 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Framework for Bearing Fault Diagnosis
Nov 05, 2024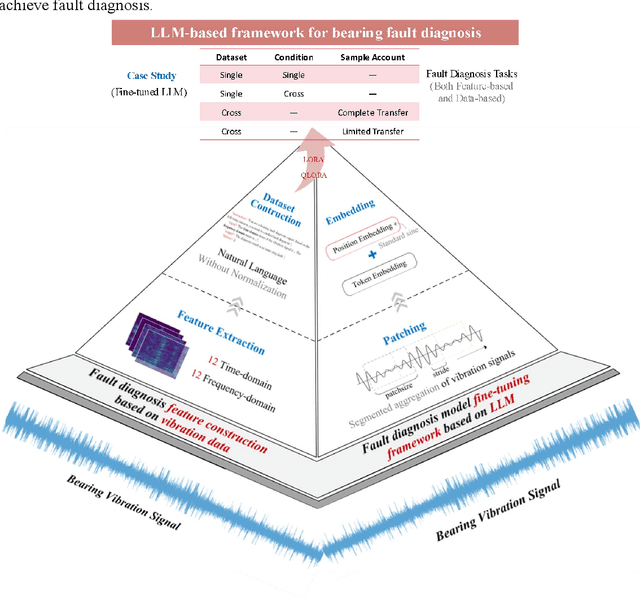



Accurately diagnosing bearing faults is crucial for maintaining the efficient operation of rotating machinery. However, traditional diagnosis methods face challenges due to the diversification of application environments, including cross-condition adaptability, small-sample learning difficulties, and cross-dataset generalization. These challenges have hindered the effectiveness and limited the application of existing approaches. Large language models (LLMs) offer new possibilities for improving the generalization of diagnosis models. However, the integration of LLMs with traditional diagnosis techniques for optimal generalization remains underexplored. This paper proposed an LLM-based bearing fault diagnosis framework to tackle these challenges. First, a signal feature quantification method was put forward to address the issue of extracting semantic information from vibration data, which integrated time and frequency domain feature extraction based on a statistical analysis framework. This method textualized time-series data, aiming to efficiently learn cross-condition and small-sample common features through concise feature selection. Fine-tuning methods based on LoRA and QLoRA were employed to enhance the generalization capability of LLMs in analyzing vibration data features. In addition, the two innovations (textualizing vibration features and fine-tuning pre-trained models) were validated by single-dataset cross-condition and cross-dataset transfer experiment with complete and limited data. The results demonstrated the ability of the proposed framework to perform three types of generalization tasks simultaneously. Trained cross-dataset models got approximately a 10% improvement in accuracy, proving the adaptability of LLMs to input patterns. Ultimately, the results effectively enhance the generalization capability and fill the research gap in using LLMs for bearing fault diagnosis.
SIMPL: Generating Synthetic Overhead Imagery to Address Zero-shot and Few-Shot Detection Problems
Jun 29, 2021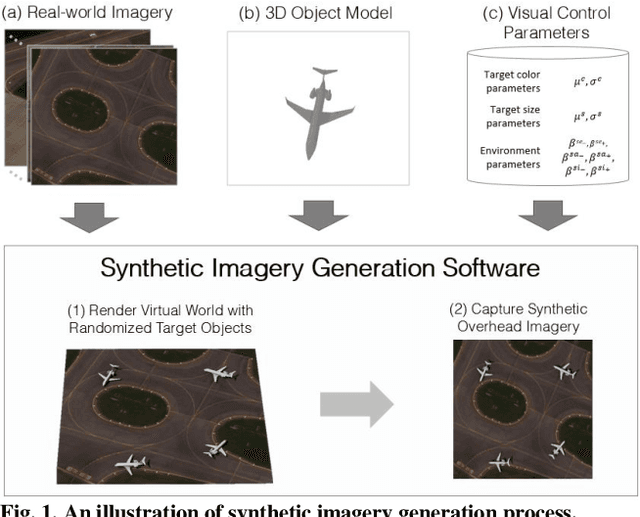
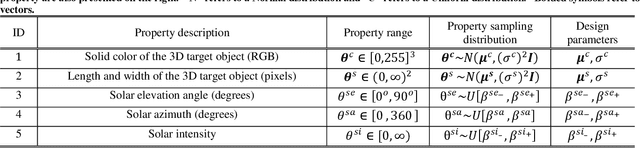

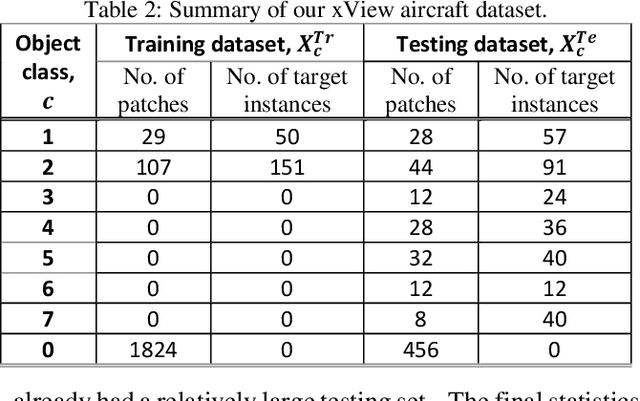
Recently deep neural networks (DNNs) have achieved tremendous success for object detection in overhead (e.g., satellite) imagery. One ongoing challenge however is the acquisition of training data, due to high costs of obtaining satellite imagery and annotating objects in it. In this work we present a simple approach - termed Synthetic object IMPLantation (SIMPL) - to easily and rapidly generate large quantities of synthetic overhead training data for custom target objects. We demonstrate the effectiveness of using SIMPL synthetic imagery for training DNNs in zero-shot scenarios where no real imagery is available; and few-shot learning scenarios, where limited real-world imagery is available. We also conduct experiments to study the sensitivity of SIMPL's effectiveness to some key design parameters, providing users for insights when designing synthetic imagery for custom objects. We release a software implementation of our SIMPL approach so that others can build upon it, or use it for their own custom problems.
Randomized Histogram Matching: A Simple Augmentation for Unsupervised Domain Adaptation in Overhead Imagery
Apr 30, 2021
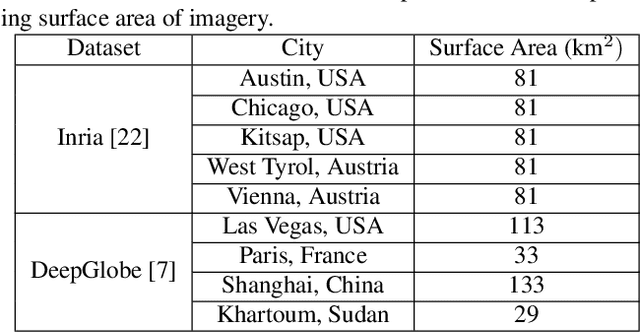
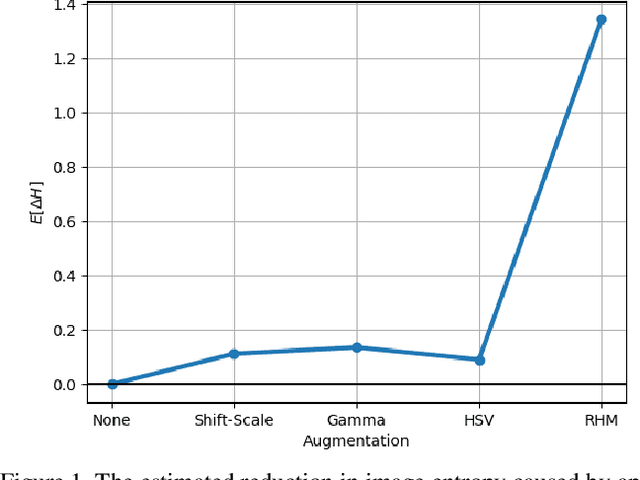
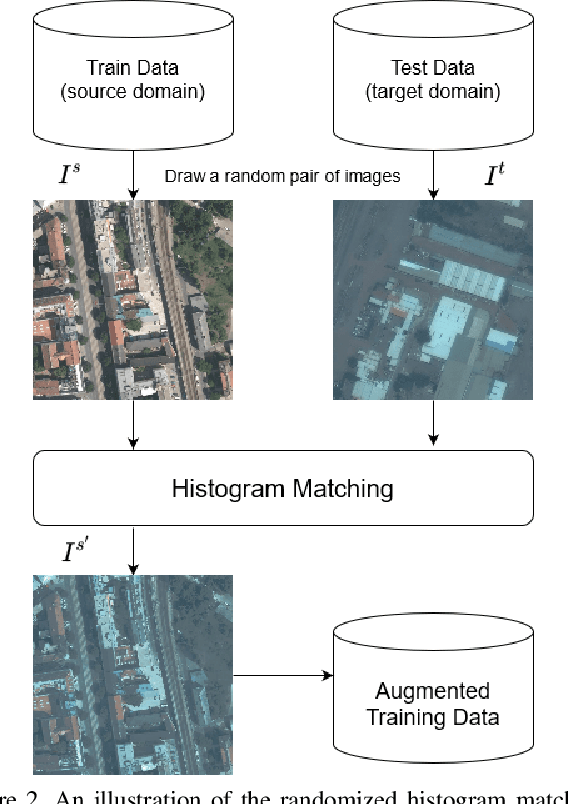
Modern deep neural networks (DNNs) achieve highly accurate results for many recognition tasks on overhead (e.g., satellite) imagery. One challenge however is visual domain shifts (i.e., statistical changes), which can cause the accuracy of DNNs to degrade substantially and unpredictably when tested on new sets of imagery. In this work we model domain shifts caused by variations in imaging hardware, lighting, and other conditions as non-linear pixel-wise transformations; and we show that modern DNNs can become largely invariant to these types of transformations, if provided with appropriate training data augmentation. In general, however, we do not know the transformation between two sets of imagery. To overcome this problem, we propose a simple real-time unsupervised training augmentation technique, termed randomized histogram matching (RHM). We conduct experiments with two large public benchmark datasets for building segmentation and find that RHM consistently yields comparable performance to recent state-of-the-art unsupervised domain adaptation approaches despite being simpler and faster. RHM also offers substantially better performance than other comparably simple approaches that are widely-used in overhead imagery.
GridTracer: Automatic Mapping of Power Grids using Deep Learning and Overhead Imagery
Jan 16, 2021
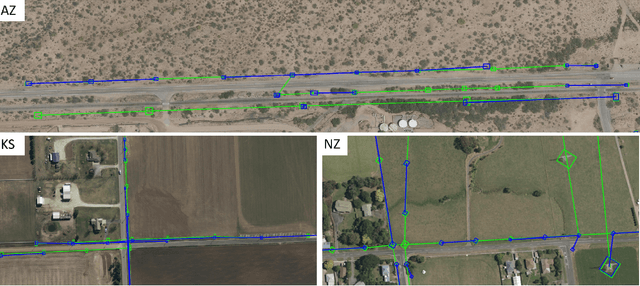

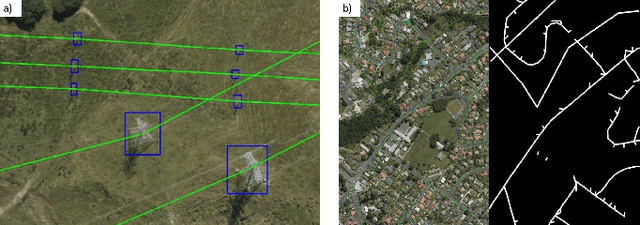
Energy system information valuable for electricity access planning such as the locations and connectivity of electricity transmission and distribution towers, termed the power grid, is often incomplete, outdated, or altogether unavailable. Furthermore, conventional means for collecting this information is costly and limited. We propose to automatically map the grid in overhead remotely sensed imagery using deep learning. Towards this goal, we develop and publicly-release a large dataset ($263km^2$) of overhead imagery with ground truth for the power grid, to our knowledge this is the first dataset of its kind in the public domain. Additionally, we propose scoring metrics and baseline algorithms for two grid mapping tasks: (1) tower recognition and (2) power line interconnection (i.e., estimating a graph representation of the grid). We hope the availability of the training data, scoring metrics, and baselines will facilitate rapid progress on this important problem to help decision-makers address the energy needs of societies around the world.
The Synthinel-1 dataset: a collection of high resolution synthetic overhead imagery for building segmentation
Jan 15, 2020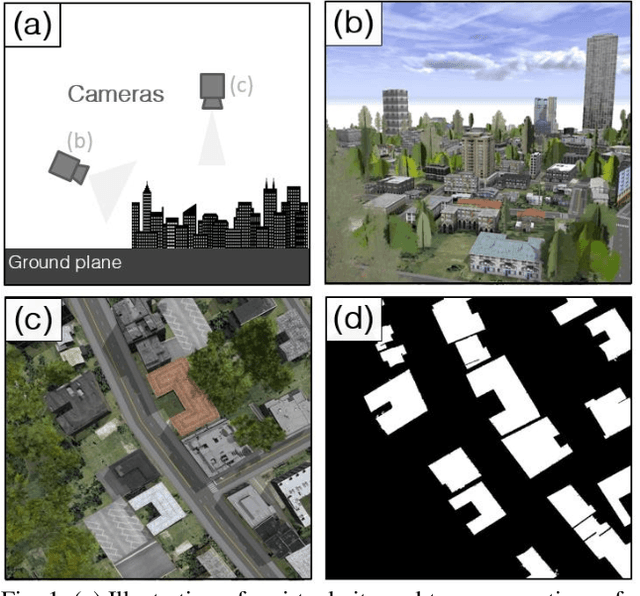
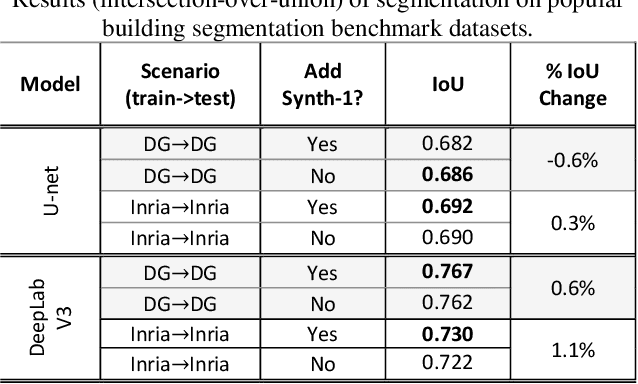

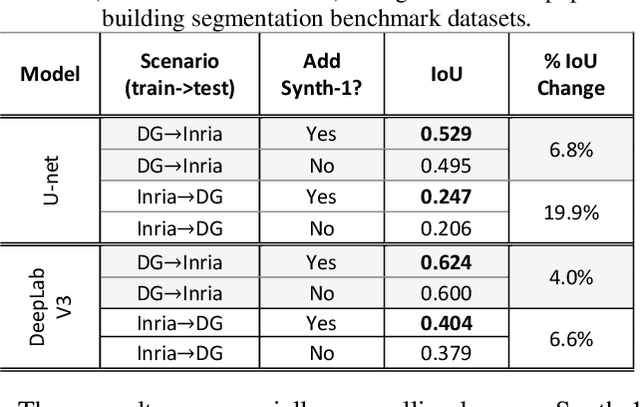
Recently deep learning - namely convolutional neural networks (CNNs) - have yielded impressive performance for the task of building segmentation on large overhead (e.g., satellite) imagery benchmarks. However, these benchmark datasets only capture a small fraction of the variability present in real-world overhead imagery, limiting the ability to properly train, or evaluate, models for real-world application. Unfortunately, developing a dataset that captures even a small fraction of real-world variability is typically infeasible due to the cost of imagery, and manual pixel-wise labeling of the imagery. In this work we develop an approach to rapidly and cheaply generate large and diverse virtual environments from which we can capture synthetic overhead imagery for training segmentation CNNs. Using this approach, generate and publicly-release a collection of synthetic overhead imagery - termed Synthinel-1 with full pixel-wise building labels. We use several benchmark dataset to demonstrate that Synthinel-1 is consistently beneficial when used to augment real-world training imagery, especially when CNNs are tested on novel geographic locations or conditions.
Mapping solar array location, size, and capacity using deep learning and overhead imagery
Feb 28, 2019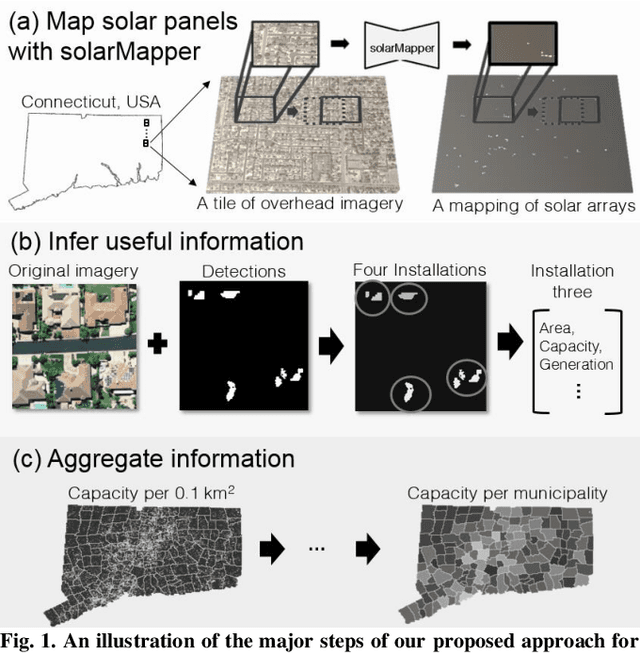

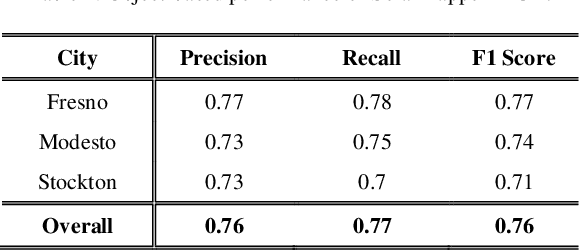
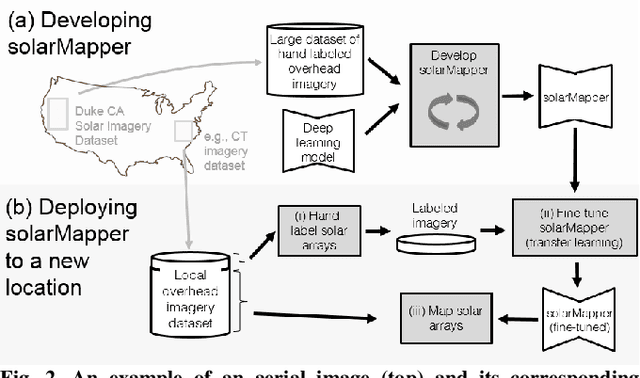
The effective integration of distributed solar photovoltaic (PV) arrays into existing power grids will require access to high quality data; the location, power capacity, and energy generation of individual solar PV installations. Unfortunately, existing methods for obtaining this data are limited in their spatial resolution and completeness. We propose a general framework for accurately and cheaply mapping individual PV arrays, and their capacities, over large geographic areas. At the core of this approach is a deep learning algorithm called SolarMapper - which we make publicly available - that can automatically map PV arrays in high resolution overhead imagery. We estimate the performance of SolarMapper on a large dataset of overhead imagery across three US cities in California. We also describe a procedure for deploying SolarMapper to new geographic regions, so that it can be utilized by others. We demonstrate the effectiveness of the proposed deployment procedure by using it to map solar arrays across the entire US state of Connecticut (CT). Using these results, we demonstrate that we achieve highly accurate estimates of total installed PV capacity within each of CT's 168 municipal regions.
Dense labeling of large remote sensing imagery with convolutional neural networks: a simple and faster alternative to stitching output label maps
May 30, 2018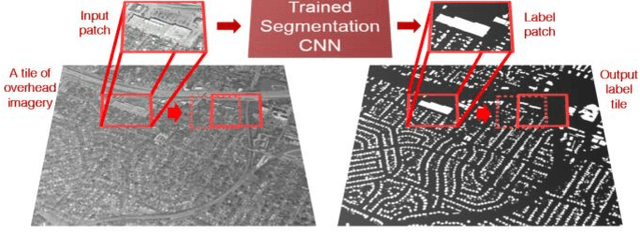
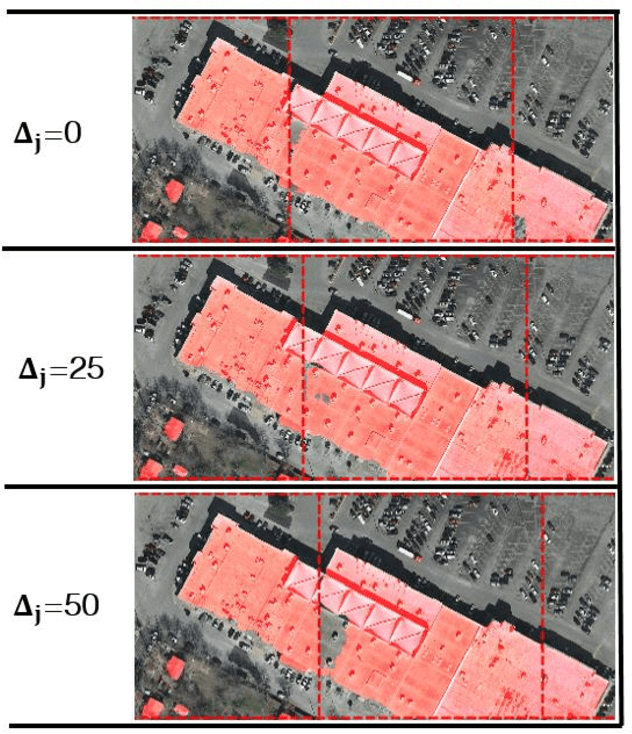
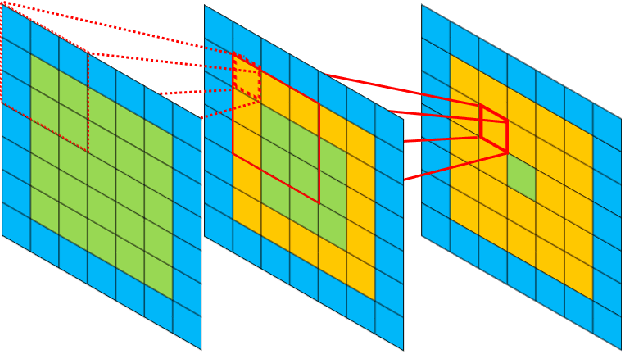
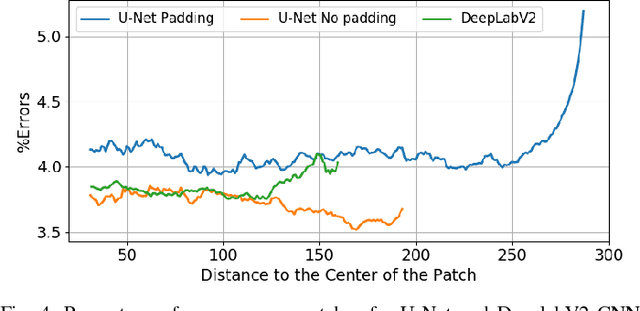
In this work we consider the application of convolutional neural networks (CNNs) for pixel-wise labeling (a.k.a., semantic segmentation) of remote sensing imagery (e.g., aerial color or hyperspectral imagery). Remote sensing imagery is usually stored in the form of very large images, referred to as "tiles", which are too large to be segmented directly using most CNNs and their associated hardware. As a result, during label inference, smaller sub-images, called "patches", are processed individually and then "stitched" (concatenated) back together to create a tile-sized label map. This approach suffers from computational ineffiency and can result in discontinuities at output boundaries. We propose a simple alternative approach in which the input size of the CNN is dramatically increased only during label inference. This does not avoid stitching altogether, but substantially mitigates its limitations. We evaluate the performance of the proposed approach against a vonventional stitching approach using two popular segmentation CNN models and two large-scale remote sensing imagery datasets. The results suggest that the proposed approach substantially reduces label inference time, while also yielding modest overall label accuracy increases. This approach contributed to our wining entry (overall performance) in the INRIA building labeling competition.