 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving and Evaluating Open Deep Research Agents
Aug 13, 2025We focus here on Deep Research Agents (DRAs), which are systems that can take a natural language prompt from a user, and then autonomously search for, and utilize, internet-based content to address the prompt. Recent DRAs have demonstrated impressive capabilities on public benchmarks however, recent research largely involves proprietary closed-source systems. At the time of this work, we only found one open-source DRA, termed Open Deep Research (ODR). In this work we adapt the challenging recent BrowseComp benchmark to compare ODR to existing proprietary systems. We propose BrowseComp-Small (BC-Small), comprising a subset of BrowseComp, as a more computationally-tractable DRA benchmark for academic labs. We benchmark ODR and two other proprietary systems on BC-Small: one system from Anthropic and one system from Google. We find that all three systems achieve 0% accuracy on the test set of 60 questions. We introduce three strategic improvements to ODR, resulting in the ODR+ model, which achieves a state-of-the-art 10% success rate on BC-Small among both closed-source and open-source systems. We report ablation studies indicating that all three of our improvements contributed to the success of ODR+.
Segment anything, from space?
May 15, 2023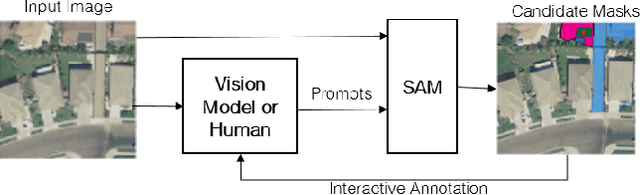
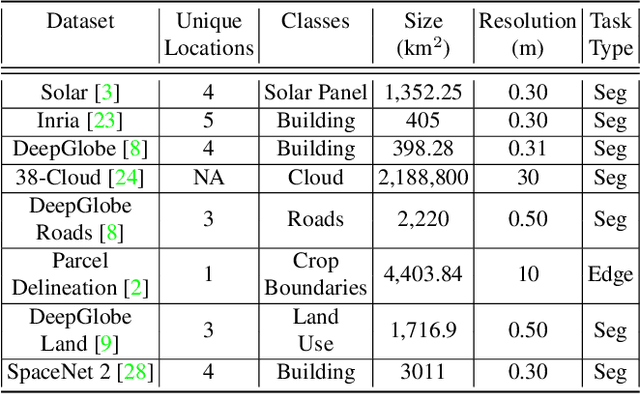

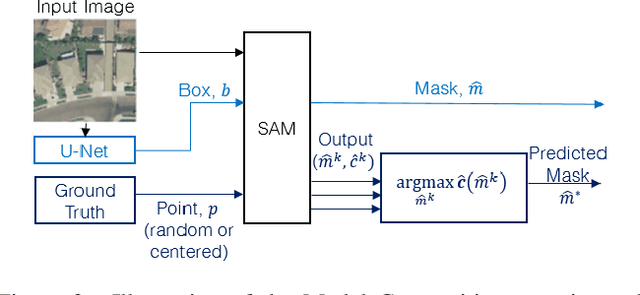
Recently, the first foundation model developed specifically for vision tasks was developed, termed the "Segment Anything Model" (SAM). SAM can segment objects in input imagery based upon cheap input prompts, such as one (or more) points, a bounding box, or a mask. The authors examined the zero-shot image segmentation accuracy of SAM on a large number of vision benchmark tasks and found that SAM usually achieved recognition accuracy similar to, or sometimes exceeding, vision models that had been trained on the target tasks. The impressive generalization of SAM for segmentation has major implications for vision researchers working on natural imagery. In this work, we examine whether SAM's impressive performance extends to overhead imagery problems, and help guide the community's response to its development. We examine SAM's performance on a set of diverse and widely-studied benchmark tasks. We find that SAM does often generalize well to overhead imagery, although it fails in some cases due to the unique characteristics of overhead imagery and the target objects. We report on these unique systematic failure cases for remote sensing imagery that may comprise useful future research for the community. Note that this is a working paper, and it will be updated as additional analysis and results are completed.
Transformers For Recognition In Overhead Imagery: A Reality Check
Oct 31, 2022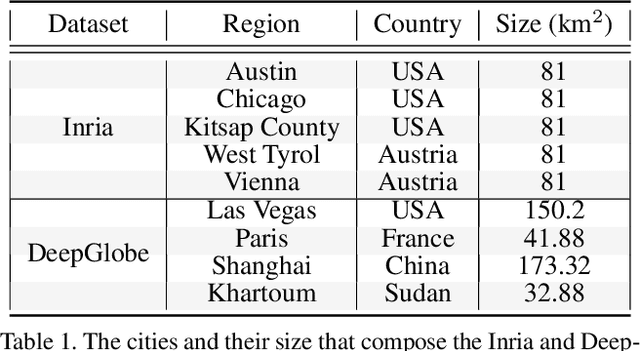
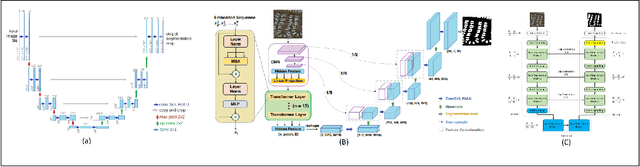

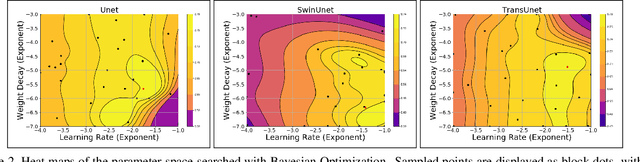
There is evidence that transformers offer state-of-the-art recognition performance on tasks involving overhead imagery (e.g., satellite imagery). However, it is difficult to make unbiased empirical comparisons between competing deep learning models, making it unclear whether, and to what extent, transformer-based models are beneficial. In this paper we systematically compare the impact of adding transformer structures into state-of-the-art segmentation models for overhead imagery. Each model is given a similar budget of free parameters, and their hyperparameters are optimized using Bayesian Optimization with a fixed quantity of data and computation time. We conduct our experiments with a large and diverse dataset comprising two large public benchmarks: Inria and DeepGlobe. We perform additional ablation studies to explore the impact of specific transformer-based modeling choices. Our results suggest that transformers provide consistent, but modest, performance improvements. We only observe this advantage however in hybrid models that combine convolutional and transformer-based structures, while fully transformer-based models achieve relatively poor performance.
Automated Extraction of Energy Systems Information from Remotely Sensed Data: A Review and Analysis
Feb 18, 2022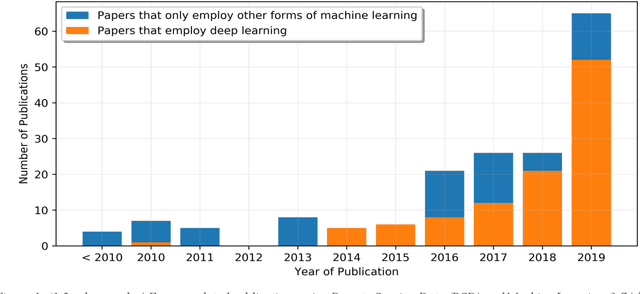
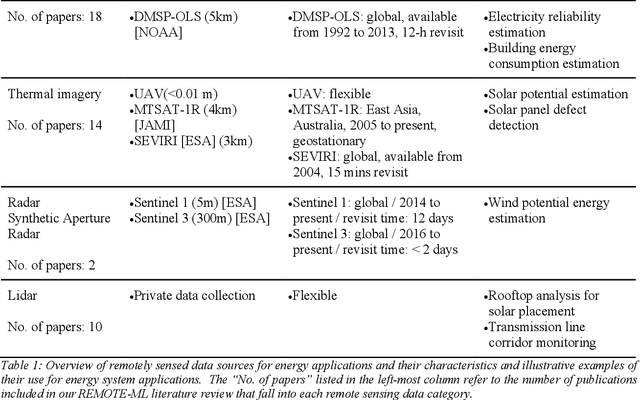


High quality energy systems information is a crucial input to energy systems research, modeling, and decision-making. Unfortunately, precise information about energy systems is often of limited availability, incomplete, or only accessible for a substantial fee or through a non-disclosure agreement. Recently, remotely sensed data (e.g., satellite imagery, aerial photography) have emerged as a potentially rich source of energy systems information. However, the use of these data is frequently challenged by its sheer volume and complexity, precluding manual analysis. Recent breakthroughs in machine learning have enabled automated and rapid extraction of useful information from remotely sensed data, facilitating large-scale acquisition of critical energy system variables. Here we present a systematic review of the literature on this emerging topic, providing an in-depth survey and review of papers published within the past two decades. We first taxonomize the existing literature into ten major areas, spanning the energy value chain. Within each research area, we distill and critically discuss major features that are relevant to energy researchers, including, for example, key challenges regarding the accessibility and reliability of the methods. We then synthesize our findings to identify limitations and trends in the literature as a whole, and discuss opportunities for innovation.
Utilizing geospatial data for assessing energy security: Mapping small solar home systems using unmanned aerial vehicles and deep learning
Jan 14, 2022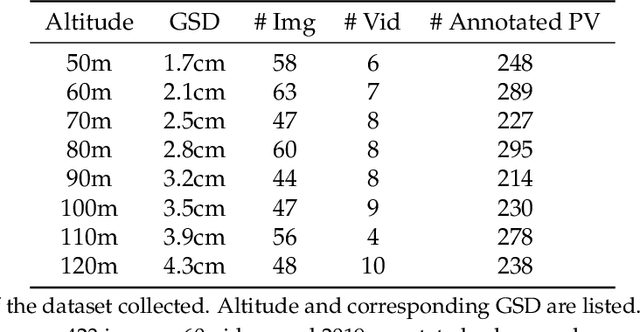

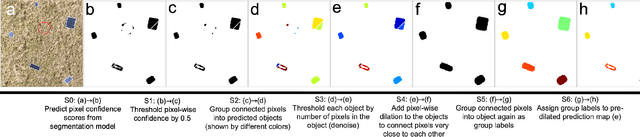
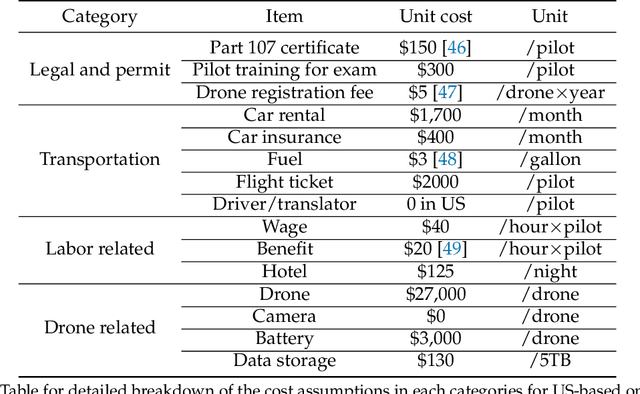
Solar home systems (SHS), a cost-effective solution for rural communities far from the grid in developing countries, are small solar panels and associated equipment that provides power to a single household. A crucial resource for targeting further investment of public and private resources, as well as tracking the progress of universal electrification goals, is shared access to high-quality data on individual SHS installations including information such as location and power capacity. Though recent studies utilizing satellite imagery and machine learning to detect solar panels have emerged, they struggle to accurately locate many SHS due to limited image resolution (some small solar panels only occupy several pixels in satellite imagery). In this work, we explore the viability and cost-performance tradeoff of using automatic SHS detection on unmanned aerial vehicle (UAV) imagery as an alternative to satellite imagery. More specifically, we explore three questions: (i) what is the detection performance of SHS using drone imagery; (ii) how expensive is the drone data collection, compared to satellite imagery; and (iii) how well does drone-based SHS detection perform in real-world scenarios. We collect and publicly-release a dataset of high-resolution drone imagery encompassing SHS imaged under real-world conditions and use this dataset and a dataset from Rwanda to evaluate the capabilities of deep learning models to recognize SHS, including those that are too small to be reliably recognized in satellite imagery. The results suggest that UAV imagery may be a viable alternative to identify very small SHS from perspectives of both detection accuracy and financial costs of data collection. UAV-based data collection may be a practical option for supporting electricity access planning strategies for achieving sustainable development goals and for monitoring the progress towards those goals.
SIMPL: Generating Synthetic Overhead Imagery to Address Zero-shot and Few-Shot Detection Problems
Jun 29, 2021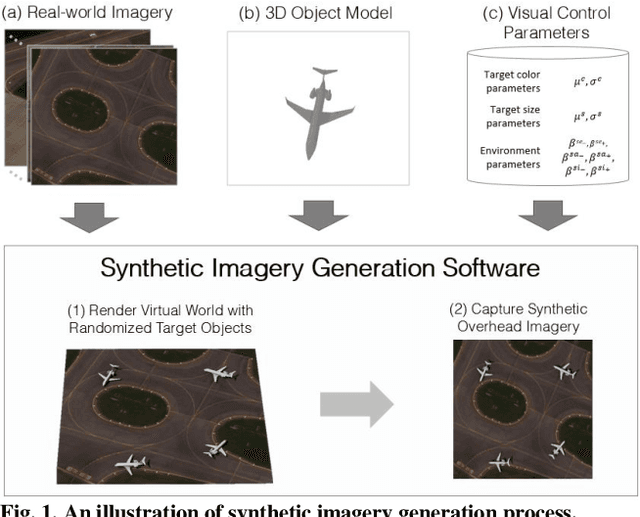
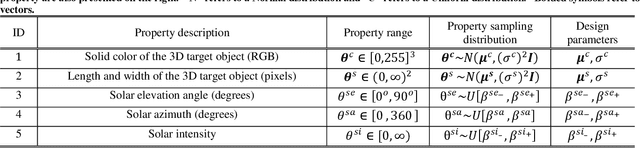

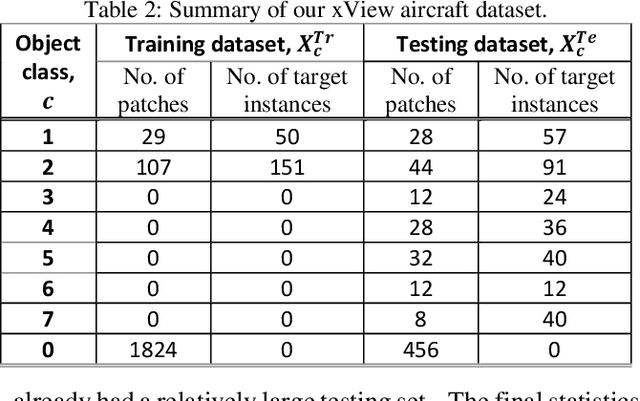
Recently deep neural networks (DNNs) have achieved tremendous success for object detection in overhead (e.g., satellite) imagery. One ongoing challenge however is the acquisition of training data, due to high costs of obtaining satellite imagery and annotating objects in it. In this work we present a simple approach - termed Synthetic object IMPLantation (SIMPL) - to easily and rapidly generate large quantities of synthetic overhead training data for custom target objects. We demonstrate the effectiveness of using SIMPL synthetic imagery for training DNNs in zero-shot scenarios where no real imagery is available; and few-shot learning scenarios, where limited real-world imagery is available. We also conduct experiments to study the sensitivity of SIMPL's effectiveness to some key design parameters, providing users for insights when designing synthetic imagery for custom objects. We release a software implementation of our SIMPL approach so that others can build upon it, or use it for their own custom problems.
Randomized Histogram Matching: A Simple Augmentation for Unsupervised Domain Adaptation in Overhead Imagery
Apr 30, 2021
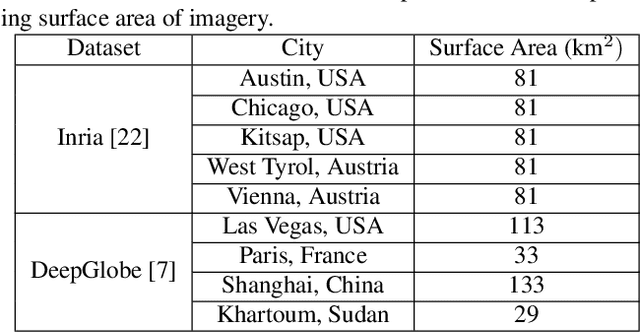
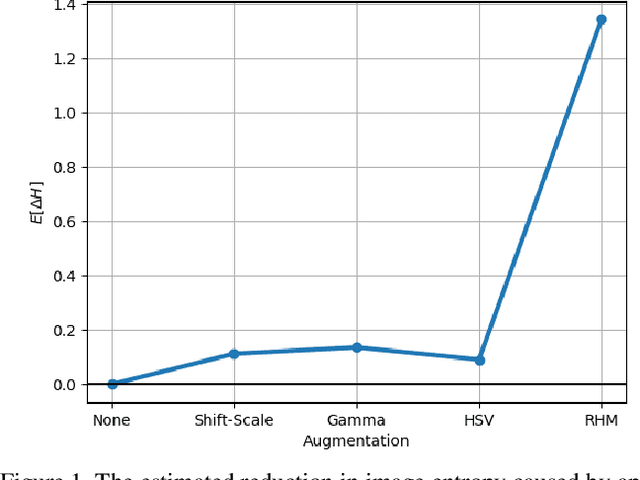
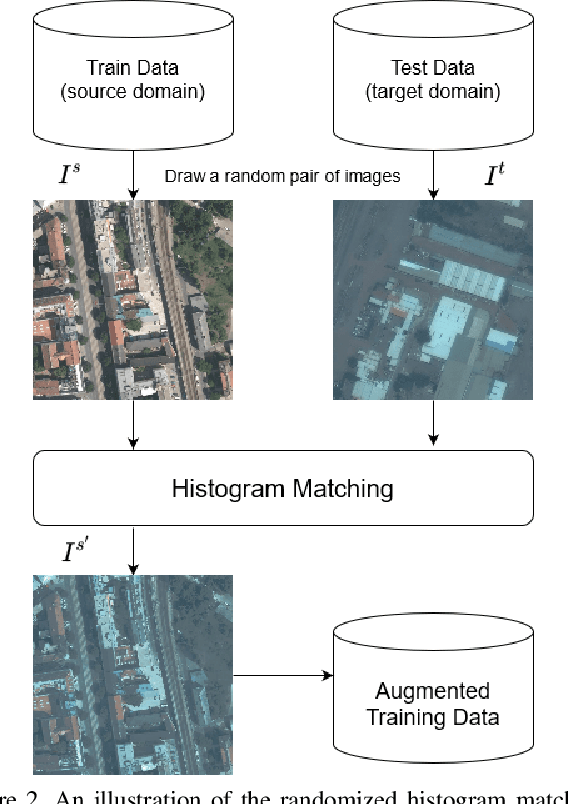
Modern deep neural networks (DNNs) achieve highly accurate results for many recognition tasks on overhead (e.g., satellite) imagery. One challenge however is visual domain shifts (i.e., statistical changes), which can cause the accuracy of DNNs to degrade substantially and unpredictably when tested on new sets of imagery. In this work we model domain shifts caused by variations in imaging hardware, lighting, and other conditions as non-linear pixel-wise transformations; and we show that modern DNNs can become largely invariant to these types of transformations, if provided with appropriate training data augmentation. In general, however, we do not know the transformation between two sets of imagery. To overcome this problem, we propose a simple real-time unsupervised training augmentation technique, termed randomized histogram matching (RHM). We conduct experiments with two large public benchmark datasets for building segmentation and find that RHM consistently yields comparable performance to recent state-of-the-art unsupervised domain adaptation approaches despite being simpler and faster. RHM also offers substantially better performance than other comparably simple approaches that are widely-used in overhead imagery.
GridTracer: Automatic Mapping of Power Grids using Deep Learning and Overhead Imagery
Jan 16, 2021
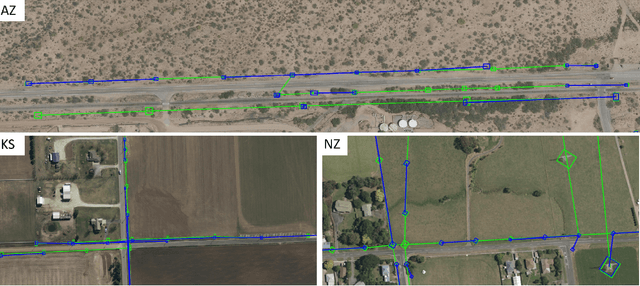

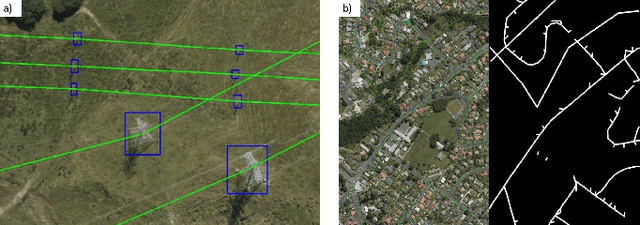
Energy system information valuable for electricity access planning such as the locations and connectivity of electricity transmission and distribution towers, termed the power grid, is often incomplete, outdated, or altogether unavailable. Furthermore, conventional means for collecting this information is costly and limited. We propose to automatically map the grid in overhead remotely sensed imagery using deep learning. Towards this goal, we develop and publicly-release a large dataset ($263km^2$) of overhead imagery with ground truth for the power grid, to our knowledge this is the first dataset of its kind in the public domain. Additionally, we propose scoring metrics and baseline algorithms for two grid mapping tasks: (1) tower recognition and (2) power line interconnection (i.e., estimating a graph representation of the grid). We hope the availability of the training data, scoring metrics, and baselines will facilitate rapid progress on this important problem to help decision-makers address the energy needs of societies around the world.
The Synthinel-1 dataset: a collection of high resolution synthetic overhead imagery for building segmentation
Jan 15, 2020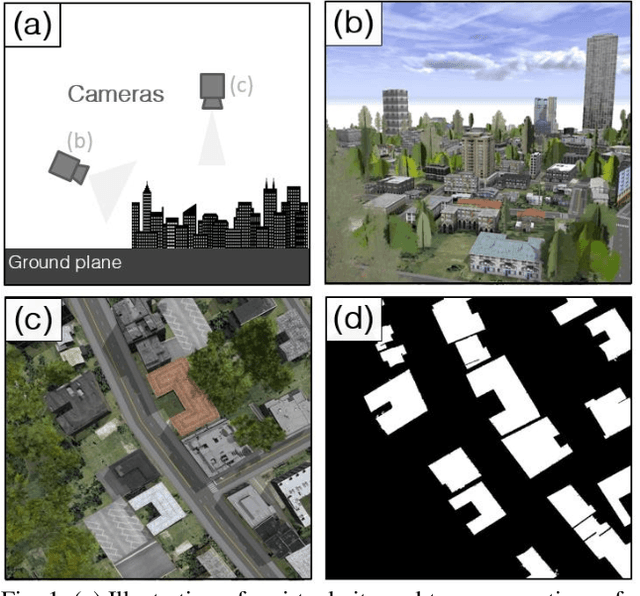
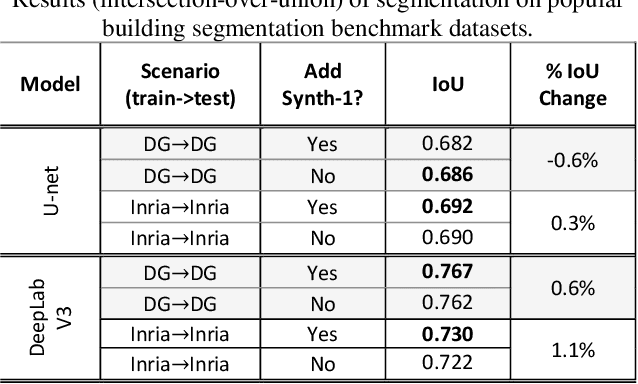

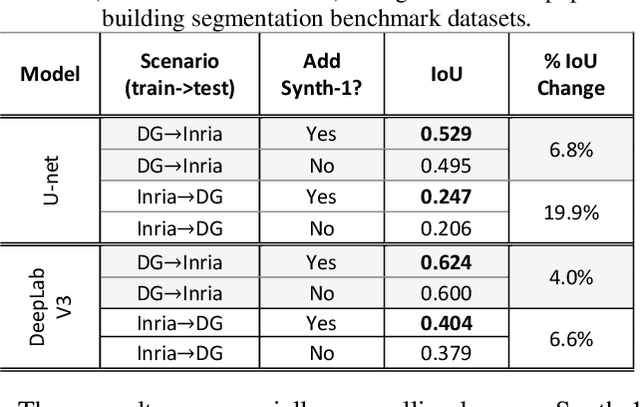
Recently deep learning - namely convolutional neural networks (CNNs) - have yielded impressive performance for the task of building segmentation on large overhead (e.g., satellite) imagery benchmarks. However, these benchmark datasets only capture a small fraction of the variability present in real-world overhead imagery, limiting the ability to properly train, or evaluate, models for real-world application. Unfortunately, developing a dataset that captures even a small fraction of real-world variability is typically infeasible due to the cost of imagery, and manual pixel-wise labeling of the imagery. In this work we develop an approach to rapidly and cheaply generate large and diverse virtual environments from which we can capture synthetic overhead imagery for training segmentation CNNs. Using this approach, generate and publicly-release a collection of synthetic overhead imagery - termed Synthinel-1 with full pixel-wise building labels. We use several benchmark dataset to demonstrate that Synthinel-1 is consistently beneficial when used to augment real-world training imagery, especially when CNNs are tested on novel geographic locations or conditions.
Mapping solar array location, size, and capacity using deep learning and overhead imagery
Feb 28, 2019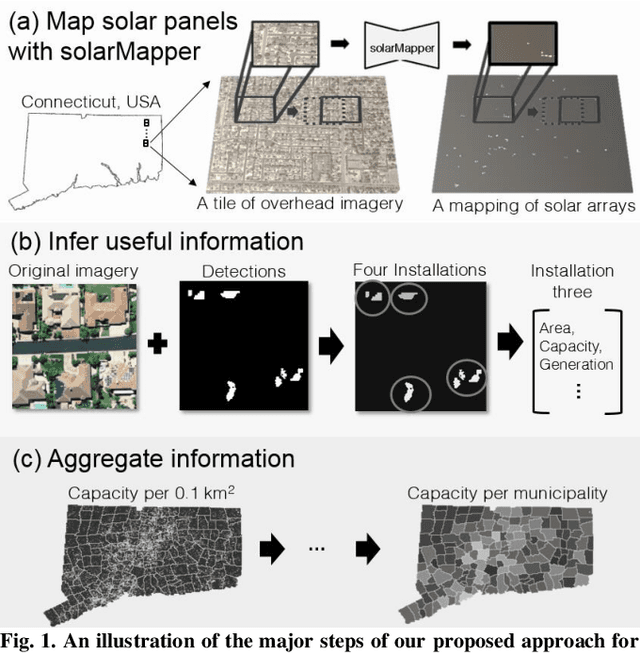

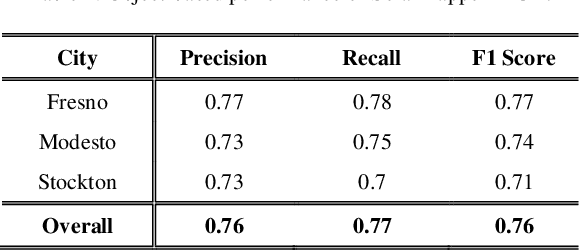
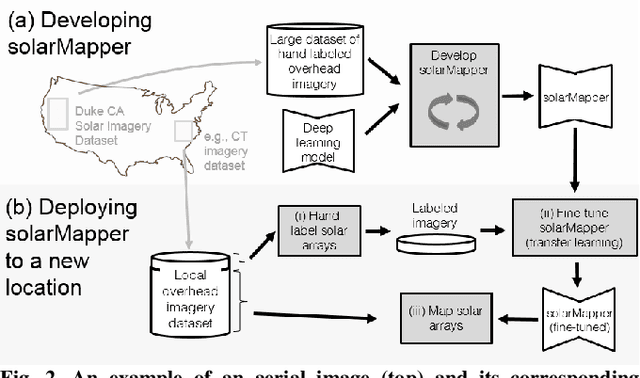
The effective integration of distributed solar photovoltaic (PV) arrays into existing power grids will require access to high quality data; the location, power capacity, and energy generation of individual solar PV installations. Unfortunately, existing methods for obtaining this data are limited in their spatial resolution and completeness. We propose a general framework for accurately and cheaply mapping individual PV arrays, and their capacities, over large geographic areas. At the core of this approach is a deep learning algorithm called SolarMapper - which we make publicly available - that can automatically map PV arrays in high resolution overhead imagery. We estimate the performance of SolarMapper on a large dataset of overhead imagery across three US cities in California. We also describe a procedure for deploying SolarMapper to new geographic regions, so that it can be utilized by others. We demonstrate the effectiveness of the proposed deployment procedure by using it to map solar arrays across the entire US state of Connecticut (CT). Using these results, we demonstrate that we achieve highly accurate estimates of total installed PV capacity within each of CT's 168 municipal regions.