 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Prediction in English-Hindi Code-Mixed Social Media Content : Corpus and Baseline System
Jun 14, 2018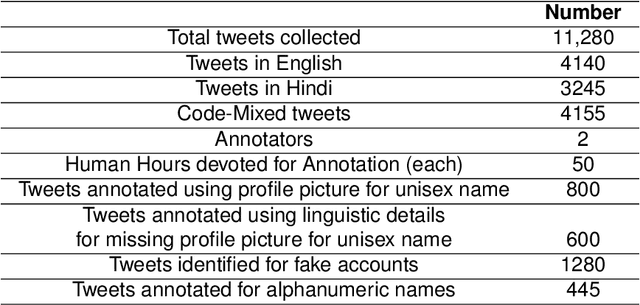


The rapid expansion in the usage of social media networking sites leads to a huge amount of unprocessed user generated data which can be used for text mining. Author profiling is the problem of automatically determining profiling aspects like the author's gender and age group through a text is gaining much popularity in computational linguistics. Most of the past research in author profiling is concentrated on English texts \cite{1,2}. However many users often change the language while posting on social media which is called code-mixing, and it develops some challenges in the field of text classification and author profiling like variations in spelling, non-grammatical structure and transliteration \cite{3}. There are very few English-Hindi code-mixed annotated datasets of social media content present online \cite{4}. In this paper, we analyze the task of author's gender prediction in code-mixed content and present a corpus of English-Hindi texts collected from Twitter which is annotated with author's gender. We also explore language identification of every word in this corpus. We present a supervised classification baseline system which uses various machine learning algorithms to identify the gender of an author using a text, based on character and word level features.
Humor Detection in English-Hindi Code-Mixed Social Media Content : Corpus and Baseline System
Jun 14, 2018


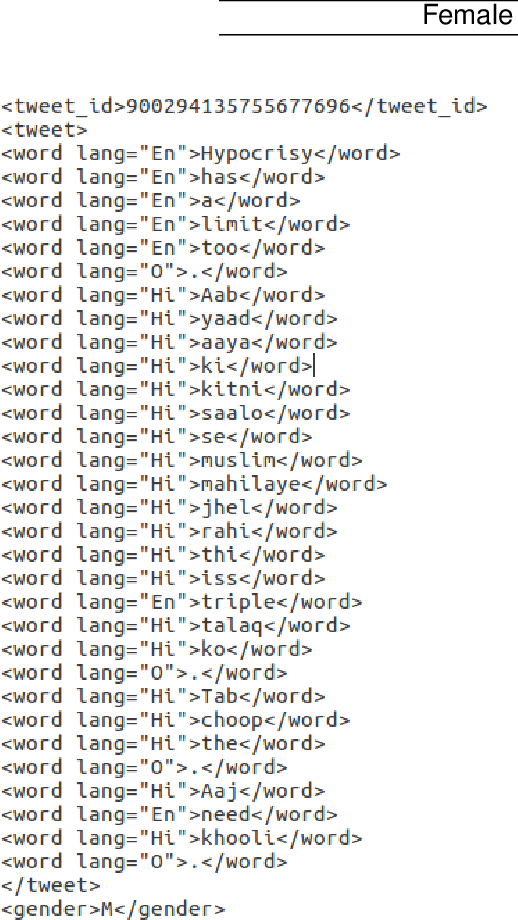
The tremendous amount of user generated data through social networking sites led to the gaining popularity of automatic text classification in the field of computational linguistics over the past decade. Within this domain, one problem that has drawn the attention of many researchers is automatic humor detection in texts. In depth semantic understanding of the text is required to detect humor which makes the problem difficult to automate. With increase in the number of social media users, many multilingual speakers often interchange between languages while posting on social media which is called code-mixing. It introduces some challenges in the field of linguistic analysis of social media content (Barman et al., 2014), like spelling variations and non-grammatical structures in a sentence. Past researches include detecting puns in texts (Kao et al., 2016) and humor in one-lines (Mihalcea et al., 2010) in a single language, but with the tremendous amount of code-mixed data available online, there is a need to develop techniques which detects humor in code-mixed tweets. In this paper, we analyze the task of humor detection in texts and describe a freely available corpus containing English-Hindi code-mixed tweets annotated with humorous(H) or non-humorous(N) tags. We also tagged the words in the tweets with Language tags (English/Hindi/Others). Moreover, we describe the experiments carried out on the corpus and provide a baseline classification system which distinguishes between humorous and non-humorous texts.
* 5 pages, 1 figure, LREC 2018
A Corpus of English-Hindi Code-Mixed Tweets for Sarcasm Detection
May 30, 2018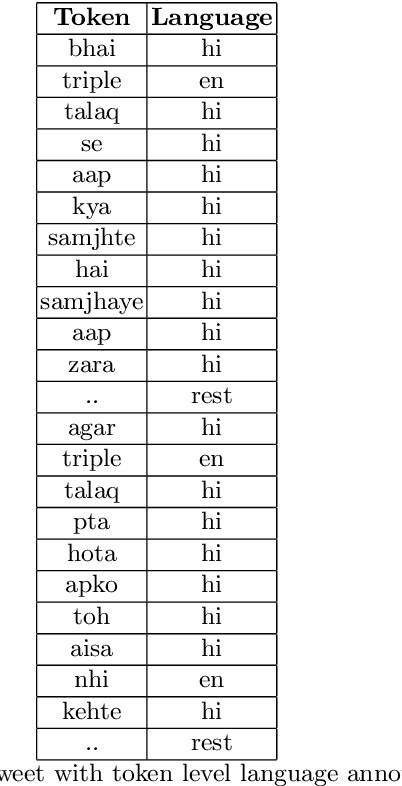
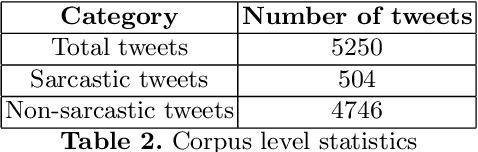
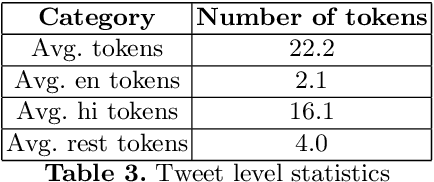

Social media platforms like twitter and facebook have be- come two of the largest mediums used by people to express their views to- wards different topics. Generation of such large user data has made NLP tasks like sentiment analysis and opinion mining much more important. Using sarcasm in texts on social media has become a popular trend lately. Using sarcasm reverses the meaning and polarity of what is implied by the text which poses challenge for many NLP tasks. The task of sarcasm detection in text is gaining more and more importance for both commer- cial and security services. We present the first English-Hindi code-mixed dataset of tweets marked for presence of sarcasm and irony where each token is also annotated with a language tag. We present a baseline su- pervised classification system developed using the same dataset which achieves an average F-score of 78.4 after using random forest classifier and performing 10-fold cross validation.
An English-Hindi Code-Mixed Corpus: Stance Annotation and Baseline System
May 30, 2018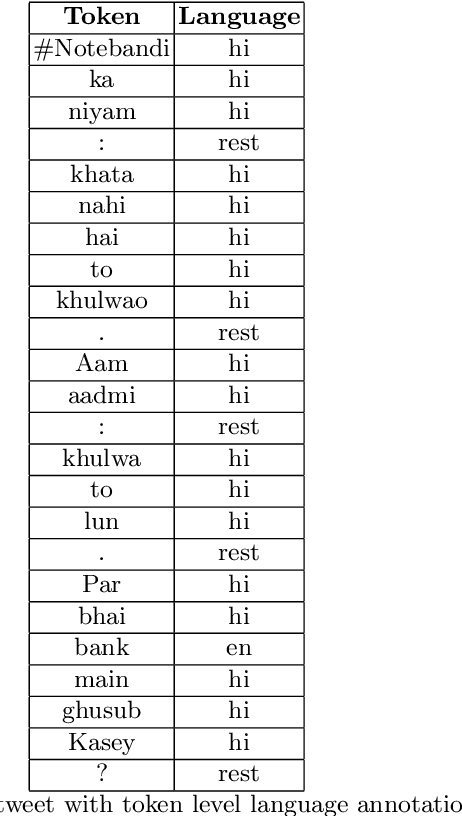
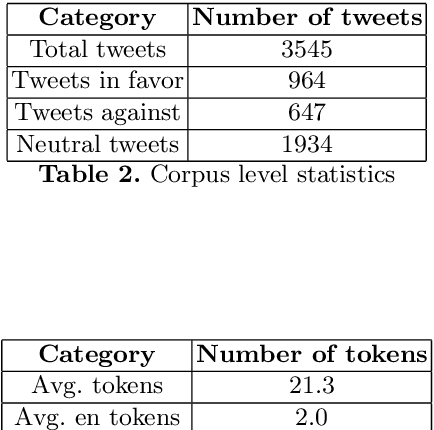
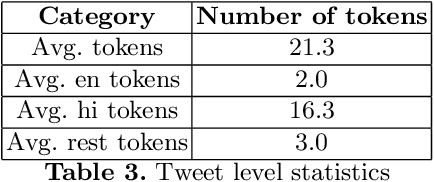

Social media has become one of the main channels for peo- ple to communicate and share their views with the society. We can often detect from these views whether the person is in favor, against or neu- tral towards a given topic. These opinions from social media are very useful for various companies. We present a new dataset that consists of 3545 English-Hindi code-mixed tweets with opinion towards Demoneti- sation that was implemented in India in 2016 which was followed by a large countrywide debate. We present a baseline supervised classification system for stance detection developed using the same dataset that uses various machine learning techniques to achieve an accuracy of 58.7% on 10-fold cross validation.