 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Acceleration of Block Low-Rank Foundation Models on Resource Constrained GPUs
Dec 24, 2025Recent advances in transformer-based foundation models have made them the default choice for many tasks, but their rapidly growing size makes fitting a full model on a single GPU increasingly difficult and their computational cost prohibitive. Block low-rank (BLR) compression techniques address this challenge by learning compact representations of weight matrices. While traditional low-rank (LR) methods often incur sharp accuracy drops, BLR approaches such as Monarch and BLAST can better capture the underlying structure, thus preserving accuracy while reducing computations and memory footprints. In this work, we use roofline analysis to show that, although BLR methods achieve theoretical savings and practical speedups for single-token inference, multi-token inference often becomes memory-bound in practice, increasing latency despite compiler-level optimizations in PyTorch. To address this, we introduce custom Triton kernels with partial fusion and memory layout optimizations for both Monarch and BLAST. On memory-constrained NVIDIA GPUs such as Jetson Orin Nano and A40, our kernels deliver up to $3.76\times$ speedups and $3\times$ model size compression over PyTorch dense baselines using CUDA backend and compiler-level optimizations, while supporting various models including Llama-7/1B, GPT2-S, DiT-XL/2, and ViT-B. Our code is available at https://github.com/pabillam/mem-efficient-blr .
MonarchAttention: Zero-Shot Conversion to Fast, Hardware-Aware Structured Attention
May 24, 2025Transformers have achieved state-of-the-art performance across various tasks, but suffer from a notable quadratic complexity in sequence length due to the attention mechanism. In this work, we propose MonarchAttention -- a novel approach to sub-quadratic attention approximation via Monarch matrices, an expressive class of structured matrices. Based on the variational form of softmax, we describe an efficient optimization-based algorithm to compute an approximate projection of softmax attention onto the class of Monarch matrices with $\Theta(N\sqrt{N} d)$ computational complexity and $\Theta(Nd)$ memory/IO complexity. Unlike previous approaches, MonarchAttention is both (1) transferable, yielding minimal performance loss with no additional training, even when replacing every attention layer of the transformer, and (2) hardware-efficient, utilizing the highest-throughput tensor core units on modern GPUs. With optimized kernels, MonarchAttention achieves substantial speed-ups in wall-time over FlashAttention-2: $1.4\times$ for shorter sequences $(N=256)$, $4.5\times$ for medium-length sequences $(N=4K)$, and $8.2\times$ for longer sequences $(N=16K)$. We demonstrate the quality of MonarchAttention on diverse tasks and architectures in vision and language problems, showing that it flexibly and accurately approximates softmax attention in a variety of contexts. Our code is available at https://github.com/cjyaras/monarch-attention.
BLAST: Block-Level Adaptive Structured Matrices for Efficient Deep Neural Network Inference
Oct 28, 2024
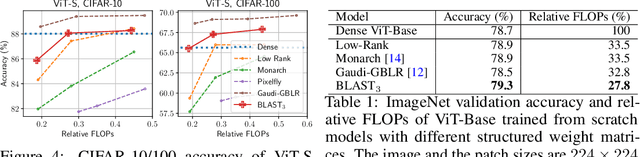
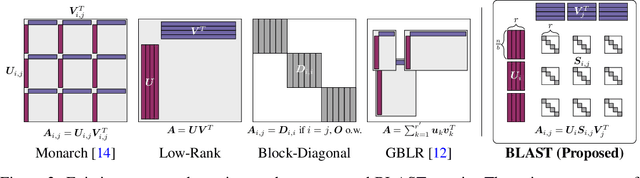
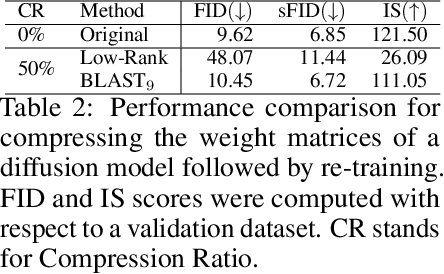
Large-scale foundation models have demonstrated exceptional performance in language and vision tasks. However, the numerous dense matrix-vector operations involved in these large networks pose significant computational challenges during inference. To address these challenges, we introduce the Block-Level Adaptive STructured (BLAST) matrix, designed to learn and leverage efficient structures prevalent in the weight matrices of linear layers within deep learning models. Compared to existing structured matrices, the BLAST matrix offers substantial flexibility, as it can represent various types of structures that are either learned from data or computed from pre-existing weight matrices. We demonstrate the efficiency of using the BLAST matrix for compressing both language and vision tasks, showing that (i) for medium-sized models such as ViT and GPT-2, training with BLAST weights boosts performance while reducing complexity by 70\% and 40\%, respectively; and (ii) for large foundation models such as Llama-7B and DiT-XL, the BLAST matrix achieves a 2x compression while exhibiting the lowest performance degradation among all tested structured matrices. Our code is available at \url{https://github.com/changwoolee/BLAST}.
Differentiable Learning of Generalized Structured Matrices for Efficient Deep Neural Networks
Oct 29, 2023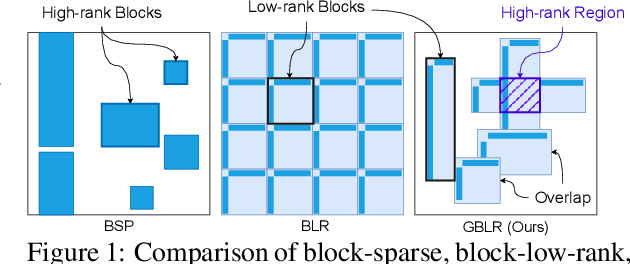
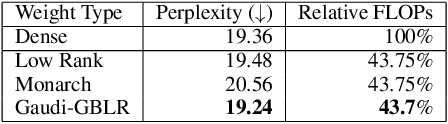
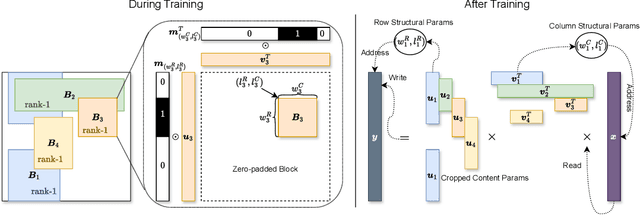
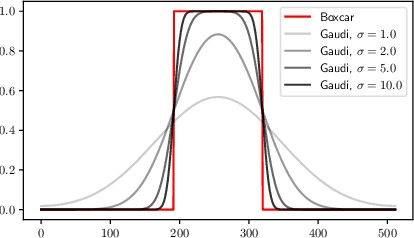
This paper investigates efficient deep neural networks (DNNs) to replace dense unstructured weight matrices with structured ones that possess desired properties. The challenge arises because the optimal weight matrix structure in popular neural network models is obscure in most cases and may vary from layer to layer even in the same network. Prior structured matrices proposed for efficient DNNs were mostly hand-crafted without a generalized framework to systematically learn them. To address this issue, we propose a generalized and differentiable framework to learn efficient structures of weight matrices by gradient descent. We first define a new class of structured matrices that covers a wide range of structured matrices in the literature by adjusting the structural parameters. Then, the frequency-domain differentiable parameterization scheme based on the Gaussian-Dirichlet kernel is adopted to learn the structural parameters by proximal gradient descent. Finally, we introduce an effective initialization method for the proposed scheme. Our method learns efficient DNNs with structured matrices, achieving lower complexity and/or higher performance than prior approaches that employ low-rank, block-sparse, or block-low-rank matrices.
Deep Joint Source-Channel Coding with Iterative Source Error Correction
Feb 17, 2023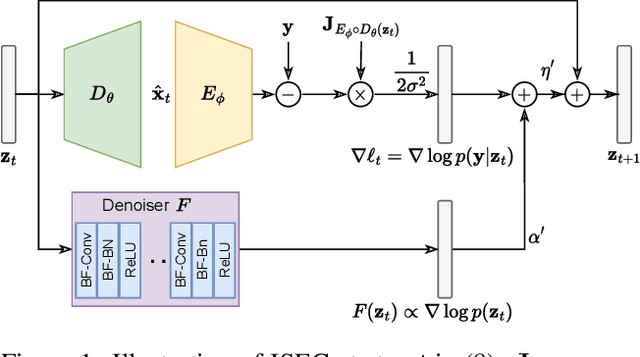
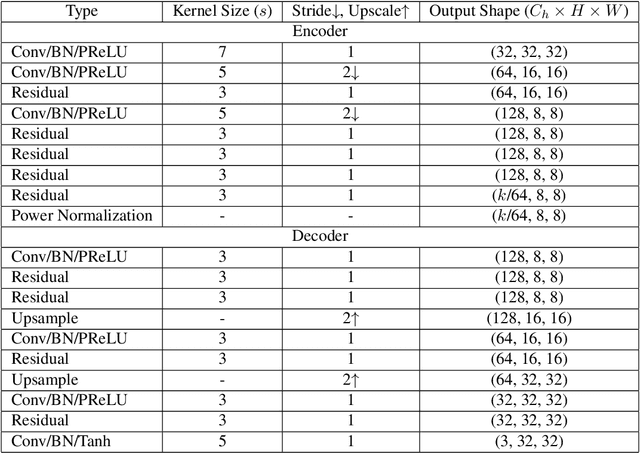

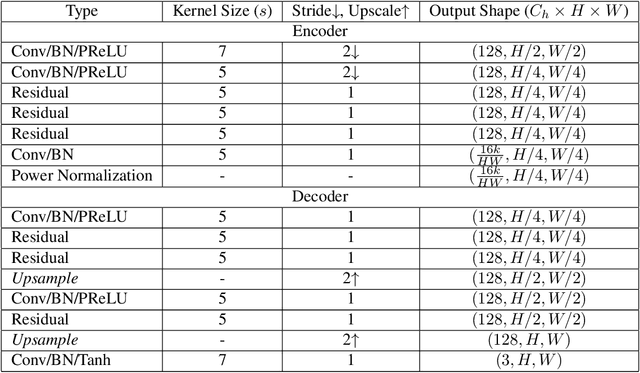
In this paper, we propose an iterative source error correction (ISEC) decoding scheme for deep-learning-based joint source-channel coding (Deep JSCC). Given a noisy codeword received through the channel, we use a Deep JSCC encoder and decoder pair to update the codeword iteratively to find a (modified) maximum a-posteriori (MAP) solution. For efficient MAP decoding, we utilize a neural network-based denoiser to approximate the gradient of the log-prior density of the codeword space. Albeit the non-convexity of the optimization problem, our proposed scheme improves various distortion and perceptual quality metrics from the conventional one-shot (non-iterative) Deep JSCC decoding baseline. Furthermore, the proposed scheme produces more reliable source reconstruction results compared to the baseline when the channel noise characteristics do not match the ones used during training.
Learning-Based Near-Orthogonal Superposition Code for MIMO Short Message Transmission
Jun 30, 2022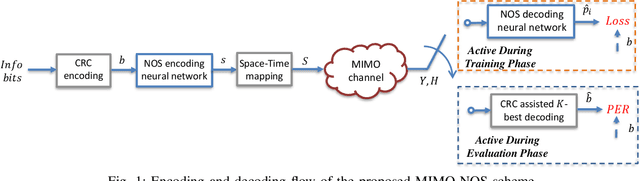
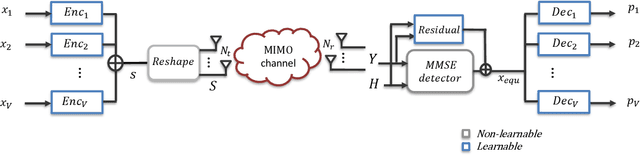
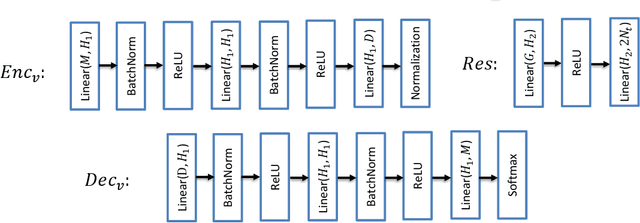
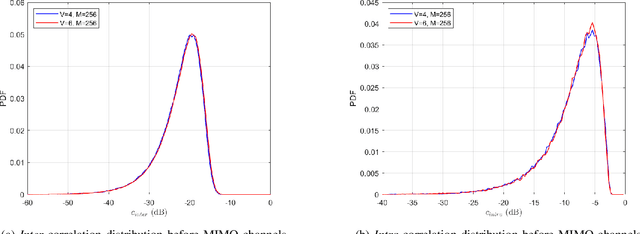
Massive machine type communication (mMTC) has attracted new coding schemes optimized for reliable short message transmission. In this paper, a novel deep learning-based near-orthogonal superposition (NOS) coding scheme is proposed to transmit short messages in multiple-input multiple-output (MIMO) channels for mMTC applications. In the proposed MIMO-NOS scheme, a neural network-based encoder is optimized via end-to-end learning with a corresponding neural network-based detector/decoder in a superposition-based auto-encoder framework including a MIMO channel. The proposed MIMO-NOS encoder spreads the information bits to multiple near-orthogonal high dimensional vectors to be combined (superimposed) into a single vector and reshaped for the space-time transmission. For the receiver, we propose a novel looped K-best tree-search algorithm with cyclic redundancy check (CRC) assistance to enhance the error correcting ability in the block-fading MIMO channel. Simulation results show the proposed MIMO-NOS scheme outperforms maximum likelihood (ML) MIMO detection combined with a polar code with CRC-assisted list decoding by 1-2 dB in various MIMO systems for short (32-64 bit) message transmission.
Unified Signal Compression Using a GAN with Iterative Latent Representation Optimization
Sep 23, 2021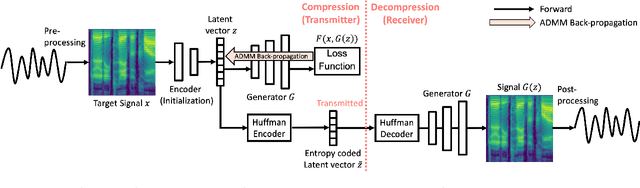

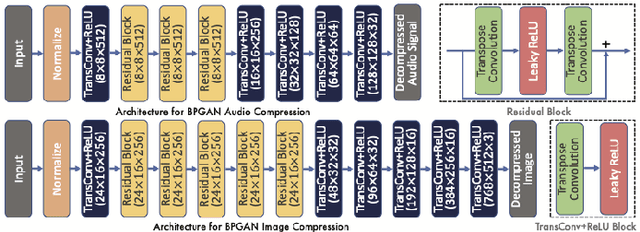

We propose a unified signal compression framework that uses a generative adversarial network (GAN) to compress heterogeneous signals. The compressed signal is represented as a latent vector and fed into a generator network that is trained to produce high quality realistic signals that minimize a target objective function. To efficiently quantize the compressed signal, non-uniformly quantized optimal latent vectors are identified by iterative back-propagation with alternating direction method of multipliers (ADMM) optimization performed for each iteration. The performance of the proposed signal compression method is assessed using multiple metrics including PSNR and MS-SSIM for image compression and also PESR, Kaldi, LSTM, and MLP performance for speech compression. Test results show that the proposed work outperforms recent state-of-the-art hand-crafted and deep learning-based signal compression methods.
A Confidence-Calibrated MOBA Game Winner Predictor
Jun 28, 2020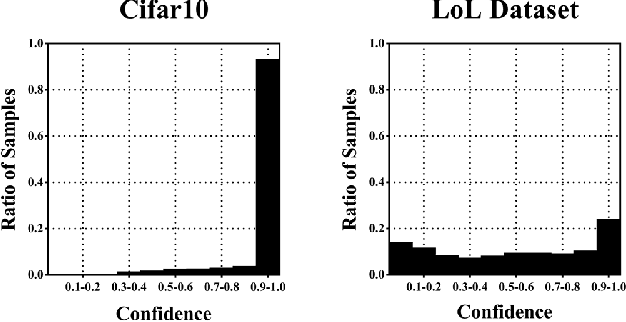
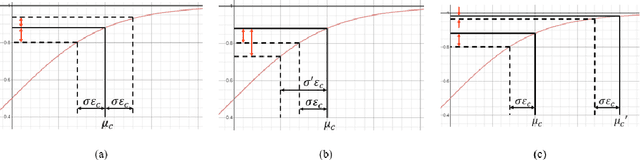
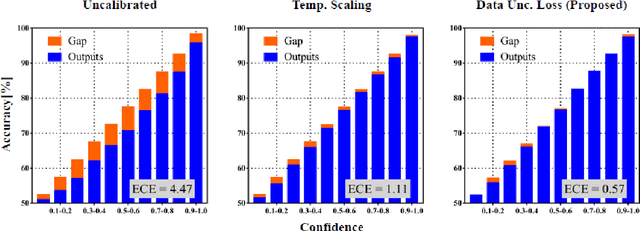
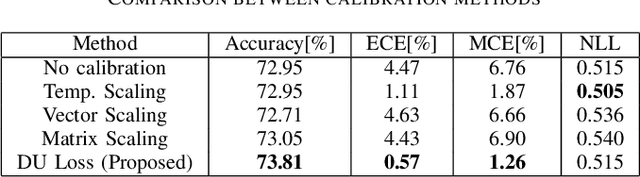
In this paper, we propose a confidence-calibration method for predicting the winner of a famous multiplayer online battle arena (MOBA) game, League of Legends. In MOBA games, the dataset may contain a large amount of input-dependent noise; not all of such noise is observable. Hence, it is desirable to attempt a confidence-calibrated prediction. Unfortunately, most existing confidence calibration methods are pertaining to image and document classification tasks where consideration on uncertainty is not crucial. In this paper, we propose a novel calibration method that takes data uncertainty into consideration. The proposed method achieves an outstanding expected calibration error (ECE) (0.57%) mainly owing to data uncertainty consideration, compared to a conventional temperature scaling method of which ECE value is 1.11%.