 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Training Task Diversity on In-Context Learning through the Lens of Low-Dimensional Subspaces
Jun 05, 2026The transformer's emergent ability to perform in-context learning (ICL) has sparked a wide range of studies designed to understand its underlying mechanisms. Existing works often study how training task diversity, defined either as the number of ICL training task vectors or as the number of function classes from which the task vectors are drawn, shapes both the learning dynamics and generalization capabilities of ICL. While both definitions have uncovered many interesting phenomena, many observations under the latter definition remain theoretically unexplained. This paper presents a minimal analytical model under which these phenomena provably emerge from the properties of the training data. By modeling the training task vectors as a mixture of low-rank Gaussians, we show how training task diversity, defined by the number of non-overlapping columns between subspaces that parameterize the covariance matrices, improves both the generalization and optimization trajectory of ICL with linear attention. In particular, we show that our model can explain (i) why training with task diversity shortens the ICL plateau and (ii) why ICL appears to achieve out-of-distribution generalization. We conclude by empirically demonstrating how our results extend to nonlinear transformers and nonlinear function classes. Overall, our work presents a tractable framework to unify existing observations.
Stochastic Sparse Attention for Memory-Bound Inference
May 03, 2026Autoregressive decoding becomes bandwidth-limited at long contexts, as generating each token requires reading all $n_k$ key and value vectors from KV cache. We present Stochastic Additive No-mulT Attention (SANTA), a method that sparsifies value-cache access by sampling $S \ll n_k$ indices from the post-softmax distribution and aggregates only those value rows. This yields an unbiased estimator of the post-softmax value aggregation while replacing value-stage multiply-accumulates with gather-and-add. We introduce stratified sampling to design variance-reduced, GPU-friendly variants, demonstrating $1.5\times$ decode-step attention kernel speedup over FlashInfer and FlashDecoding on an NVIDIA RTX 6000 Ada while matching baseline accuracy at 32k-token contexts. Finally, we propose Bernoulli $qK^\mathsf{T}$ sampling as a complementary technique to sparsify the score stage, reducing key-feature access through stochastic ternary queries. Both methods are orthogonal to upstream techniques such as ternary quantization, low-rank projections, and KV-cache compression. Together, they point toward sparse, multiplier-free, and energy-efficient inference. We open-source our kernels at: https://github.com/OPUSLab/SANTA.git
Emergent Low-Rank Training Dynamics in MLPs with Smooth Activations
Feb 05, 2026Recent empirical evidence has demonstrated that the training dynamics of large-scale deep neural networks occur within low-dimensional subspaces. While this has inspired new research into low-rank training, compression, and adaptation, theoretical justification for these dynamics in nonlinear networks remains limited. %compared to deep linear settings. To address this gap, this paper analyzes the learning dynamics of multi-layer perceptrons (MLPs) under gradient descent (GD). We demonstrate that the weight dynamics concentrate within invariant low-dimensional subspaces throughout training. Theoretically, we precisely characterize these invariant subspaces for two-layer networks with smooth nonlinear activations, providing insight into their emergence. Experimentally, we validate that this phenomenon extends beyond our theoretical assumptions. Leveraging these insights, we empirically show there exists a low-rank MLP parameterization that, when initialized within the appropriate subspaces, matches the classification performance of fully-parameterized counterparts on a variety of classification tasks.
MonarchAttention: Zero-Shot Conversion to Fast, Hardware-Aware Structured Attention
May 24, 2025Transformers have achieved state-of-the-art performance across various tasks, but suffer from a notable quadratic complexity in sequence length due to the attention mechanism. In this work, we propose MonarchAttention -- a novel approach to sub-quadratic attention approximation via Monarch matrices, an expressive class of structured matrices. Based on the variational form of softmax, we describe an efficient optimization-based algorithm to compute an approximate projection of softmax attention onto the class of Monarch matrices with $\Theta(N\sqrt{N} d)$ computational complexity and $\Theta(Nd)$ memory/IO complexity. Unlike previous approaches, MonarchAttention is both (1) transferable, yielding minimal performance loss with no additional training, even when replacing every attention layer of the transformer, and (2) hardware-efficient, utilizing the highest-throughput tensor core units on modern GPUs. With optimized kernels, MonarchAttention achieves substantial speed-ups in wall-time over FlashAttention-2: $1.4\times$ for shorter sequences $(N=256)$, $4.5\times$ for medium-length sequences $(N=4K)$, and $8.2\times$ for longer sequences $(N=16K)$. We demonstrate the quality of MonarchAttention on diverse tasks and architectures in vision and language problems, showing that it flexibly and accurately approximates softmax attention in a variety of contexts. Our code is available at https://github.com/cjyaras/monarch-attention.
Out-of-Distribution Generalization of In-Context Learning: A Low-Dimensional Subspace Perspective
May 20, 2025This work aims to demystify the out-of-distribution (OOD) capabilities of in-context learning (ICL) by studying linear regression tasks parameterized with low-rank covariance matrices. With such a parameterization, we can model distribution shifts as a varying angle between the subspace of the training and testing covariance matrices. We prove that a single-layer linear attention model incurs a test risk with a non-negligible dependence on the angle, illustrating that ICL is not robust to such distribution shifts. However, using this framework, we also prove an interesting property of ICL: when trained on task vectors drawn from a union of low-dimensional subspaces, ICL can generalize to any subspace within their span, given sufficiently long prompt lengths. This suggests that the OOD generalization ability of Transformers may actually stem from the new task lying within the span of those encountered during training. We empirically show that our results also hold for models such as GPT-2, and conclude with (i) experiments on how our observations extend to nonlinear function classes and (ii) results on how LoRA has the ability to capture distribution shifts.
An Overview of Low-Rank Structures in the Training and Adaptation of Large Models
Mar 25, 2025The rise of deep learning has revolutionized data processing and prediction in signal processing and machine learning, yet the substantial computational demands of training and deploying modern large-scale deep models present significant challenges, including high computational costs and energy consumption. Recent research has uncovered a widespread phenomenon in deep networks: the emergence of low-rank structures in weight matrices and learned representations during training. These implicit low-dimensional patterns provide valuable insights for improving the efficiency of training and fine-tuning large-scale models. Practical techniques inspired by this phenomenon, such as low-rank adaptation (LoRA) and training, enable significant reductions in computational cost while preserving model performance. In this paper, we present a comprehensive review of recent advances in exploiting low-rank structures for deep learning and shed light on their mathematical foundations. Mathematically, we present two complementary perspectives on understanding the low-rankness in deep networks: (i) the emergence of low-rank structures throughout the whole optimization dynamics of gradient and (ii) the implicit regularization effects that induce such low-rank structures at convergence. From a practical standpoint, studying the low-rank learning dynamics of gradient descent offers a mathematical foundation for understanding the effectiveness of LoRA in fine-tuning large-scale models and inspires parameter-efficient low-rank training strategies. Furthermore, the implicit low-rank regularization effect helps explain the success of various masked training approaches in deep neural networks, ranging from dropout to masked self-supervised learning.
Understanding How Nonlinear Layers Create Linearly Separable Features for Low-Dimensional Data
Jan 04, 2025



Deep neural networks have attained remarkable success across diverse classification tasks. Recent empirical studies have shown that deep networks learn features that are linearly separable across classes. However, these findings often lack rigorous justifications, even under relatively simple settings. In this work, we address this gap by examining the linear separation capabilities of shallow nonlinear networks. Specifically, inspired by the low intrinsic dimensionality of image data, we model inputs as a union of low-dimensional subspaces (UoS) and demonstrate that a single nonlinear layer can transform such data into linearly separable sets. Theoretically, we show that this transformation occurs with high probability when using random weights and quadratic activations. Notably, we prove this can be achieved when the network width scales polynomially with the intrinsic dimension of the data rather than the ambient dimension. Experimental results corroborate these theoretical findings and demonstrate that similar linear separation properties hold in practical scenarios beyond our analytical scope. This work bridges the gap between empirical observations and theoretical understanding of the separation capacity of nonlinear networks, offering deeper insights into model interpretability and generalization.
Explaining and Mitigating the Modality Gap in Contrastive Multimodal Learning
Dec 10, 2024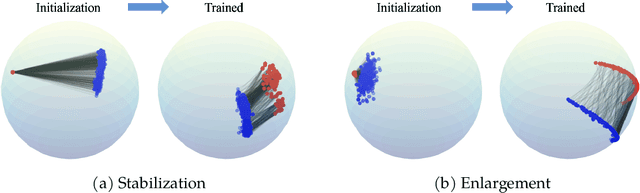

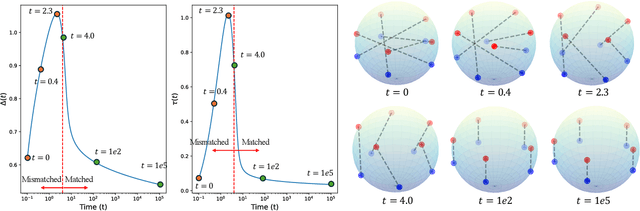
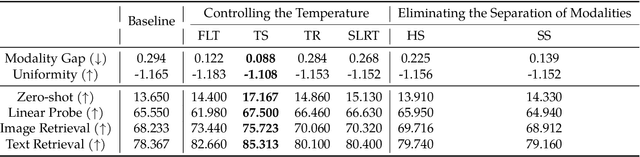
Multimodal learning has recently gained significant popularity, demonstrating impressive performance across various zero-shot classification tasks and a range of perceptive and generative applications. Models such as Contrastive Language-Image Pretraining (CLIP) are designed to bridge different modalities, such as images and text, by learning a shared representation space through contrastive learning. Despite their success, the working mechanisms underlying multimodal learning are not yet well understood. Notably, these models often exhibit a modality gap, where different modalities occupy distinct regions within the shared representation space. In this work, we conduct an in-depth analysis of the emergence of modality gap by characterizing the gradient flow learning dynamics. Specifically, we identify the critical roles of mismatched data pairs and a learnable temperature parameter in causing and perpetuating the modality gap during training. Furthermore, our theoretical insights are validated through experiments on practical CLIP models. These findings provide principled guidance for mitigating the modality gap, including strategies such as appropriate temperature scheduling and modality swapping. Additionally, we demonstrate that closing the modality gap leads to improved performance on tasks such as image-text retrieval.
Compressible Dynamics in Deep Overparameterized Low-Rank Learning & Adaptation
Jun 06, 2024While overparameterization in machine learning models offers great benefits in terms of optimization and generalization, it also leads to increased computational requirements as model sizes grow. In this work, we show that by leveraging the inherent low-dimensional structures of data and compressible dynamics within the model parameters, we can reap the benefits of overparameterization without the computational burdens. In practice, we demonstrate the effectiveness of this approach for deep low-rank matrix completion as well as fine-tuning language models. Our approach is grounded in theoretical findings for deep overparameterized low-rank matrix recovery, where we show that the learning dynamics of each weight matrix are confined to an invariant low-dimensional subspace. Consequently, we can construct and train compact, highly compressed factorizations possessing the same benefits as their overparameterized counterparts. In the context of deep matrix completion, our technique substantially improves training efficiency while retaining the advantages of overparameterization. For language model fine-tuning, we propose a method called "Deep LoRA", which improves the existing low-rank adaptation (LoRA) technique, leading to reduced overfitting and a simplified hyperparameter setup, while maintaining comparable efficiency. We validate the effectiveness of Deep LoRA on natural language tasks, particularly when fine-tuning with limited data.
Understanding Deep Representation Learning via Layerwise Feature Compression and Discrimination
Nov 06, 2023



Over the past decade, deep learning has proven to be a highly effective tool for learning meaningful features from raw data. However, it remains an open question how deep networks perform hierarchical feature learning across layers. In this work, we attempt to unveil this mystery by investigating the structures of intermediate features. Motivated by our empirical findings that linear layers mimic the roles of deep layers in nonlinear networks for feature learning, we explore how deep linear networks transform input data into output by investigating the output (i.e., features) of each layer after training in the context of multi-class classification problems. Toward this goal, we first define metrics to measure within-class compression and between-class discrimination of intermediate features, respectively. Through theoretical analysis of these two metrics, we show that the evolution of features follows a simple and quantitative pattern from shallow to deep layers when the input data is nearly orthogonal and the network weights are minimum-norm, balanced, and approximate low-rank: Each layer of the linear network progressively compresses within-class features at a geometric rate and discriminates between-class features at a linear rate with respect to the number of layers that data have passed through. To the best of our knowledge, this is the first quantitative characterization of feature evolution in hierarchical representations of deep linear networks. Empirically, our extensive experiments not only validate our theoretical results numerically but also reveal a similar pattern in deep nonlinear networks which aligns well with recent empirical studies. Moreover, we demonstrate the practical implications of our results in transfer learning. Our code is available at \url{https://github.com/Heimine/PNC_DLN}.