 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Unsupervised Approach for Mapping between Vector Spaces
Nov 20, 2017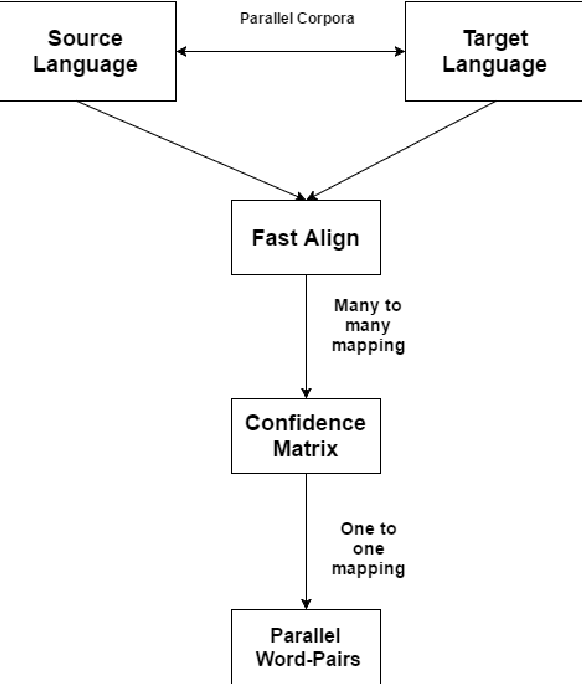
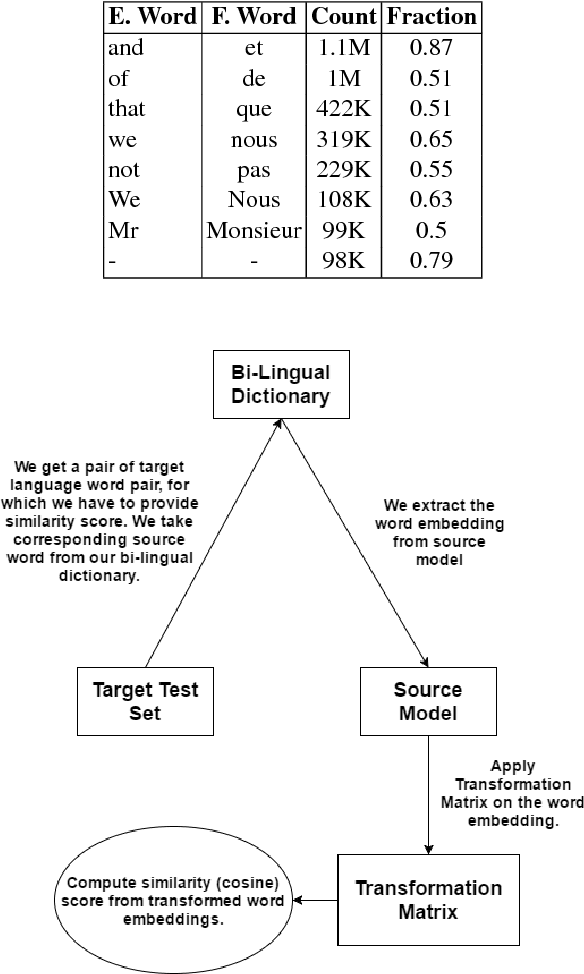

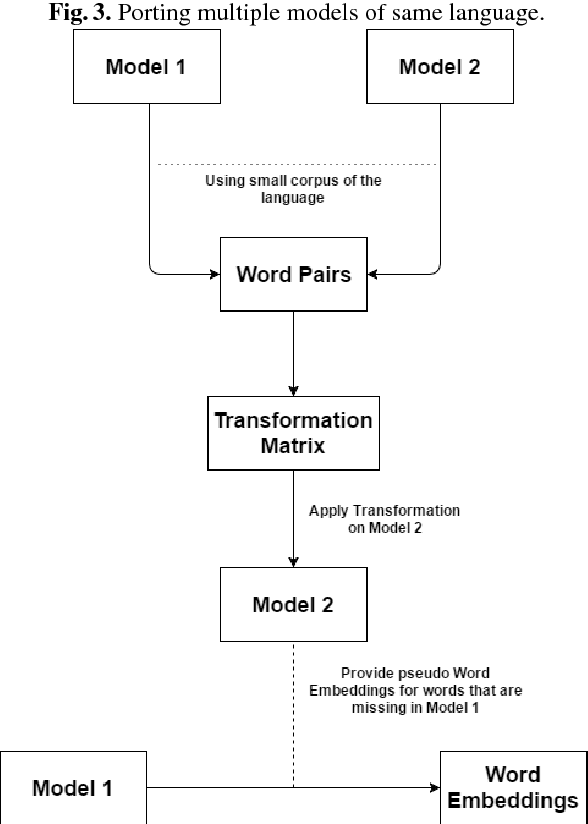
We present a language independent, unsupervised approach for transforming word embeddings from source language to target language using a transformation matrix. Our model handles the problem of data scarcity which is faced by many languages in the world and yields improved word embeddings for words in the target language by relying on transformed embeddings of words of the source language. We initially evaluate our approach via word similarity tasks on a similar language pair - Hindi as source and Urdu as the target language, while we also evaluate our method on French and German as target languages and English as source language. Our approach improves the current state of the art results - by 13% for French and 19% for German. For Urdu, we saw an increment of 16% over our initial baseline score. We further explore the prospects of our approach by applying it on multiple models of the same language and transferring words between the two models, thus solving the problem of missing words in a model. We evaluate this on word similarity and word analogy tasks.
Unsupervised Morphological Expansion of Small Datasets for Improving Word Embeddings
Nov 15, 2017


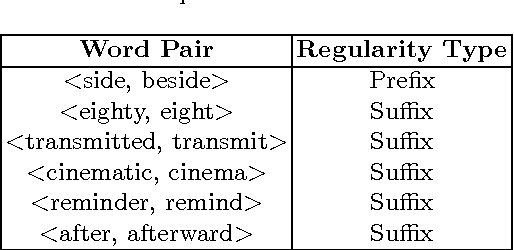
We present a language independent, unsupervised method for building word embeddings using morphological expansion of text. Our model handles the problem of data sparsity and yields improved word embeddings by relying on training word embeddings on artificially generated sentences. We evaluate our method using small sized training sets on eleven test sets for the word similarity task across seven languages. Further, for English, we evaluated the impacts of our approach using a large training set on three standard test sets. Our method improved results across all languages.