 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Next-Day Wildfire Spread with Time Series and Attention
Feb 17, 2025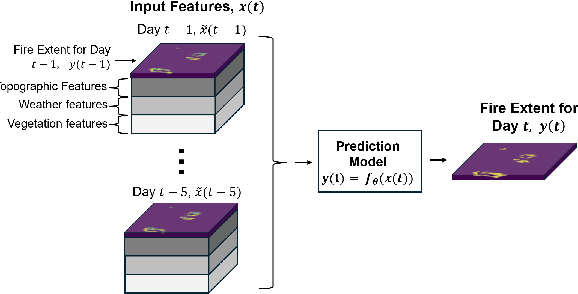
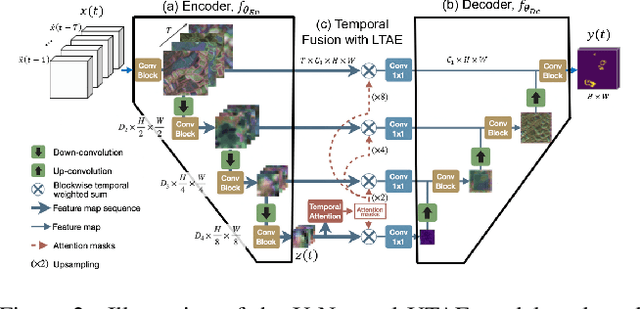

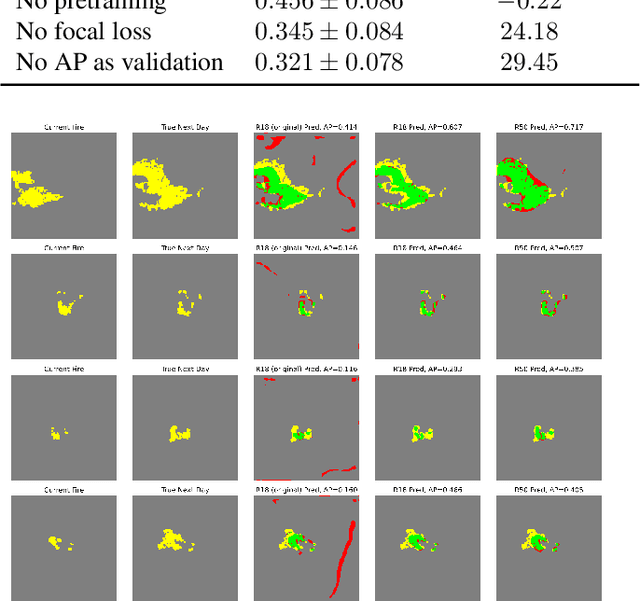
Recent research has demonstrated the potential of deep neural networks (DNNs) to accurately predict next-day wildfire spread, based upon the current extent of a fire and geospatial rasters of influential environmental covariates e.g., vegetation, topography, climate, and weather. In this work, we investigate a recent transformer-based model, termed the SwinUnet, for next-day wildfire prediction. We benchmark Swin-based models against several current state-of-the-art models on WildfireSpreadTS (WFTS), a large public benchmark dataset of historical wildfire events. We consider two next-day fire prediction scenarios: when the model is given input of (i) a single previous day of data, or (ii) five previous days of data. We find that, with the proper modifications, SwinUnet achieves state-of-the-art accuracy on next-day prediction for both the single-day and multi-day scenarios. SwinUnet's success depends heavily upon utilizing pre-trained weights from ImageNet. Consistent with prior work, we also found that models with multi-day-input always outperformed models with single-day input.
Deep, Skinny Neural Networks are not Universal Approximators
Sep 30, 2018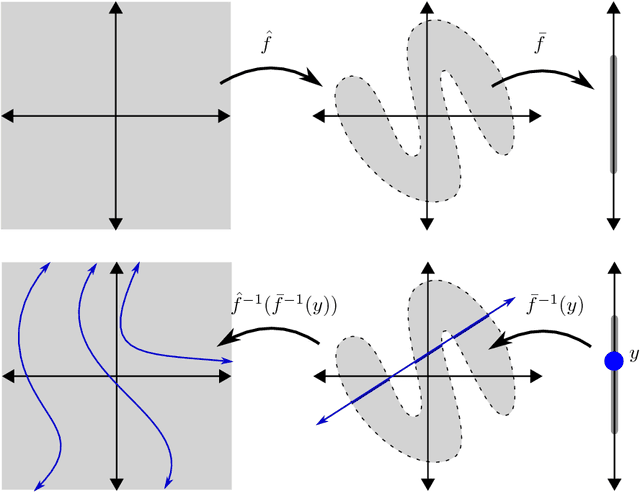
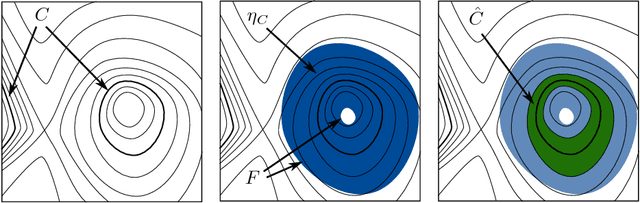
In order to choose a neural network architecture that will be effective for a particular modeling problem, one must understand the limitations imposed by each of the potential options. These limitations are typically described in terms of information theoretic bounds, or by comparing the relative complexity needed to approximate example functions between different architectures. In this paper, we examine the topological constraints that the architecture of a neural network imposes on the level sets of all the functions that it is able to approximate. This approach is novel for both the nature of the limitations and the fact that they are independent of network depth for a broad family of activation functions.
An application of topological graph clustering to protein function prediction
Aug 24, 2014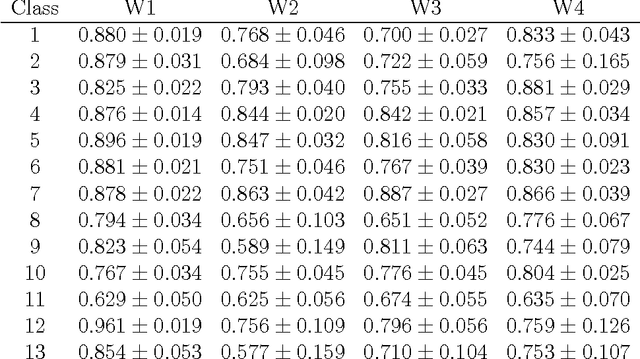
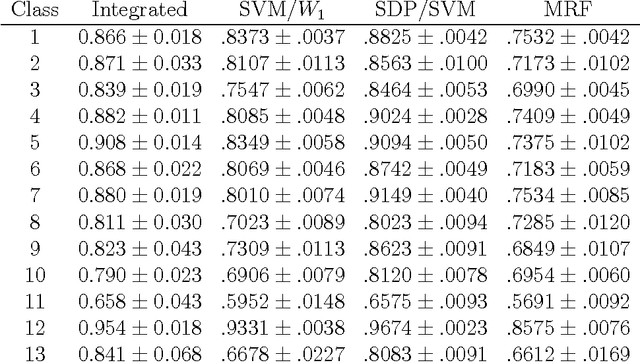
We use a semisupervised learning algorithm based on a topological data analysis approach to assign functional categories to yeast proteins using similarity graphs. This new approach to analyzing biological networks yields results that are as good as or better than state of the art existing approaches.
Topological graph clustering with thin position
Jun 04, 2012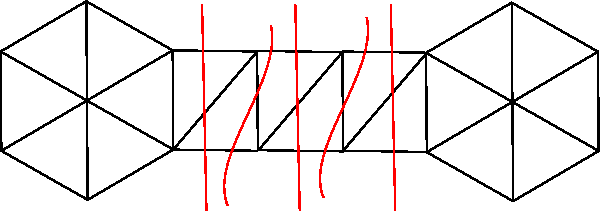
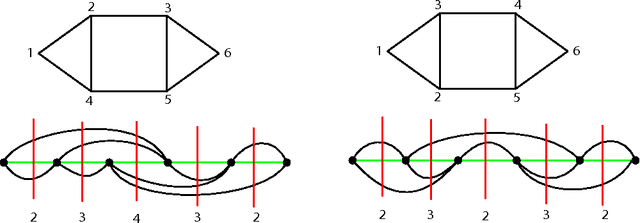
A clustering algorithm partitions a set of data points into smaller sets (clusters) such that each subset is more tightly packed than the whole. Many approaches to clustering translate the vector data into a graph with edges reflecting a distance or similarity metric on the points, then look for highly connected subgraphs. We introduce such an algorithm based on ideas borrowed from the topological notion of thin position for knots and 3-dimensional manifolds.