 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Next-Day Wildfire Spread with Time Series and Attention
Feb 17, 2025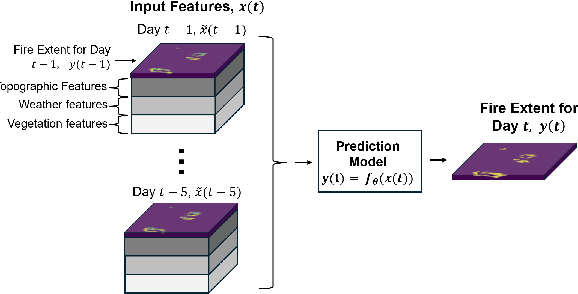
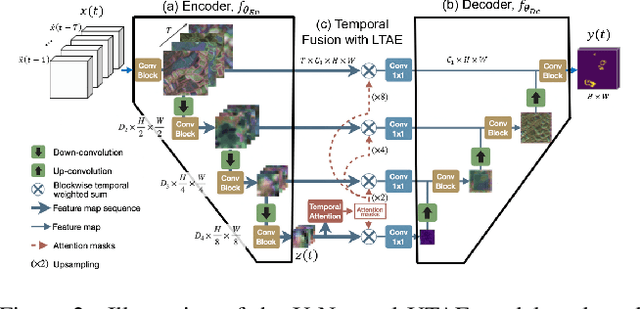

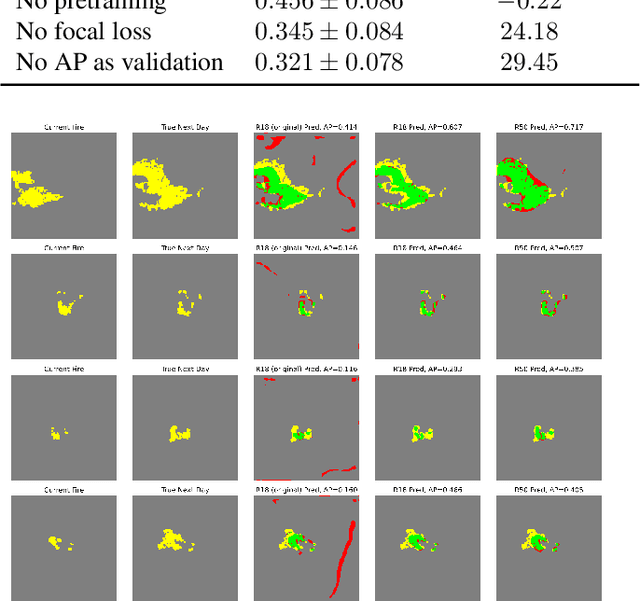
Recent research has demonstrated the potential of deep neural networks (DNNs) to accurately predict next-day wildfire spread, based upon the current extent of a fire and geospatial rasters of influential environmental covariates e.g., vegetation, topography, climate, and weather. In this work, we investigate a recent transformer-based model, termed the SwinUnet, for next-day wildfire prediction. We benchmark Swin-based models against several current state-of-the-art models on WildfireSpreadTS (WFTS), a large public benchmark dataset of historical wildfire events. We consider two next-day fire prediction scenarios: when the model is given input of (i) a single previous day of data, or (ii) five previous days of data. We find that, with the proper modifications, SwinUnet achieves state-of-the-art accuracy on next-day prediction for both the single-day and multi-day scenarios. SwinUnet's success depends heavily upon utilizing pre-trained weights from ImageNet. Consistent with prior work, we also found that models with multi-day-input always outperformed models with single-day input.
Segment anything, from space?
May 15, 2023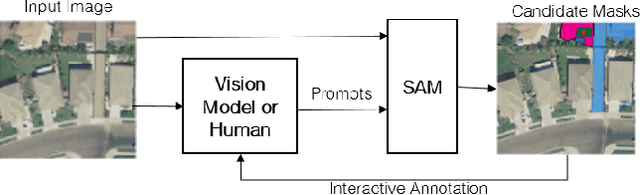
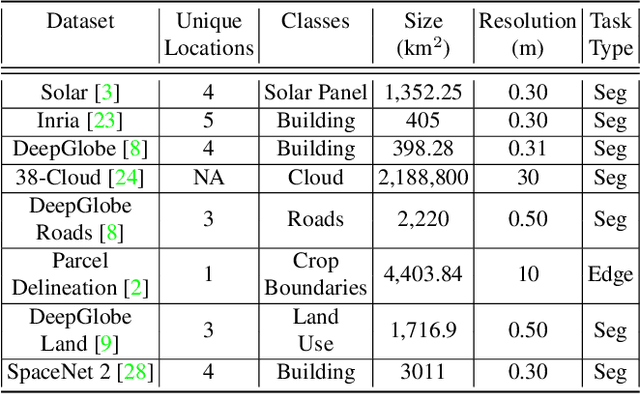

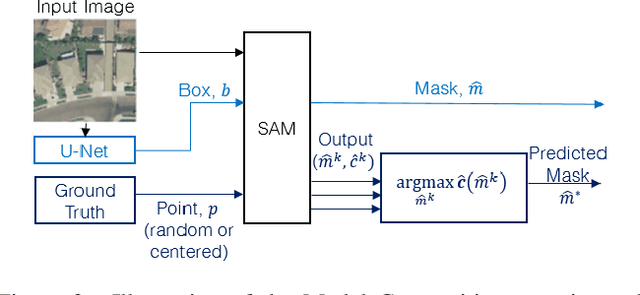
Recently, the first foundation model developed specifically for vision tasks was developed, termed the "Segment Anything Model" (SAM). SAM can segment objects in input imagery based upon cheap input prompts, such as one (or more) points, a bounding box, or a mask. The authors examined the zero-shot image segmentation accuracy of SAM on a large number of vision benchmark tasks and found that SAM usually achieved recognition accuracy similar to, or sometimes exceeding, vision models that had been trained on the target tasks. The impressive generalization of SAM for segmentation has major implications for vision researchers working on natural imagery. In this work, we examine whether SAM's impressive performance extends to overhead imagery problems, and help guide the community's response to its development. We examine SAM's performance on a set of diverse and widely-studied benchmark tasks. We find that SAM does often generalize well to overhead imagery, although it fails in some cases due to the unique characteristics of overhead imagery and the target objects. We report on these unique systematic failure cases for remote sensing imagery that may comprise useful future research for the community. Note that this is a working paper, and it will be updated as additional analysis and results are completed.