 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Help for Task Completion and Feature Discovery in Personal Assistants
Jul 16, 2019
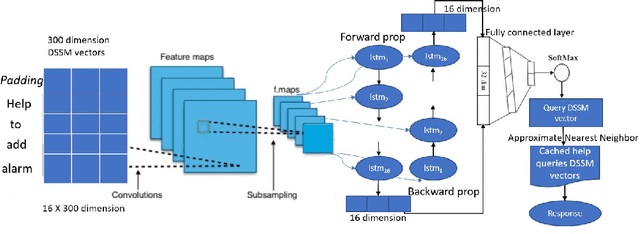
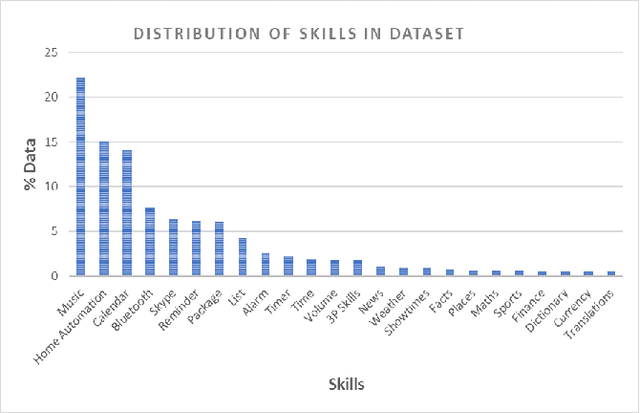
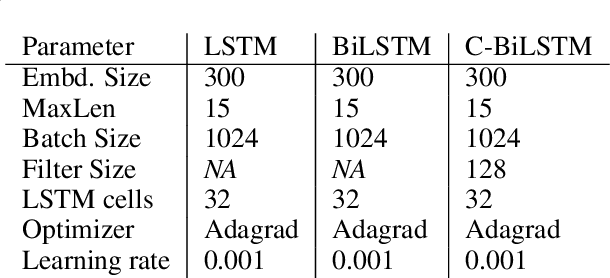
Intelligent Personal Assistants (IPAs) have become widely popular in recent times. Most of the commercial IPAs today support a wide range of skills including Alarms, Reminders, Weather Updates, Music, News, Factual Questioning-Answering, etc. The list grows every day, making it difficult to remember the command structures needed to execute various tasks. An IPA must have the ability to communicate information about supported skills and direct users towards the right commands needed to execute them. Users interact with personal assistants in natural language. A query is defined to be a Help Query if it seeks information about a personal assistant's capabilities, or asks for instructions to execute a task. In this paper, we propose an interactive system which identifies help queries and retrieves appropriate responses. Our system comprises of a C-BiLSTM based classifier, which is a fusion of Convolutional Neural Networks (CNN) and Bidirectional LSTM (BiLSTM) architectures, to detect help queries and a semantic Approximate Nearest Neighbours (ANN) module to map the query to an appropriate predefined response. Evaluation of our system on real-world queries from a commercial IPA and a detailed comparison with popular traditional machine learning and deep learning based models reveal that our system outperforms other approaches and returns relevant responses for help queries.
An Unsupervised Approach for Mapping between Vector Spaces
Nov 20, 2017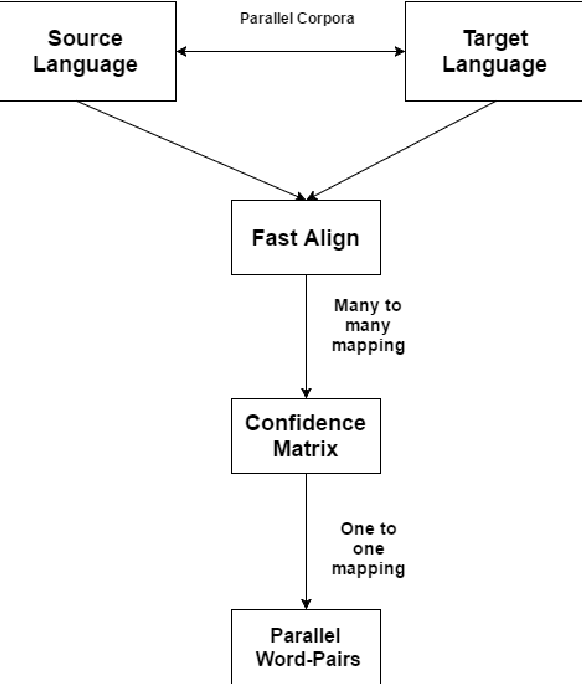
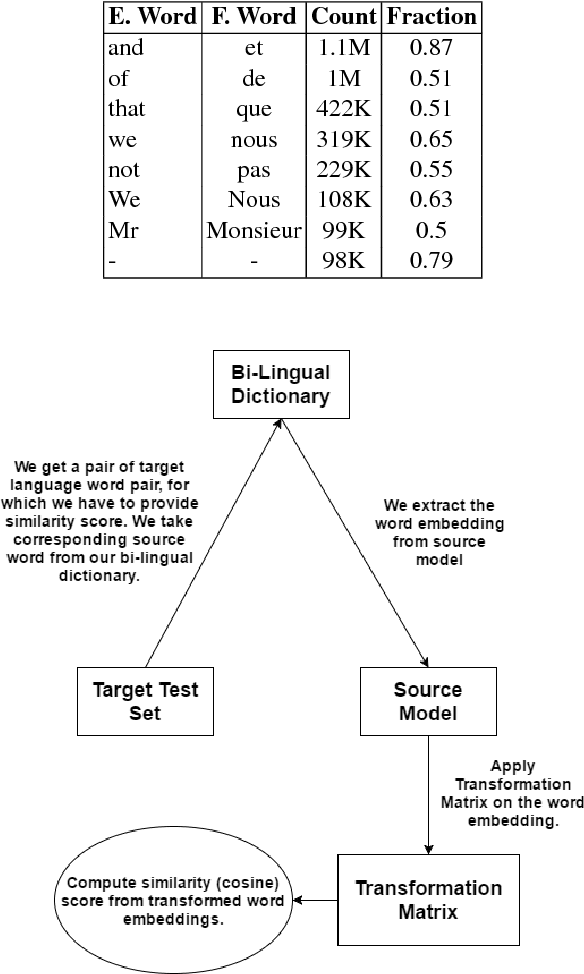

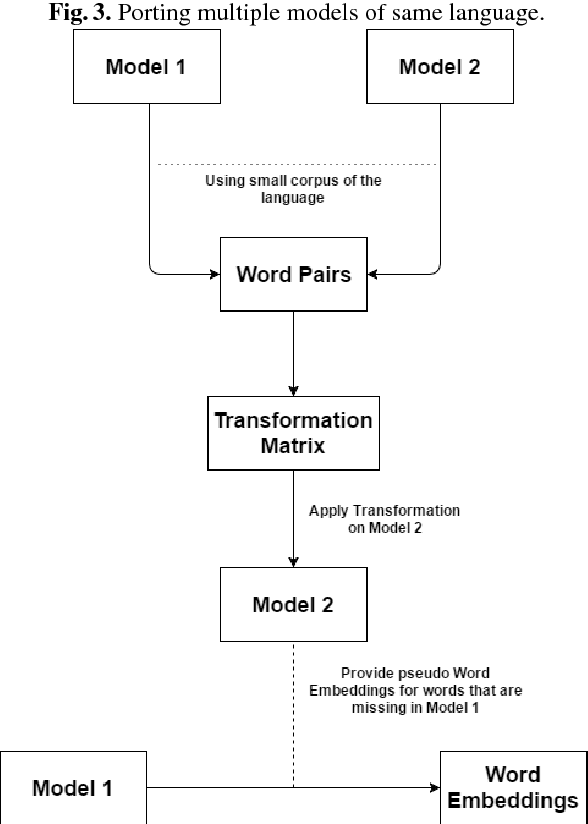
We present a language independent, unsupervised approach for transforming word embeddings from source language to target language using a transformation matrix. Our model handles the problem of data scarcity which is faced by many languages in the world and yields improved word embeddings for words in the target language by relying on transformed embeddings of words of the source language. We initially evaluate our approach via word similarity tasks on a similar language pair - Hindi as source and Urdu as the target language, while we also evaluate our method on French and German as target languages and English as source language. Our approach improves the current state of the art results - by 13% for French and 19% for German. For Urdu, we saw an increment of 16% over our initial baseline score. We further explore the prospects of our approach by applying it on multiple models of the same language and transferring words between the two models, thus solving the problem of missing words in a model. We evaluate this on word similarity and word analogy tasks.