 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Deep Learning Models Robust to Partial Object Occlusion in Visual Recognition Tasks?
Sep 16, 2024
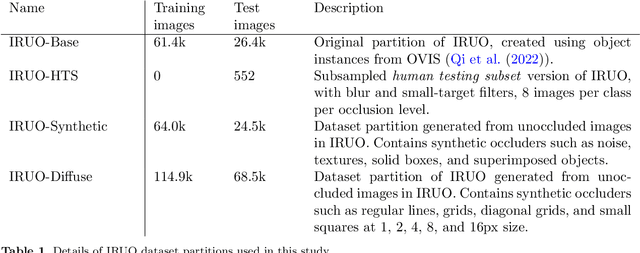

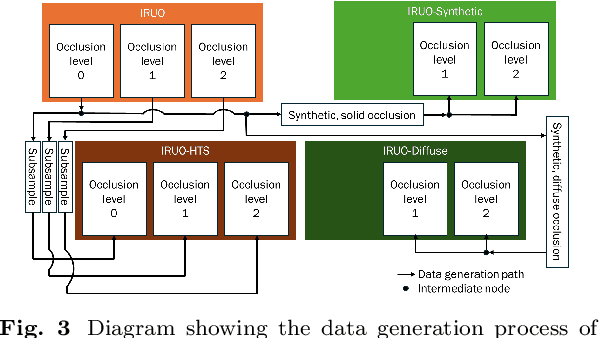
Image classification models, including convolutional neural networks (CNNs), perform well on a variety of classification tasks but struggle under conditions of partial occlusion, i.e., conditions in which objects are partially covered from the view of a camera. Methods to improve performance under occlusion, including data augmentation, part-based clustering, and more inherently robust architectures, including Vision Transformer (ViT) models, have, to some extent, been evaluated on their ability to classify objects under partial occlusion. However, evaluations of these methods have largely relied on images containing artificial occlusion, which are typically computer-generated and therefore inexpensive to label. Additionally, methods are rarely compared against each other, and many methods are compared against early, now outdated, deep learning models. We contribute the Image Recognition Under Occlusion (IRUO) dataset, based on the recently developed Occluded Video Instance Segmentation (OVIS) dataset (arXiv:2102.01558). IRUO utilizes real-world and artificially occluded images to test and benchmark leading methods' robustness to partial occlusion in visual recognition tasks. In addition, we contribute the design and results of a human study using images from IRUO that evaluates human classification performance at multiple levels and types of occlusion. We find that modern CNN-based models show improved recognition accuracy on occluded images compared to earlier CNN-based models, and ViT-based models are more accurate than CNN-based models on occluded images, performing only modestly worse than human accuracy. We also find that certain types of occlusion, including diffuse occlusion, where relevant objects are seen through "holes" in occluders such as fences and leaves, can greatly reduce the accuracy of deep recognition models as compared to humans, especially those with CNN backbones.
Segment anything, from space?
May 15, 2023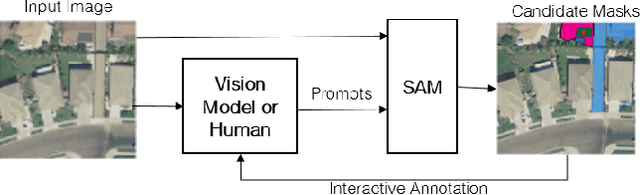

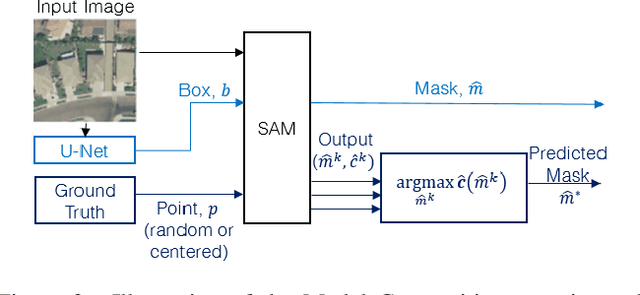
Recently, the first foundation model developed specifically for vision tasks was developed, termed the "Segment Anything Model" (SAM). SAM can segment objects in input imagery based upon cheap input prompts, such as one (or more) points, a bounding box, or a mask. The authors examined the zero-shot image segmentation accuracy of SAM on a large number of vision benchmark tasks and found that SAM usually achieved recognition accuracy similar to, or sometimes exceeding, vision models that had been trained on the target tasks. The impressive generalization of SAM for segmentation has major implications for vision researchers working on natural imagery. In this work, we examine whether SAM's impressive performance extends to overhead imagery problems, and help guide the community's response to its development. We examine SAM's performance on a set of diverse and widely-studied benchmark tasks. We find that SAM does often generalize well to overhead imagery, although it fails in some cases due to the unique characteristics of overhead imagery and the target objects. We report on these unique systematic failure cases for remote sensing imagery that may comprise useful future research for the community. Note that this is a working paper, and it will be updated as additional analysis and results are completed.
Meta-Learning for Color-to-Infrared Cross-Modal Style Transfer
Dec 24, 2022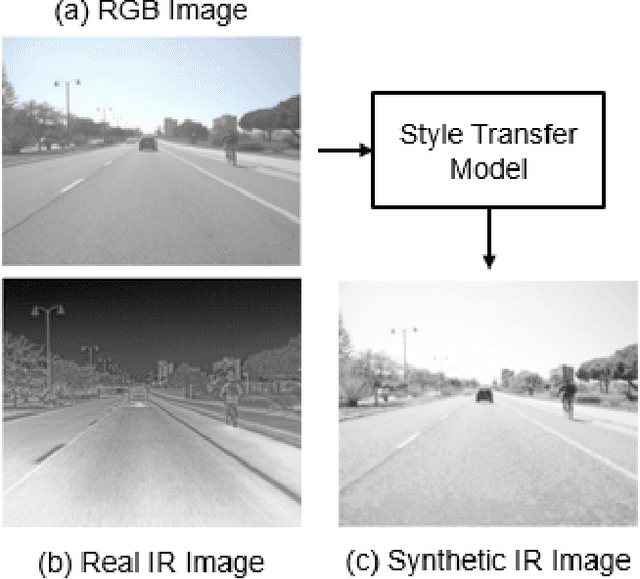


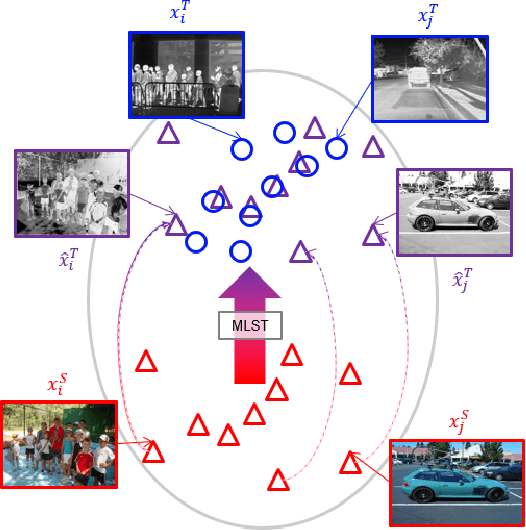
Recent object detection models for infrared (IR) imagery are based upon deep neural networks (DNNs) and require large amounts of labeled training imagery. However, publicly-available datasets that can be used for such training are limited in their size and diversity. To address this problem, we explore cross-modal style transfer (CMST) to leverage large and diverse color imagery datasets so that they can be used to train DNN-based IR image based object detectors. We evaluate six contemporary stylization methods on four publicly-available IR datasets - the first comparison of its kind - and find that CMST is highly effective for DNN-based detectors. Surprisingly, we find that existing data-driven methods are outperformed by a simple grayscale stylization (an average of the color channels). Our analysis reveals that existing data-driven methods are either too simplistic or introduce significant artifacts into the imagery. To overcome these limitations, we propose meta-learning style transfer (MLST), which learns a stylization by composing and tuning well-behaved analytic functions. We find that MLST leads to more complex stylizations without introducing significant image artifacts and achieves the best overall detector performance on our benchmark datasets.
Mixture Manifold Networks: A Computationally Efficient Baseline for Inverse Modeling
Nov 25, 2022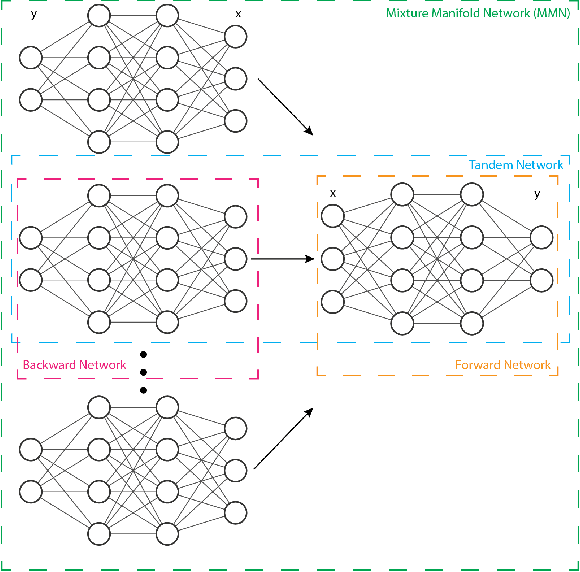
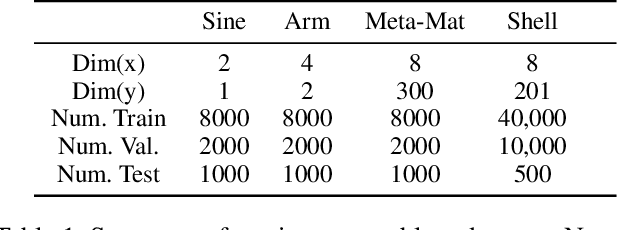
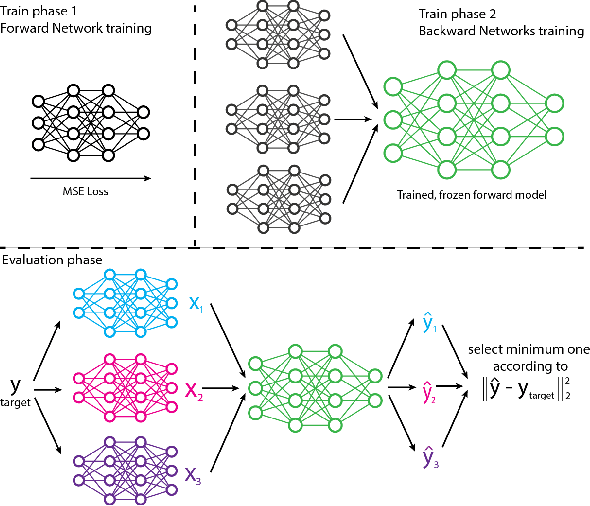
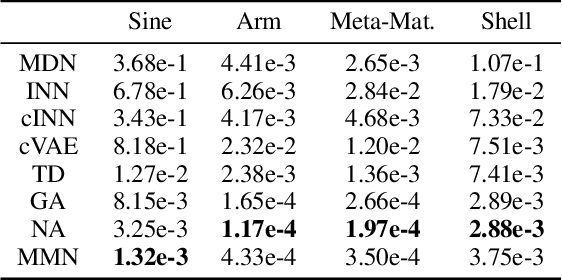
We propose and show the efficacy of a new method to address generic inverse problems. Inverse modeling is the task whereby one seeks to determine the control parameters of a natural system that produce a given set of observed measurements. Recent work has shown impressive results using deep learning, but we note that there is a trade-off between model performance and computational time. For some applications, the computational time at inference for the best performing inverse modeling method may be overly prohibitive to its use. We present a new method that leverages multiple manifolds as a mixture of backward (e.g., inverse) models in a forward-backward model architecture. These multiple backwards models all share a common forward model, and their training is mitigated by generating training examples from the forward model. The proposed method thus has two innovations: 1) the multiple Manifold Mixture Network (MMN) architecture, and 2) the training procedure involving augmenting backward model training data using the forward model. We demonstrate the advantages of our method by comparing to several baselines on four benchmark inverse problems, and we furthermore provide analysis to motivate its design.
Meta-simulation for the Automated Design of Synthetic Overhead Imagery
Sep 19, 2022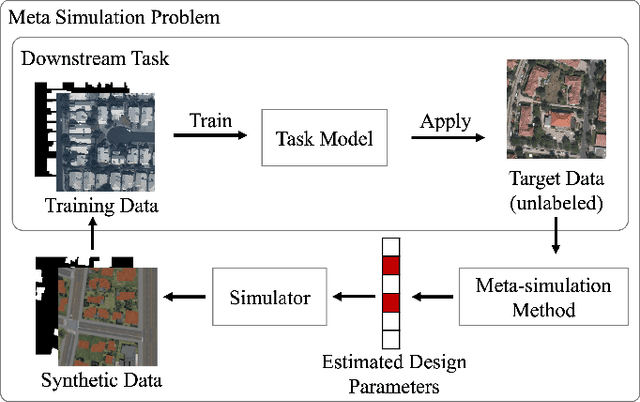



The use of synthetic (or simulated) data for training machine learning models has grown rapidly in recent years. Synthetic data can often be generated much faster and more cheaply than its real-world counterpart. One challenge of using synthetic imagery however is scene design: e.g., the choice of content and its features and spatial arrangement. To be effective, this design must not only be realistic, but appropriate for the target domain, which (by assumption) is unlabeled. In this work, we propose an approach to automatically choose the design of synthetic imagery based upon unlabeled real-world imagery. Our approach, termed Neural-Adjoint Meta-Simulation (NAMS), builds upon the seminal recent meta-simulation approaches. In contrast to the current state-of-the-art methods, our approach can be pre-trained once offline, and then provides fast design inference for new target imagery. Using both synthetic and real-world problems, we show that NAMS infers synthetic designs that match both the in-domain and out-of-domain target imagery, and that training segmentation models with NAMS-designed imagery yields superior results compared to na\"ive randomized designs and state-of-the-art meta-simulation methods.
Parameter Tuning of Time-Frequency Masking Algorithms for Reverberant Artifact Removal within the Cochlear Implant Stimulus
Aug 12, 2021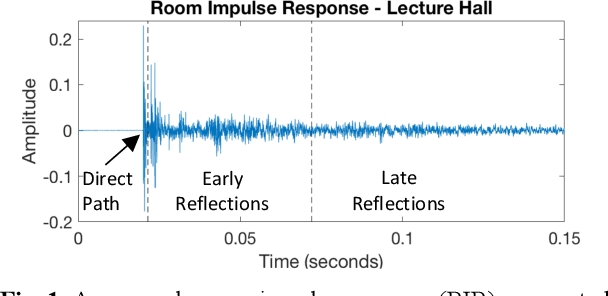
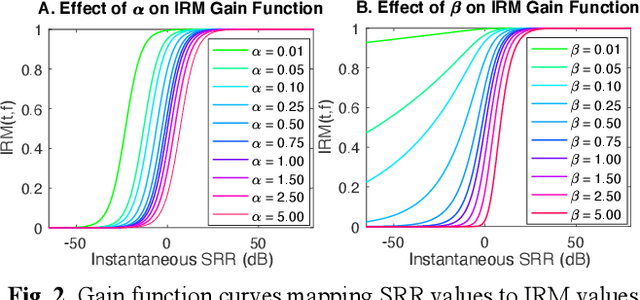
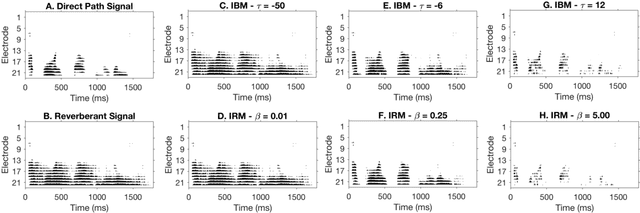
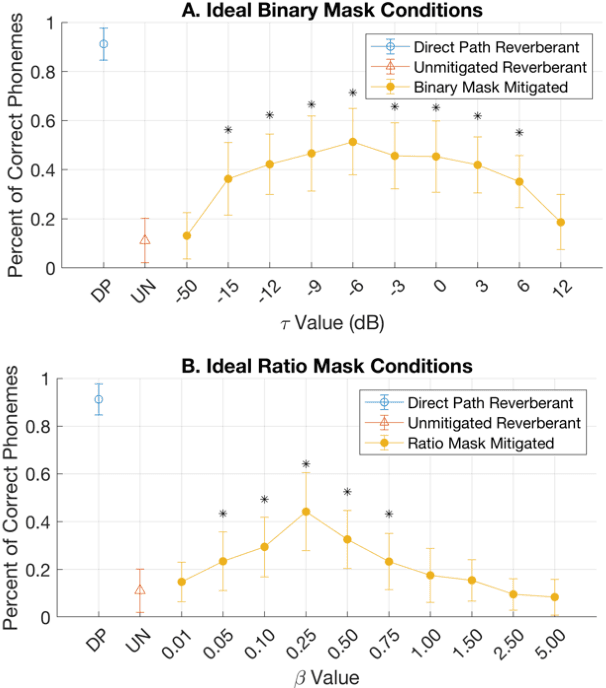
Cochlear implant users struggle to understand speech in reverberant environments. To restore speech perception, artifacts dominated by reverberant reflections can be removed from the cochlear implant stimulus. Artifacts can be identified and removed by applying a matrix of gain values, a technique referred to as time-frequency masking. Gain values are determined by an oracle algorithm that uses knowledge of the undistorted signal to minimize retention of the signal components dominated by reverberant reflections. In practice, gain values are estimated from the distorted signal, with the oracle algorithm providing the estimation objective. Different oracle techniques exist for determining gain values, and each technique must be parameterized to set the amount of signal retention. This work assesses which oracle masking strategies and parameterizations lead to the best improvements in speech intelligibility for cochlear implant users in reverberant conditions using online speech intelligibility testing of normal-hearing individuals with vocoding.
Phoneme-Based Ratio Mask Estimation for Reverberant Speech Enhancement in Cochlear Implant Processors
May 28, 2021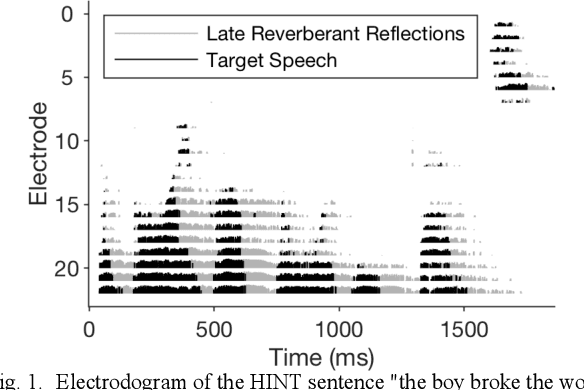
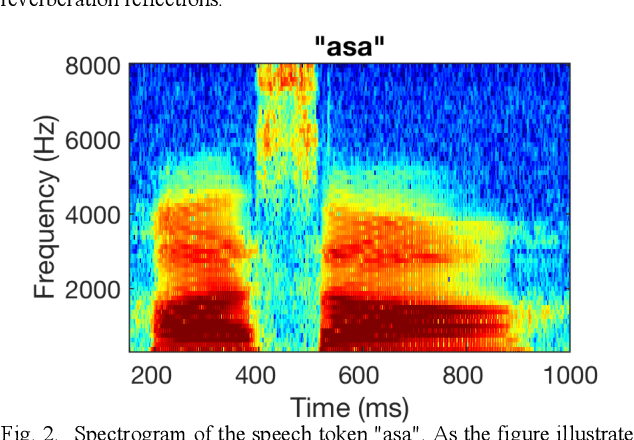
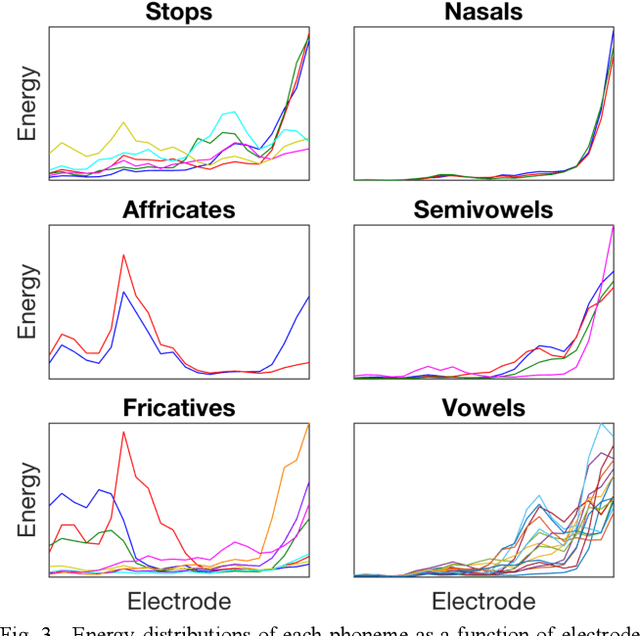
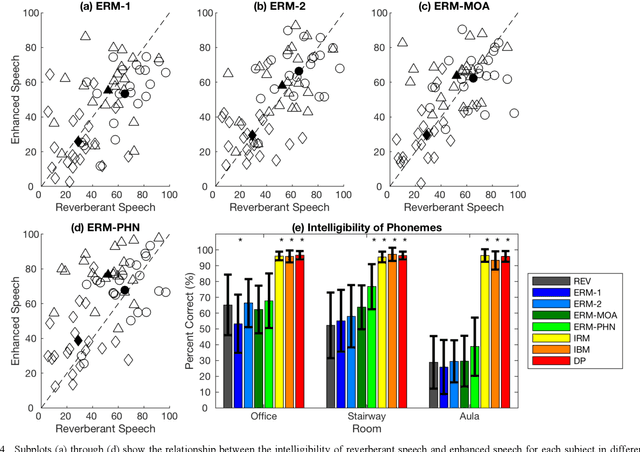
Cochlear implant (CI) users have considerable difficulty in understanding speech in reverberant listening environments. Time-frequency (T-F) masking is a common technique that aims to improve speech intelligibility by multiplying reverberant speech by a matrix of gain values to suppress T-F bins dominated by reverberation. Recently proposed mask estimation algorithms leverage machine learning approaches to distinguish between target speech and reverberant reflections. However, the spectro-temporal structure of speech is highly variable and dependent on the underlying phoneme. One way to potentially overcome this variability is to leverage explicit knowledge of phonemic information during mask estimation. This study proposes a phoneme-based mask estimation algorithm, where separate mask estimation models are trained for each phoneme. Sentence recognition tests were conducted in normal hearing listeners to determine whether a phoneme-based mask estimation algorithm is beneficial in the ideal scenario where perfect knowledge of the phoneme is available. The results showed that the phoneme-based masks improved the intelligibility of vocoded speech when compared to conventional phoneme-independent masks. The results suggest that a phoneme-based speech enhancement strategy may potentially benefit CI users in reverberant listening environments.
Assessing the intelligibility of vocoded speech using a remote testing framework
May 28, 2021
Over the past year, remote speech intelligibility testing has become a popular and necessary alternative to traditional in-person experiments due to the need for physical distancing during the COVID-19 pandemic. A remote framework was developed for conducting speech intelligibility tests with normal hearing listeners. In this study, subjects used their personal computers to complete sentence recognition tasks in anechoic and reverberant listening environments. The results obtained using this remote framework were compared with previously collected in-lab results, and showed higher levels of speech intelligibility among remote study participants than subjects who completed the test in the laboratory.
Evaluating the Effect of Longitudinal Dose and INR Data on Maintenance Warfarin Dose Predictions
May 06, 2021
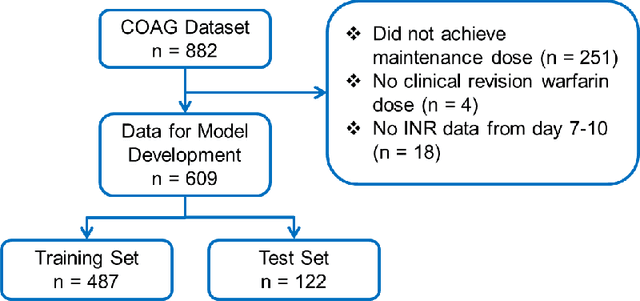
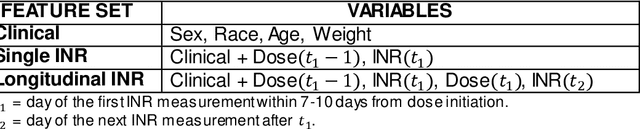
Warfarin, a commonly prescribed drug to prevent blood clots, has a highly variable individual response. Determining a maintenance warfarin dose that achieves a therapeutic blood clotting time, as measured by the international normalized ratio (INR), is crucial in preventing complications. Machine learning algorithms are increasingly being used for warfarin dosing; usually, an initial dose is predicted with clinical and genotype factors, and this dose is revised after a few days based on previous doses and current INR. Since a sequence of prior doses and INR better capture the variability in individual warfarin response, we hypothesized that longitudinal dose response data will improve maintenance dose predictions. To test this hypothesis, we analyzed a dataset from the COAG warfarin dosing study, which includes clinical data, warfarin doses and INR measurements over the study period, and maintenance dose when therapeutic INR was achieved. Various machine learning regression models to predict maintenance warfarin dose were trained with clinical factors and dosing history and INR data as features. Overall, dose revision algorithms with a single dose and INR achieved comparable performance as the baseline dose revision algorithm. In contrast, dose revision algorithms with longitudinal dose and INR data provided maintenance dose predictions that were statistically significantly much closer to the true maintenance dose. Focusing on the best performing model, gradient boosting (GB), the proportion of ideal estimated dose, i.e., defined as within $\pm$20% of the true dose, increased from the baseline (54.92%) to the GB model with the single (63.11%) and longitudinal (75.41%) INR. More accurate maintenance dose predictions with longitudinal dose response data can potentially achieve therapeutic INR faster, reduce drug-related complications and improve patient outcomes with warfarin therapy.
GridTracer: Automatic Mapping of Power Grids using Deep Learning and Overhead Imagery
Jan 16, 2021
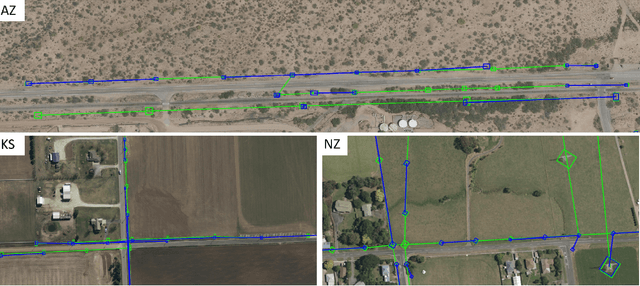

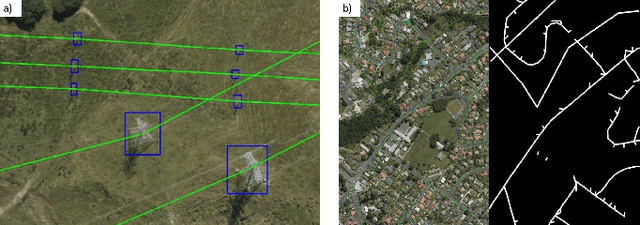
Energy system information valuable for electricity access planning such as the locations and connectivity of electricity transmission and distribution towers, termed the power grid, is often incomplete, outdated, or altogether unavailable. Furthermore, conventional means for collecting this information is costly and limited. We propose to automatically map the grid in overhead remotely sensed imagery using deep learning. Towards this goal, we develop and publicly-release a large dataset ($263km^2$) of overhead imagery with ground truth for the power grid, to our knowledge this is the first dataset of its kind in the public domain. Additionally, we propose scoring metrics and baseline algorithms for two grid mapping tasks: (1) tower recognition and (2) power line interconnection (i.e., estimating a graph representation of the grid). We hope the availability of the training data, scoring metrics, and baselines will facilitate rapid progress on this important problem to help decision-makers address the energy needs of societies around the world.