 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround4D: Spatially-Grounded Feedforward 4D Reconstruction for Unstructured Off-Road Scenes
May 06, 2026Feedforward Gaussian Splatting has recently emerged as an efficient paradigm for 4D reconstruction in autonomous driving. However, in unstructured off-road scenes, its performance degrades due to high-frequency geometry, ego-motion jitter, and increased non-rigid dynamics. These factors introduce conflicting Gaussian observations across timestamps, leading to either over-smoothed renderings or structural artifacts. To address this issue, we propose Ground4D, a spatially-grounded 4D feedforward framework for pose-free off-road reconstruction. The key idea is to resolve temporal conflicts through spatially localized conditioning. Specifically, we introduce voxel-grounded temporal Gaussian aggregation, which partitions the canonical Gaussian space into spatial voxels and performs query-conditioned temporal attention within each voxel. Intra-voxel softmax normalization ensures that temporal selectivity and spatial occupancy become mutually reinforcing rather than conflicting. We furthermore introduce surface normal cues as auxiliary geometric guidance to regularize the geometry of Gaussian primitives. Extensive experiments on ORAD-3D and RELLIS-3D demonstrate that Ground4D consistently outperforms existing feedforward methods in reconstruction quality and generalizes zero-shot to unseen off-road domains. Project page and code:https://github.com/wsnbws/Ground4D.
GenDet: Painting Colored Bounding Boxes on Images via Diffusion Model for Object Detection
Jan 12, 2026This paper presents GenDet, a novel framework that redefines object detection as an image generation task. In contrast to traditional approaches, GenDet adopts a pioneering approach by leveraging generative modeling: it conditions on the input image and directly generates bounding boxes with semantic annotations in the original image space. GenDet establishes a conditional generation architecture built upon the large-scale pre-trained Stable Diffusion model, formulating the detection task as semantic constraints within the latent space. It enables precise control over bounding box positions and category attributes, while preserving the flexibility of the generative model. This novel methodology effectively bridges the gap between generative models and discriminative tasks, providing a fresh perspective for constructing unified visual understanding systems. Systematic experiments demonstrate that GenDet achieves competitive accuracy compared to discriminative detectors, while retaining the flexibility characteristic of generative methods.
A Vision-Language-Action Model with Visual Prompt for OFF-Road Autonomous Driving
Jan 07, 2026Efficient trajectory planning in off-road terrains presents a formidable challenge for autonomous vehicles, often necessitating complex multi-step pipelines. However, traditional approaches exhibit limited adaptability in dynamic environments. To address these limitations, this paper proposes OFF-EMMA, a novel end-to-end multimodal framework designed to overcome the deficiencies of insufficient spatial perception and unstable reasoning in visual-language-action (VLA) models for off-road autonomous driving scenarios. The framework explicitly annotates input images through the design of a visual prompt block and introduces a chain-of-thought with self-consistency (COT-SC) reasoning strategy to enhance the accuracy and robustness of trajectory planning. The visual prompt block utilizes semantic segmentation masks as visual prompts, enhancing the spatial understanding ability of pre-trained visual-language models for complex terrains. The COT- SC strategy effectively mitigates the error impact of outliers on planning performance through a multi-path reasoning mechanism. Experimental results on the RELLIS-3D off-road dataset demonstrate that OFF-EMMA significantly outperforms existing methods, reducing the average L2 error of the Qwen backbone model by 13.3% and decreasing the failure rate from 16.52% to 6.56%.
Beyond Speaker Identity: Text Guided Target Speech Extraction
Jan 15, 2025Target Speech Extraction (TSE) traditionally relies on explicit clues about the speaker's identity like enrollment audio, face images, or videos, which may not always be available. In this paper, we propose a text-guided TSE model StyleTSE that uses natural language descriptions of speaking style in addition to the audio clue to extract the desired speech from a given mixture. Our model integrates a speech separation network adapted from SepFormer with a bi-modality clue network that flexibly processes both audio and text clues. To train and evaluate our model, we introduce a new dataset TextrolMix with speech mixtures and natural language descriptions. Experimental results demonstrate that our method effectively separates speech based not only on who is speaking, but also on how they are speaking, enhancing TSE in scenarios where traditional audio clues are absent. Demos are at: https://mingyue66.github.io/TextrolMix/demo/
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

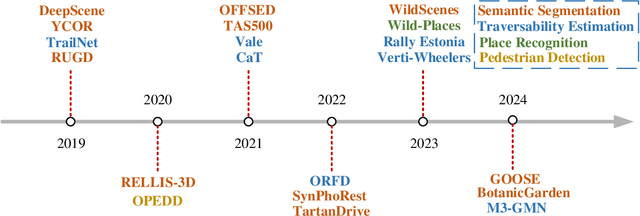

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
Hyperbolic Learning with Synthetic Captions for Open-World Detection
Apr 07, 2024



Open-world detection poses significant challenges, as it requires the detection of any object using either object class labels or free-form texts. Existing related works often use large-scale manual annotated caption datasets for training, which are extremely expensive to collect. Instead, we propose to transfer knowledge from vision-language models (VLMs) to enrich the open-vocabulary descriptions automatically. Specifically, we bootstrap dense synthetic captions using pre-trained VLMs to provide rich descriptions on different regions in images, and incorporate these captions to train a novel detector that generalizes to novel concepts. To mitigate the noise caused by hallucination in synthetic captions, we also propose a novel hyperbolic vision-language learning approach to impose a hierarchy between visual and caption embeddings. We call our detector ``HyperLearner''. We conduct extensive experiments on a wide variety of open-world detection benchmarks (COCO, LVIS, Object Detection in the Wild, RefCOCO) and our results show that our model consistently outperforms existing state-of-the-art methods, such as GLIP, GLIPv2 and Grounding DINO, when using the same backbone.
Neural Insights for Digital Marketing Content Design
Feb 02, 2023In digital marketing, experimenting with new website content is one of the key levers to improve customer engagement. However, creating successful marketing content is a manual and time-consuming process that lacks clear guiding principles. This paper seeks to close the loop between content creation and online experimentation by offering marketers AI-driven actionable insights based on historical data to improve their creative process. We present a neural-network-based system that scores and extracts insights from a marketing content design, namely, a multimodal neural network predicts the attractiveness of marketing contents, and a post-hoc attribution method generates actionable insights for marketers to improve their content in specific marketing locations. Our insights not only point out the advantages and drawbacks of a given current content, but also provide design recommendations based on historical data. We show that our scoring model and insights work well both quantitatively and qualitatively.
Efficient Classification of Very Large Images with Tiny Objects
Jun 04, 2021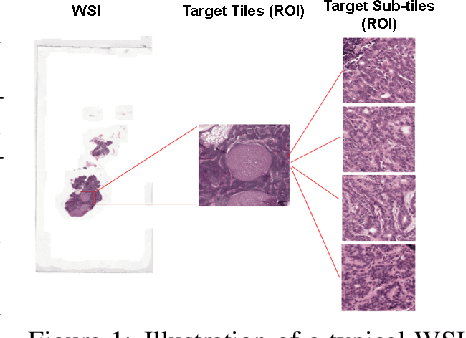

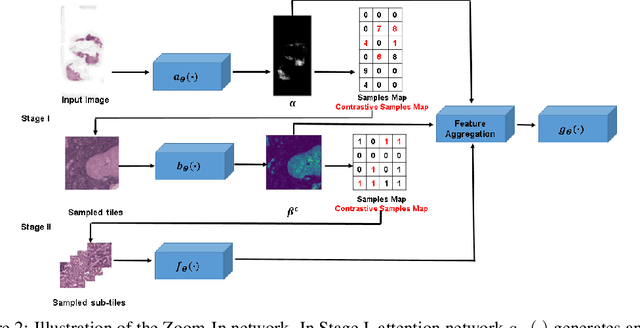

An increasing number of applications in the computer vision domain, specially, in medical imaging and remote sensing, are challenging when the goal is to classify very large images with tiny objects. More specifically, these type of classification tasks face two key challenges: $i$) the size of the input image in the target dataset is usually in the order of megapixels, however, existing deep architectures do not easily operate on such big images due to memory constraints, consequently, we seek a memory-efficient method to process these images; and $ii$) only a small fraction of the input images are informative of the label of interest, resulting in low region of interest (ROI) to image ratio. However, most of the current convolutional neural networks (CNNs) are designed for image classification datasets that have relatively large ROIs and small image size (sub-megapixel). Existing approaches have addressed these two challenges in isolation. We present an end-to-end CNN model termed Zoom-In network that leverages hierarchical attention sampling for classification of large images with tiny objects using a single GPU. We evaluate our method on two large-image datasets and one gigapixel dataset. Experimental results show that our model achieves higher accuracy than existing methods while requiring less computing resources.
Quantum Tensor Network in Machine Learning: An Application to Tiny Object Classification
Jan 08, 2021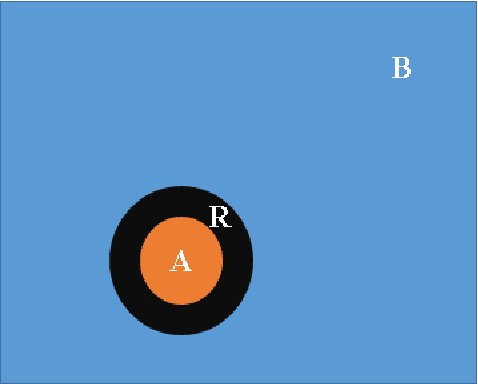

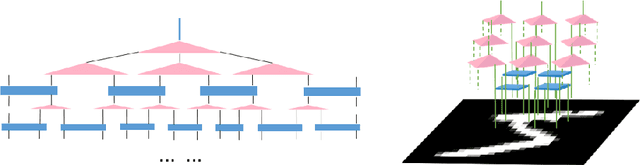
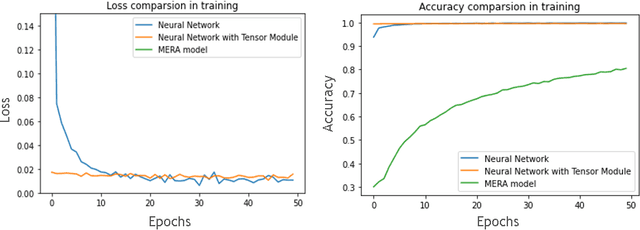
Tiny object classification problem exists in many machine learning applications like medical imaging or remote sensing, where the object of interest usually occupies a small region of the whole image. It is challenging to design an efficient machine learning model with respect to tiny object of interest. Current neural network structures are unable to deal with tiny object efficiently because they are mainly developed for images featured by large scale objects. However, in quantum physics, there is a great theoretical foundation guiding us to analyze the target function for image classification regarding to specific objects size ratio. In our work, we apply Tensor Networks to solve this arising tough machine learning problem. First, we summarize the previous work that connects quantum spin model to image classification and bring the theory into the scenario of tiny object classification. Second, we propose using 2D multi-scale entanglement renormalization ansatz (MERA) to classify tiny objects in image. In the end, our experimental results indicate that tensor network models are effective for tiny object classification problem and potentially will beat state-of-the-art. Our codes will be available online https://github.com/timqqt/MERA_Image_Classification.
* 8 pages, 7 figures
Proactive Pseudo-Intervention: Causally Informed Contrastive Learning For Interpretable Vision Models
Dec 06, 2020

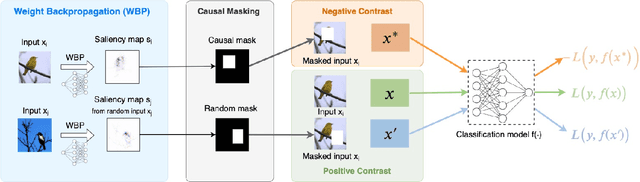
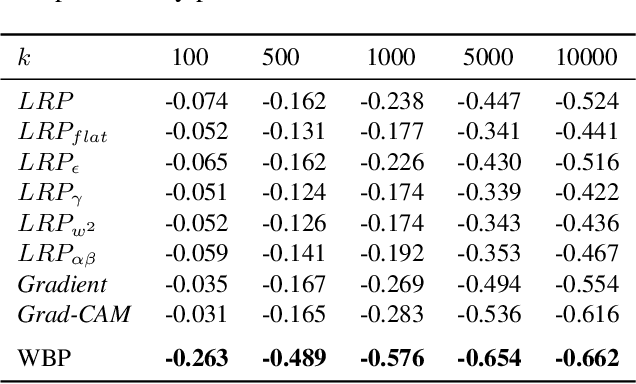
Deep neural networks have shown significant promise in comprehending complex visual signals, delivering performance on par or even superior to that of human experts. However, these models often lack a mechanism for interpreting their predictions, and in some cases, particularly when the sample size is small, existing deep learning solutions tend to capture spurious correlations that compromise model generalizability on unseen inputs. In this work, we propose a contrastive causal representation learning strategy that leverages proactive interventions to identify causally-relevant image features, called Proactive Pseudo-Intervention (PPI). This approach is complemented with a causal salience map visualization module, i.e., Weight Back Propagation (WBP), that identifies important pixels in the raw input image, which greatly facilitates the interpretability of predictions. To validate its utility, our model is benchmarked extensively on both standard natural images and challenging medical image datasets. We show this new contrastive causal representation learning model consistently improves model performance relative to competing solutions, particularly for out-of-domain predictions or when dealing with data integration from heterogeneous sources. Further, our causal saliency maps are more succinct and meaningful relative to their non-causal counterparts.