 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving and Evaluating Open Deep Research Agents
Aug 13, 2025We focus here on Deep Research Agents (DRAs), which are systems that can take a natural language prompt from a user, and then autonomously search for, and utilize, internet-based content to address the prompt. Recent DRAs have demonstrated impressive capabilities on public benchmarks however, recent research largely involves proprietary closed-source systems. At the time of this work, we only found one open-source DRA, termed Open Deep Research (ODR). In this work we adapt the challenging recent BrowseComp benchmark to compare ODR to existing proprietary systems. We propose BrowseComp-Small (BC-Small), comprising a subset of BrowseComp, as a more computationally-tractable DRA benchmark for academic labs. We benchmark ODR and two other proprietary systems on BC-Small: one system from Anthropic and one system from Google. We find that all three systems achieve 0% accuracy on the test set of 60 questions. We introduce three strategic improvements to ODR, resulting in the ODR+ model, which achieves a state-of-the-art 10% success rate on BC-Small among both closed-source and open-source systems. We report ablation studies indicating that all three of our improvements contributed to the success of ODR+.
An Agentic Framework for Autonomous Metamaterial Modeling and Inverse Design
Jun 07, 2025Recent significant advances in integrating multiple Large Language Model (LLM) systems have enabled Agentic Frameworks capable of performing complex tasks autonomously, including novel scientific research. We develop and demonstrate such a framework specifically for the inverse design of photonic metamaterials. When queried with a desired optical spectrum, the Agent autonomously proposes and develops a forward deep learning model, accesses external tools via APIs for tasks like simulation and optimization, utilizes memory, and generates a final design via a deep inverse method. The framework's effectiveness is demonstrated in its ability to automate, reason, plan, and adapt. Notably, the Agentic Framework possesses internal reflection and decision flexibility, permitting highly varied and potentially novel outputs.
Are Deep Learning Models Robust to Partial Object Occlusion in Visual Recognition Tasks?
Sep 16, 2024
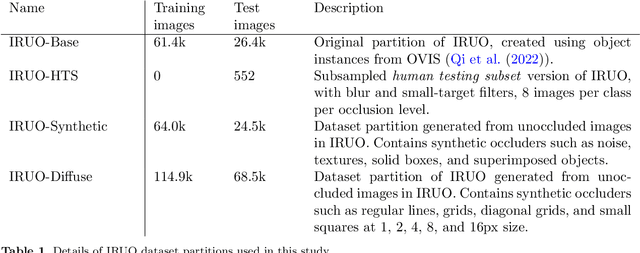

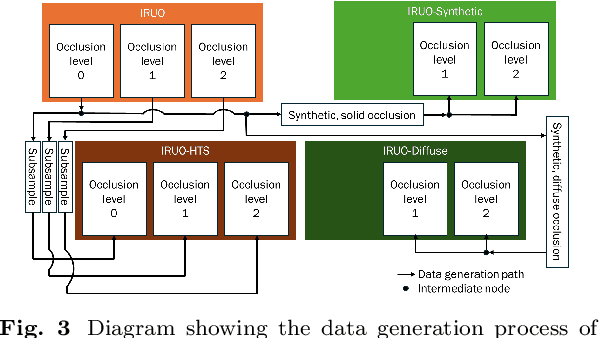
Image classification models, including convolutional neural networks (CNNs), perform well on a variety of classification tasks but struggle under conditions of partial occlusion, i.e., conditions in which objects are partially covered from the view of a camera. Methods to improve performance under occlusion, including data augmentation, part-based clustering, and more inherently robust architectures, including Vision Transformer (ViT) models, have, to some extent, been evaluated on their ability to classify objects under partial occlusion. However, evaluations of these methods have largely relied on images containing artificial occlusion, which are typically computer-generated and therefore inexpensive to label. Additionally, methods are rarely compared against each other, and many methods are compared against early, now outdated, deep learning models. We contribute the Image Recognition Under Occlusion (IRUO) dataset, based on the recently developed Occluded Video Instance Segmentation (OVIS) dataset (arXiv:2102.01558). IRUO utilizes real-world and artificially occluded images to test and benchmark leading methods' robustness to partial occlusion in visual recognition tasks. In addition, we contribute the design and results of a human study using images from IRUO that evaluates human classification performance at multiple levels and types of occlusion. We find that modern CNN-based models show improved recognition accuracy on occluded images compared to earlier CNN-based models, and ViT-based models are more accurate than CNN-based models on occluded images, performing only modestly worse than human accuracy. We also find that certain types of occlusion, including diffuse occlusion, where relevant objects are seen through "holes" in occluders such as fences and leaves, can greatly reduce the accuracy of deep recognition models as compared to humans, especially those with CNN backbones.
Can Large Language Models Learn the Physics of Metamaterials? An Empirical Study with ChatGPT
Apr 23, 2024Large language models (LLMs) such as ChatGPT, Gemini, LlaMa, and Claude are trained on massive quantities of text parsed from the internet and have shown a remarkable ability to respond to complex prompts in a manner often indistinguishable from humans. We present a LLM fine-tuned on up to 40,000 data that can predict electromagnetic spectra over a range of frequencies given a text prompt that only specifies the metasurface geometry. Results are compared to conventional machine learning approaches including feed-forward neural networks, random forest, linear regression, and K-nearest neighbor (KNN). Remarkably, the fine-tuned LLM (FT-LLM) achieves a lower error across all dataset sizes explored compared to all machine learning approaches including a deep neural network. We also demonstrate the LLM's ability to solve inverse problems by providing the geometry necessary to achieve a desired spectrum. LLMs possess some advantages over humans that may give them benefits for research, including the ability to process enormous amounts of data, find hidden patterns in data, and operate in higher-dimensional spaces. We propose that fine-tuning LLMs on large datasets specific to a field allows them to grasp the nuances of that domain, making them valuable tools for research and analysis.
Segment anything, from space?
May 15, 2023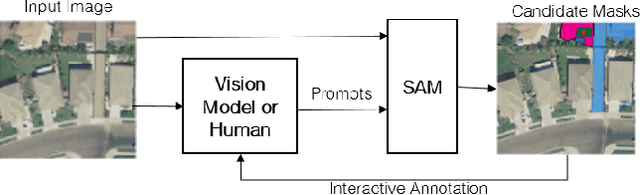
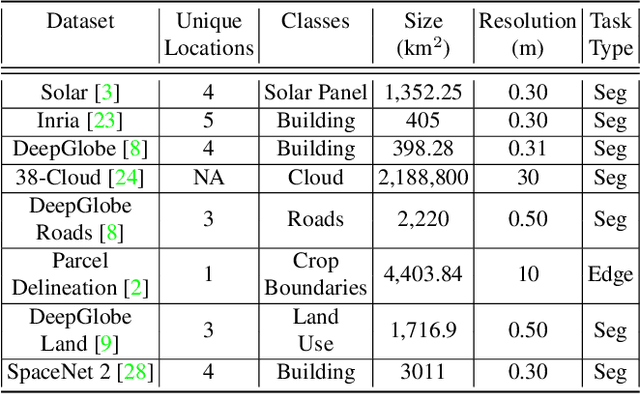

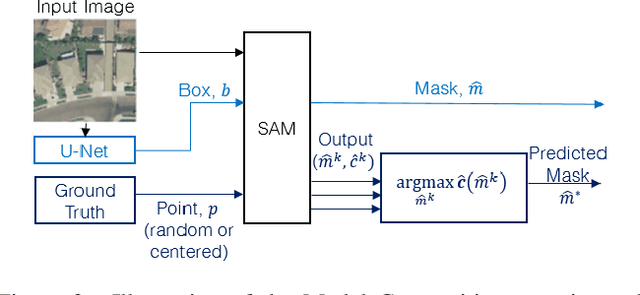
Recently, the first foundation model developed specifically for vision tasks was developed, termed the "Segment Anything Model" (SAM). SAM can segment objects in input imagery based upon cheap input prompts, such as one (or more) points, a bounding box, or a mask. The authors examined the zero-shot image segmentation accuracy of SAM on a large number of vision benchmark tasks and found that SAM usually achieved recognition accuracy similar to, or sometimes exceeding, vision models that had been trained on the target tasks. The impressive generalization of SAM for segmentation has major implications for vision researchers working on natural imagery. In this work, we examine whether SAM's impressive performance extends to overhead imagery problems, and help guide the community's response to its development. We examine SAM's performance on a set of diverse and widely-studied benchmark tasks. We find that SAM does often generalize well to overhead imagery, although it fails in some cases due to the unique characteristics of overhead imagery and the target objects. We report on these unique systematic failure cases for remote sensing imagery that may comprise useful future research for the community. Note that this is a working paper, and it will be updated as additional analysis and results are completed.
Meta-Learning for Color-to-Infrared Cross-Modal Style Transfer
Dec 24, 2022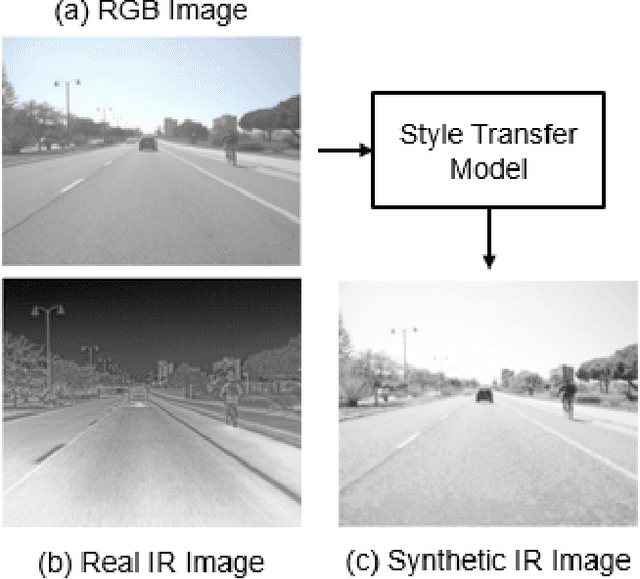


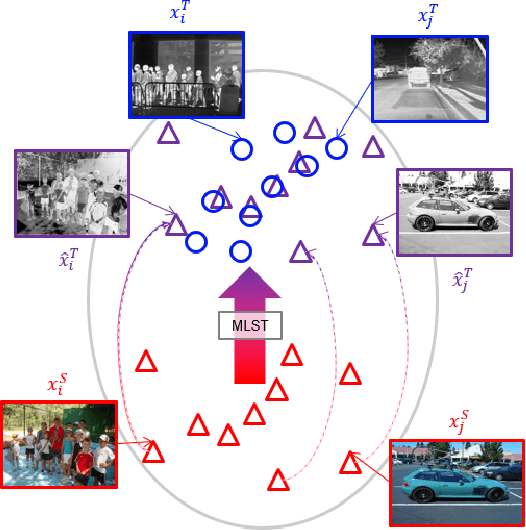
Recent object detection models for infrared (IR) imagery are based upon deep neural networks (DNNs) and require large amounts of labeled training imagery. However, publicly-available datasets that can be used for such training are limited in their size and diversity. To address this problem, we explore cross-modal style transfer (CMST) to leverage large and diverse color imagery datasets so that they can be used to train DNN-based IR image based object detectors. We evaluate six contemporary stylization methods on four publicly-available IR datasets - the first comparison of its kind - and find that CMST is highly effective for DNN-based detectors. Surprisingly, we find that existing data-driven methods are outperformed by a simple grayscale stylization (an average of the color channels). Our analysis reveals that existing data-driven methods are either too simplistic or introduce significant artifacts into the imagery. To overcome these limitations, we propose meta-learning style transfer (MLST), which learns a stylization by composing and tuning well-behaved analytic functions. We find that MLST leads to more complex stylizations without introducing significant image artifacts and achieves the best overall detector performance on our benchmark datasets.
Mixture Manifold Networks: A Computationally Efficient Baseline for Inverse Modeling
Nov 25, 2022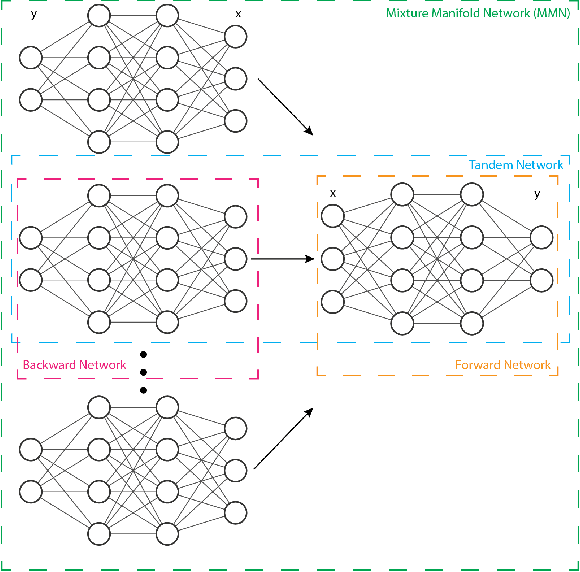
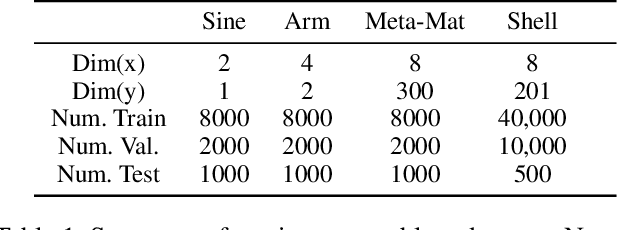
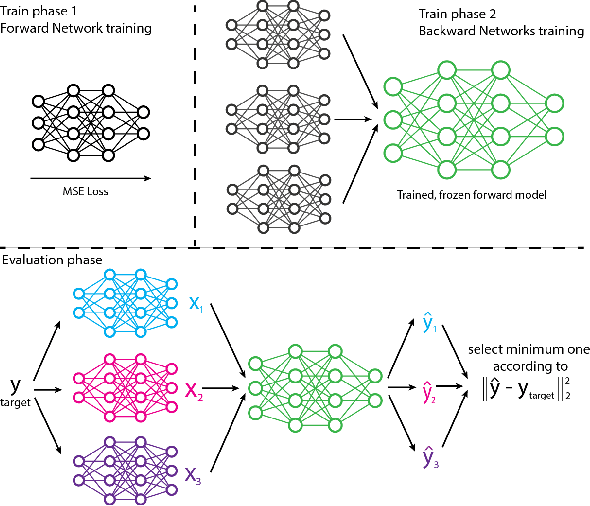
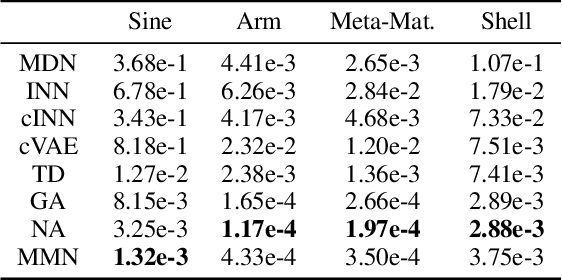
We propose and show the efficacy of a new method to address generic inverse problems. Inverse modeling is the task whereby one seeks to determine the control parameters of a natural system that produce a given set of observed measurements. Recent work has shown impressive results using deep learning, but we note that there is a trade-off between model performance and computational time. For some applications, the computational time at inference for the best performing inverse modeling method may be overly prohibitive to its use. We present a new method that leverages multiple manifolds as a mixture of backward (e.g., inverse) models in a forward-backward model architecture. These multiple backwards models all share a common forward model, and their training is mitigated by generating training examples from the forward model. The proposed method thus has two innovations: 1) the multiple Manifold Mixture Network (MMN) architecture, and 2) the training procedure involving augmenting backward model training data using the forward model. We demonstrate the advantages of our method by comparing to several baselines on four benchmark inverse problems, and we furthermore provide analysis to motivate its design.
Meta-simulation for the Automated Design of Synthetic Overhead Imagery
Sep 19, 2022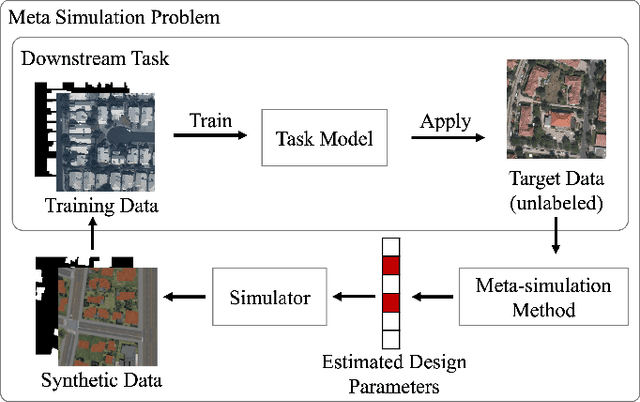



The use of synthetic (or simulated) data for training machine learning models has grown rapidly in recent years. Synthetic data can often be generated much faster and more cheaply than its real-world counterpart. One challenge of using synthetic imagery however is scene design: e.g., the choice of content and its features and spatial arrangement. To be effective, this design must not only be realistic, but appropriate for the target domain, which (by assumption) is unlabeled. In this work, we propose an approach to automatically choose the design of synthetic imagery based upon unlabeled real-world imagery. Our approach, termed Neural-Adjoint Meta-Simulation (NAMS), builds upon the seminal recent meta-simulation approaches. In contrast to the current state-of-the-art methods, our approach can be pre-trained once offline, and then provides fast design inference for new target imagery. Using both synthetic and real-world problems, we show that NAMS infers synthetic designs that match both the in-domain and out-of-domain target imagery, and that training segmentation models with NAMS-designed imagery yields superior results compared to na\"ive randomized designs and state-of-the-art meta-simulation methods.
Automated Extraction of Energy Systems Information from Remotely Sensed Data: A Review and Analysis
Feb 18, 2022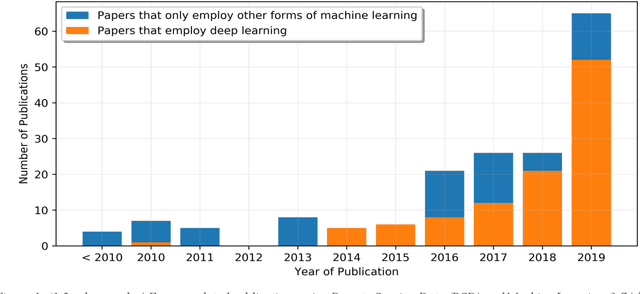
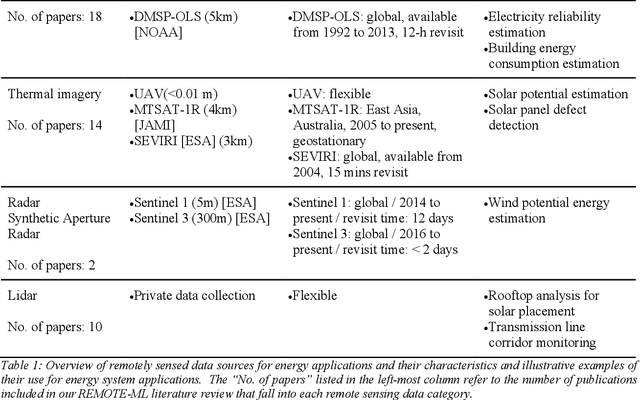


High quality energy systems information is a crucial input to energy systems research, modeling, and decision-making. Unfortunately, precise information about energy systems is often of limited availability, incomplete, or only accessible for a substantial fee or through a non-disclosure agreement. Recently, remotely sensed data (e.g., satellite imagery, aerial photography) have emerged as a potentially rich source of energy systems information. However, the use of these data is frequently challenged by its sheer volume and complexity, precluding manual analysis. Recent breakthroughs in machine learning have enabled automated and rapid extraction of useful information from remotely sensed data, facilitating large-scale acquisition of critical energy system variables. Here we present a systematic review of the literature on this emerging topic, providing an in-depth survey and review of papers published within the past two decades. We first taxonomize the existing literature into ten major areas, spanning the energy value chain. Within each research area, we distill and critically discuss major features that are relevant to energy researchers, including, for example, key challenges regarding the accessibility and reliability of the methods. We then synthesize our findings to identify limitations and trends in the literature as a whole, and discuss opportunities for innovation.
Inverse deep learning methods and benchmarks for artificial electromagnetic material design
Dec 19, 2021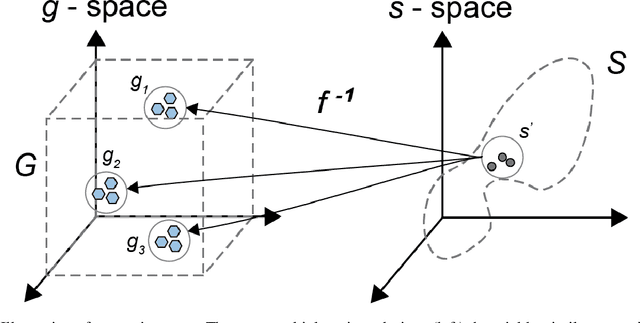
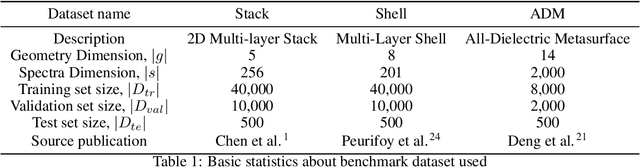
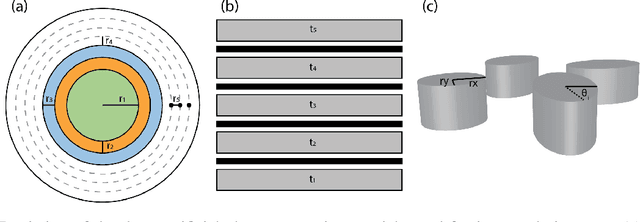

Deep learning (DL) inverse techniques have increased the speed of artificial electromagnetic material (AEM) design and improved the quality of resulting devices. Many DL inverse techniques have succeeded on a number of AEM design tasks, but to compare, contrast, and evaluate assorted techniques it is critical to clarify the underlying ill-posedness of inverse problems. Here we review state-of-the-art approaches and present a comprehensive survey of deep learning inverse methods and invertible and conditional invertible neural networks to AEM design. We produce easily accessible and rapidly implementable AEM design benchmarks, which offers a methodology to efficiently determine the DL technique best suited to solving different design challenges. Our methodology is guided by constraints on repeated simulation and an easily integrated metric, which we propose expresses the relative ill-posedness of any AEM design problem. We show that as the problem becomes increasingly ill-posed, the neural adjoint with boundary loss (NA) generates better solutions faster, regardless of simulation constraints. On simpler AEM design tasks, direct neural networks (NN) fare better when simulations are limited, while geometries predicted by mixture density networks (MDN) and conditional variational auto-encoders (VAE) can improve with continued sampling and re-simulation.