 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Prediction in English-Hindi Code-Mixed Social Media Content : Corpus and Baseline System
Jun 14, 2018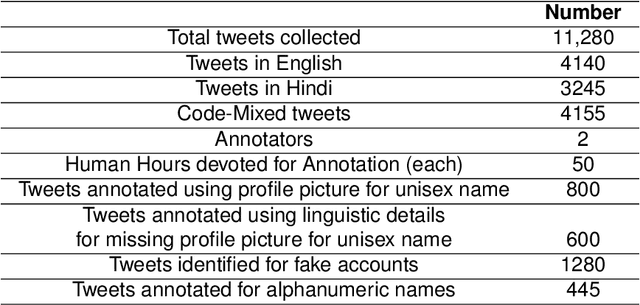

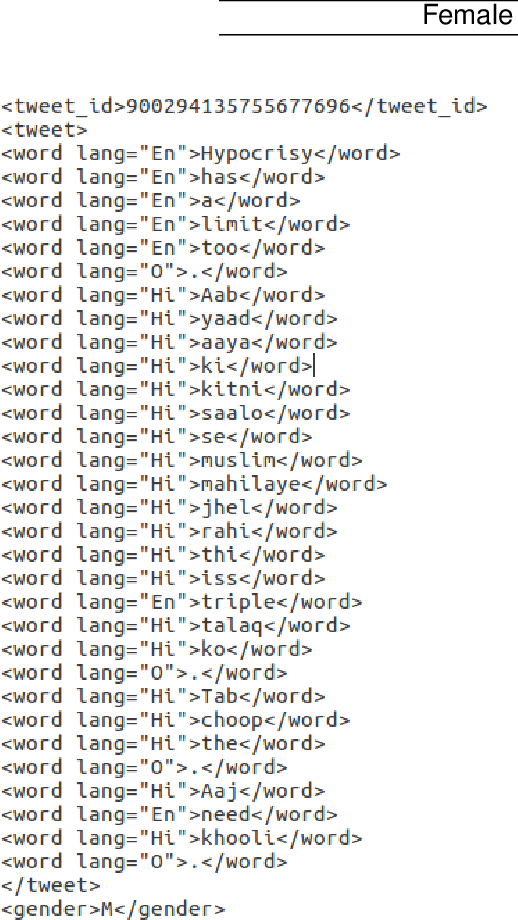

The rapid expansion in the usage of social media networking sites leads to a huge amount of unprocessed user generated data which can be used for text mining. Author profiling is the problem of automatically determining profiling aspects like the author's gender and age group through a text is gaining much popularity in computational linguistics. Most of the past research in author profiling is concentrated on English texts \cite{1,2}. However many users often change the language while posting on social media which is called code-mixing, and it develops some challenges in the field of text classification and author profiling like variations in spelling, non-grammatical structure and transliteration \cite{3}. There are very few English-Hindi code-mixed annotated datasets of social media content present online \cite{4}. In this paper, we analyze the task of author's gender prediction in code-mixed content and present a corpus of English-Hindi texts collected from Twitter which is annotated with author's gender. We also explore language identification of every word in this corpus. We present a supervised classification baseline system which uses various machine learning algorithms to identify the gender of an author using a text, based on character and word level features.
A Corpus of English-Hindi Code-Mixed Tweets for Sarcasm Detection
May 30, 2018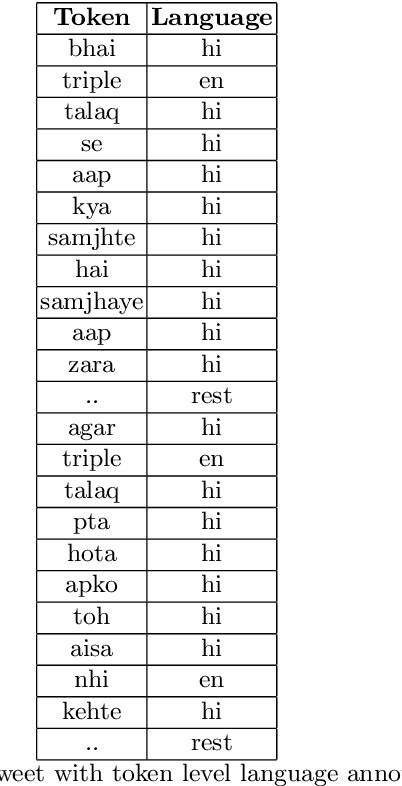
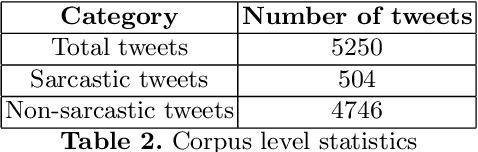
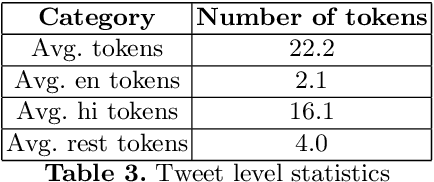

Social media platforms like twitter and facebook have be- come two of the largest mediums used by people to express their views to- wards different topics. Generation of such large user data has made NLP tasks like sentiment analysis and opinion mining much more important. Using sarcasm in texts on social media has become a popular trend lately. Using sarcasm reverses the meaning and polarity of what is implied by the text which poses challenge for many NLP tasks. The task of sarcasm detection in text is gaining more and more importance for both commer- cial and security services. We present the first English-Hindi code-mixed dataset of tweets marked for presence of sarcasm and irony where each token is also annotated with a language tag. We present a baseline su- pervised classification system developed using the same dataset which achieves an average F-score of 78.4 after using random forest classifier and performing 10-fold cross validation.
An English-Hindi Code-Mixed Corpus: Stance Annotation and Baseline System
May 30, 2018
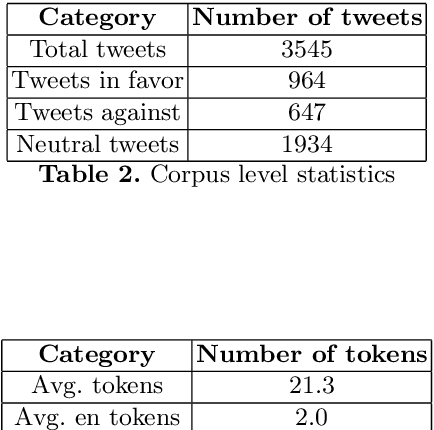
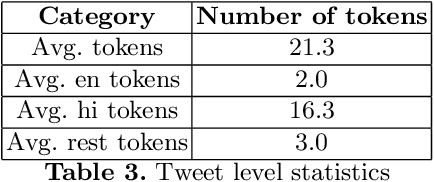

Social media has become one of the main channels for peo- ple to communicate and share their views with the society. We can often detect from these views whether the person is in favor, against or neu- tral towards a given topic. These opinions from social media are very useful for various companies. We present a new dataset that consists of 3545 English-Hindi code-mixed tweets with opinion towards Demoneti- sation that was implemented in India in 2016 which was followed by a large countrywide debate. We present a baseline supervised classification system for stance detection developed using the same dataset that uses various machine learning techniques to achieve an accuracy of 58.7% on 10-fold cross validation.
An Unsupervised Approach for Mapping between Vector Spaces
Nov 20, 2017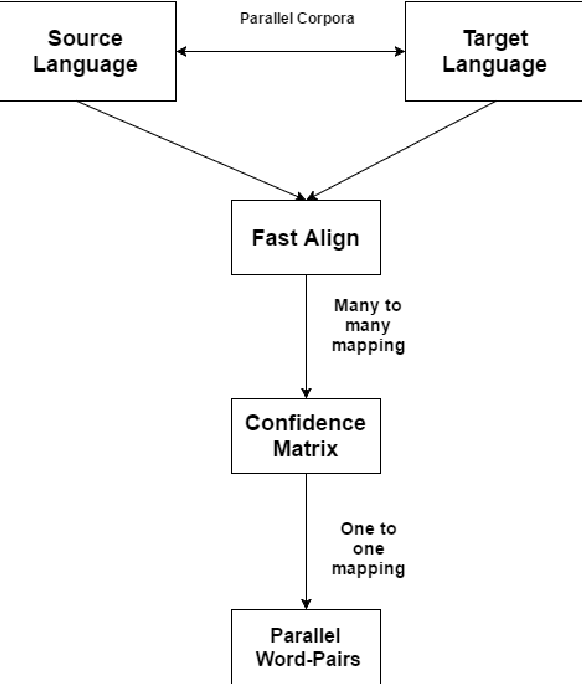
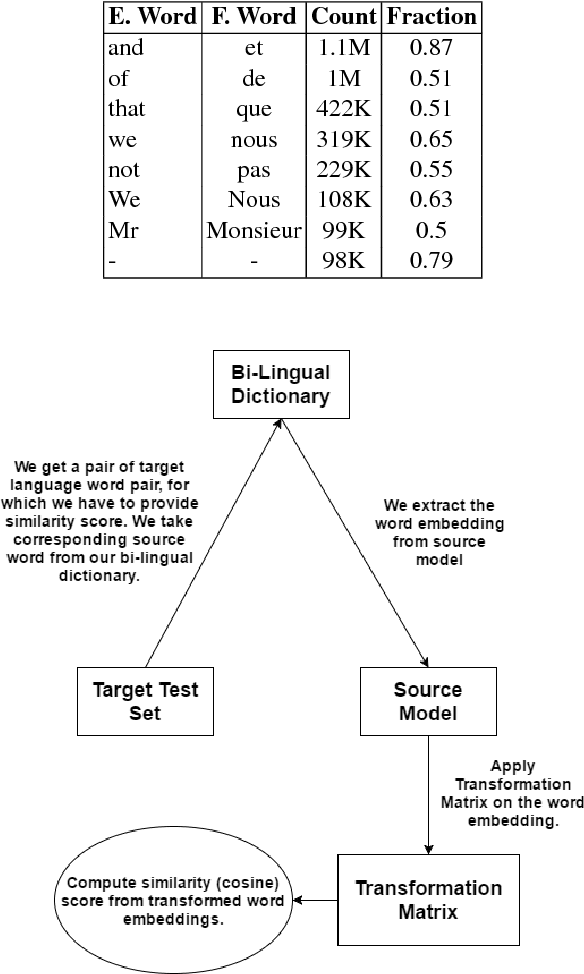

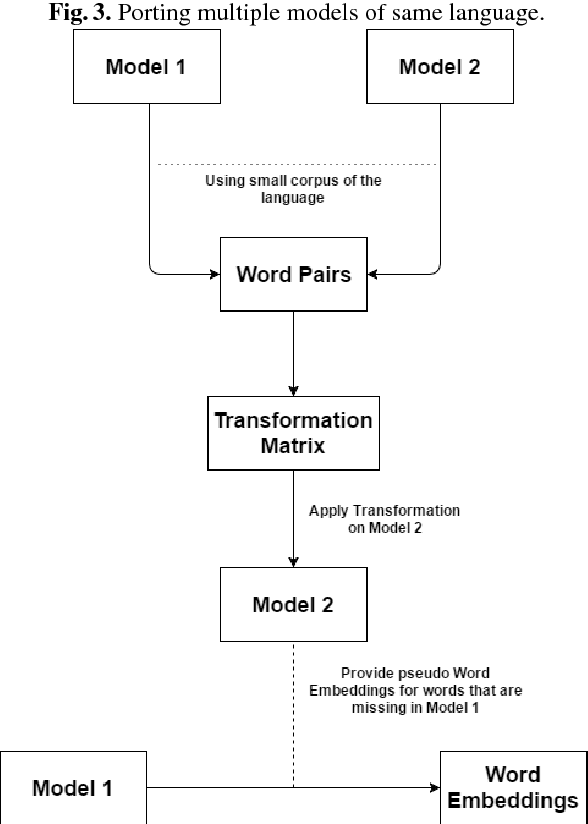
We present a language independent, unsupervised approach for transforming word embeddings from source language to target language using a transformation matrix. Our model handles the problem of data scarcity which is faced by many languages in the world and yields improved word embeddings for words in the target language by relying on transformed embeddings of words of the source language. We initially evaluate our approach via word similarity tasks on a similar language pair - Hindi as source and Urdu as the target language, while we also evaluate our method on French and German as target languages and English as source language. Our approach improves the current state of the art results - by 13% for French and 19% for German. For Urdu, we saw an increment of 16% over our initial baseline score. We further explore the prospects of our approach by applying it on multiple models of the same language and transferring words between the two models, thus solving the problem of missing words in a model. We evaluate this on word similarity and word analogy tasks.
Unsupervised Morphological Expansion of Small Datasets for Improving Word Embeddings
Nov 15, 2017


We present a language independent, unsupervised method for building word embeddings using morphological expansion of text. Our model handles the problem of data sparsity and yields improved word embeddings by relying on training word embeddings on artificially generated sentences. We evaluate our method using small sized training sets on eleven test sets for the word similarity task across seven languages. Further, for English, we evaluated the impacts of our approach using a large training set on three standard test sets. Our method improved results across all languages.