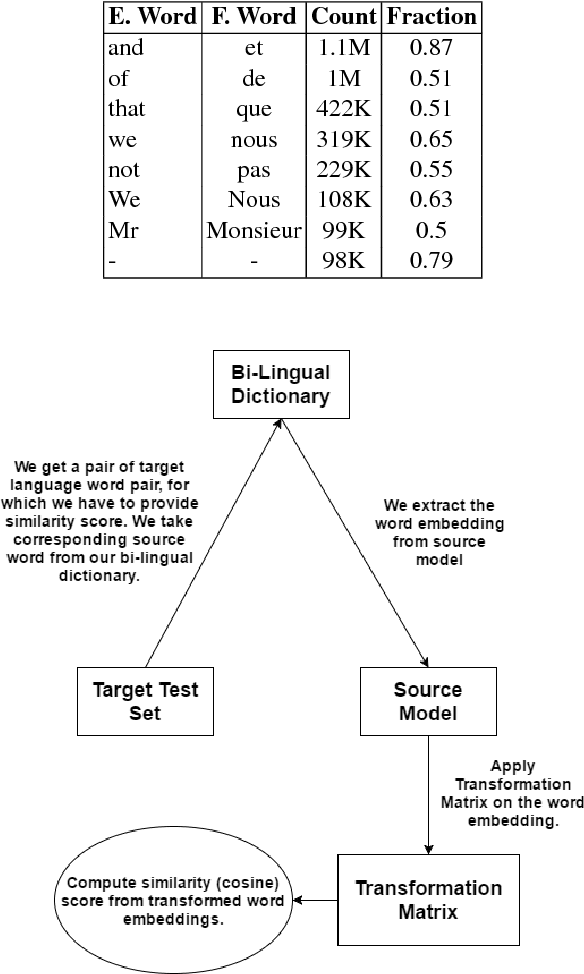

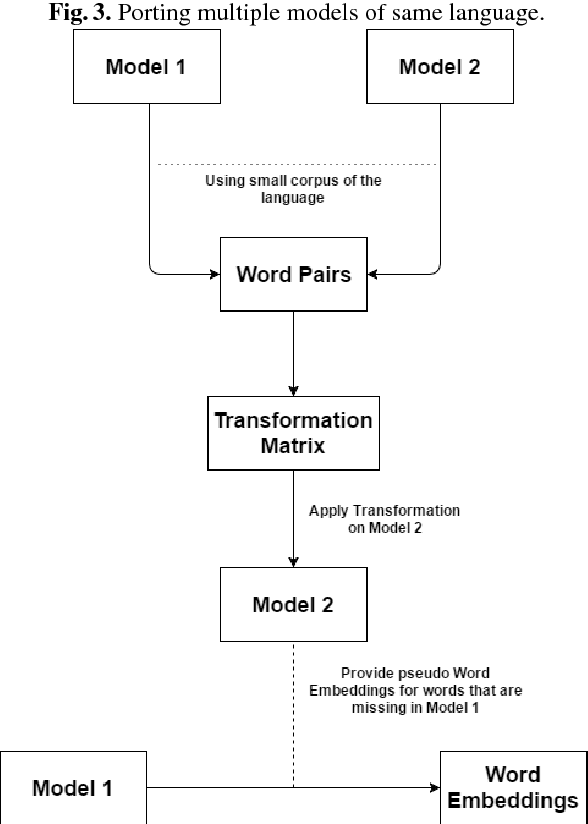
We present a language independent, unsupervised approach for transforming word embeddings from source language to target language using a transformation matrix. Our model handles the problem of data scarcity which is faced by many languages in the world and yields improved word embeddings for words in the target language by relying on transformed embeddings of words of the source language. We initially evaluate our approach via word similarity tasks on a similar language pair - Hindi as source and Urdu as the target language, while we also evaluate our method on French and German as target languages and English as source language. Our approach improves the current state of the art results - by 13% for French and 19% for German. For Urdu, we saw an increment of 16% over our initial baseline score. We further explore the prospects of our approach by applying it on multiple models of the same language and transferring words between the two models, thus solving the problem of missing words in a model. We evaluate this on word similarity and word analogy tasks.
Unsupervised Morphological Expansion of Small Datasets for Improving Word Embeddings
Nov 15, 2017


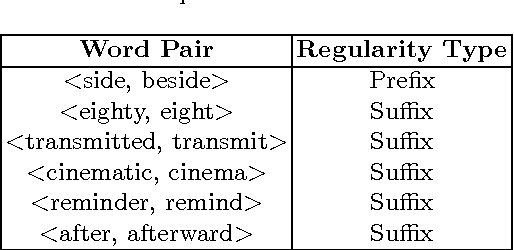
We present a language independent, unsupervised method for building word embeddings using morphological expansion of text. Our model handles the problem of data sparsity and yields improved word embeddings by relying on training word embeddings on artificially generated sentences. We evaluate our method using small sized training sets on eleven test sets for the word similarity task across seven languages. Further, for English, we evaluated the impacts of our approach using a large training set on three standard test sets. Our method improved results across all languages.