 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCP-SSM: Efficient Vision State Space Models with Token-Conditioned Poles
May 12, 2026State Space Models (SSMs) have emerged as a compelling alternative to attention models for long-range vision tasks, offering input-dependent recurrence with linear complexity. However, most efficient SSM variants reduce computation cost by modifying scan routes, resolutions, or traversal patterns, while largely leaving the recurrent dynamics implicit. Consequently, the model's state-dependent memory behavior is difficult to control, particularly in compact backbones where long scan paths can exceed the effective memory horizon. We propose Token-Conditioned Poles SSM (TCP-SSM), a structured selective SSM framework that improves efficiency while making recurrence dynamics explicit and interpretable through stable poles. TCP-SSM builds each scan operator with 1) real poles that model monotone or sign-alternating decay, and 2) complex-conjugate poles that capture damped oscillatory responses. Using bounded radius and angle modulation, TCP-SSM converts shared base poles into token-dependent poles, allowing each scan step to adapt its memory behavior to the current visual token while preserving pole stability. For practical scalability, we integrate grouped pole sharing with a lightweight low-rank input pathway, yielding an efficient scan operator that preserves linear-time scan complexity. Across image classification, semantic segmentation, and object detection, TCP-SSM reduces SSM computation complexity up to 44% in Vision Mamba-style models while maintaining or surpassing baseline accuracy.
Memory-Efficient Acceleration of Block Low-Rank Foundation Models on Resource Constrained GPUs
Dec 24, 2025Recent advances in transformer-based foundation models have made them the default choice for many tasks, but their rapidly growing size makes fitting a full model on a single GPU increasingly difficult and their computational cost prohibitive. Block low-rank (BLR) compression techniques address this challenge by learning compact representations of weight matrices. While traditional low-rank (LR) methods often incur sharp accuracy drops, BLR approaches such as Monarch and BLAST can better capture the underlying structure, thus preserving accuracy while reducing computations and memory footprints. In this work, we use roofline analysis to show that, although BLR methods achieve theoretical savings and practical speedups for single-token inference, multi-token inference often becomes memory-bound in practice, increasing latency despite compiler-level optimizations in PyTorch. To address this, we introduce custom Triton kernels with partial fusion and memory layout optimizations for both Monarch and BLAST. On memory-constrained NVIDIA GPUs such as Jetson Orin Nano and A40, our kernels deliver up to $3.76\times$ speedups and $3\times$ model size compression over PyTorch dense baselines using CUDA backend and compiler-level optimizations, while supporting various models including Llama-7/1B, GPT2-S, DiT-XL/2, and ViT-B. Our code is available at https://github.com/pabillam/mem-efficient-blr .
SAM-guided Pseudo Label Enhancement for Multi-modal 3D Semantic Segmentation
Feb 02, 2025



Multi-modal 3D semantic segmentation is vital for applications such as autonomous driving and virtual reality (VR). To effectively deploy these models in real-world scenarios, it is essential to employ cross-domain adaptation techniques that bridge the gap between training data and real-world data. Recently, self-training with pseudo-labels has emerged as a predominant method for cross-domain adaptation in multi-modal 3D semantic segmentation. However, generating reliable pseudo-labels necessitates stringent constraints, which often result in sparse pseudo-labels after pruning. This sparsity can potentially hinder performance improvement during the adaptation process. We propose an image-guided pseudo-label enhancement approach that leverages the complementary 2D prior knowledge from the Segment Anything Model (SAM) to introduce more reliable pseudo-labels, thereby boosting domain adaptation performance. Specifically, given a 3D point cloud and the SAM masks from its paired image data, we collect all 3D points covered by each SAM mask that potentially belong to the same object. Then our method refines the pseudo-labels within each SAM mask in two steps. First, we determine the class label for each mask using majority voting and employ various constraints to filter out unreliable mask labels. Next, we introduce Geometry-Aware Progressive Propagation (GAPP) which propagates the mask label to all 3D points within the SAM mask while avoiding outliers caused by 2D-3D misalignment. Experiments conducted across multiple datasets and domain adaptation scenarios demonstrate that our proposed method significantly increases the quantity of high-quality pseudo-labels and enhances the adaptation performance over baseline methods.
BLAST: Block-Level Adaptive Structured Matrices for Efficient Deep Neural Network Inference
Oct 28, 2024
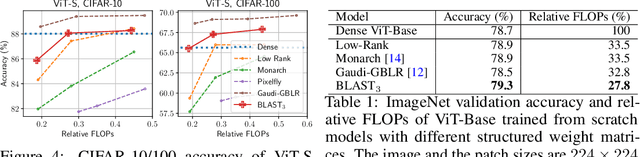
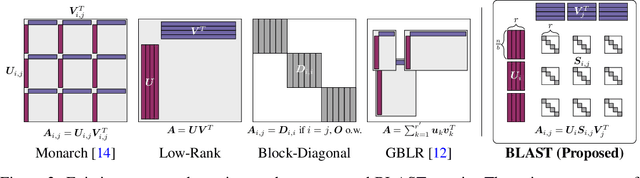
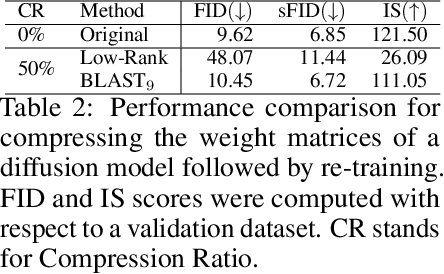
Large-scale foundation models have demonstrated exceptional performance in language and vision tasks. However, the numerous dense matrix-vector operations involved in these large networks pose significant computational challenges during inference. To address these challenges, we introduce the Block-Level Adaptive STructured (BLAST) matrix, designed to learn and leverage efficient structures prevalent in the weight matrices of linear layers within deep learning models. Compared to existing structured matrices, the BLAST matrix offers substantial flexibility, as it can represent various types of structures that are either learned from data or computed from pre-existing weight matrices. We demonstrate the efficiency of using the BLAST matrix for compressing both language and vision tasks, showing that (i) for medium-sized models such as ViT and GPT-2, training with BLAST weights boosts performance while reducing complexity by 70\% and 40\%, respectively; and (ii) for large foundation models such as Llama-7B and DiT-XL, the BLAST matrix achieves a 2x compression while exhibiting the lowest performance degradation among all tested structured matrices. Our code is available at \url{https://github.com/changwoolee/BLAST}.
Diffusion-Aided Joint Source Channel Coding For High Realism Wireless Image Transmission
Apr 27, 2024
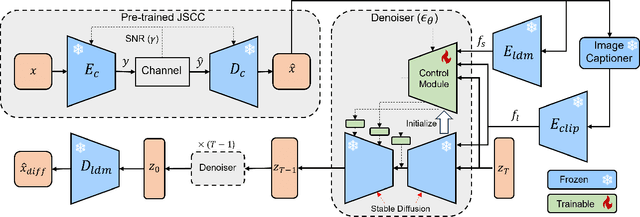
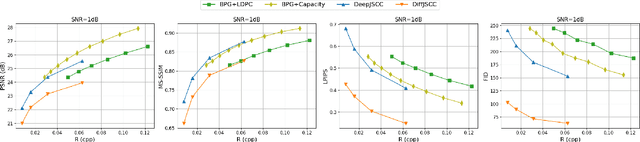
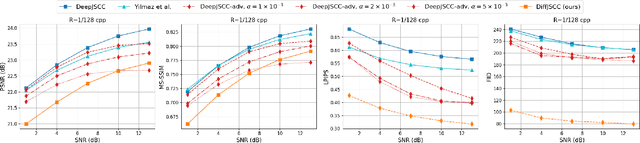
Deep learning-based joint source-channel coding (deep JSCC) has been demonstrated as an effective approach for wireless image transmission. Nevertheless, current research has concentrated on minimizing a standard distortion metric such as Mean Squared Error (MSE), which does not necessarily improve the perceptual quality. To address this issue, we propose DiffJSCC, a novel framework that leverages pre-trained text-to-image diffusion models to enhance the realism of images transmitted over the channel. The proposed DiffJSCC utilizes prior deep JSCC frameworks to deliver an initial reconstructed image at the receiver. Then, the spatial and textual features are extracted from the initial reconstruction, which, together with the channel state information (e.g., signal-to-noise ratio, SNR), are passed to a control module to fine-tune the pre-trained Stable Diffusion model. Extensive experiments on the Kodak dataset reveal that our method significantly surpasses both conventional methods and prior deep JSCC approaches on perceptual metrics such as LPIPS and FID scores, especially with poor channel conditions and limited bandwidth. Notably, DiffJSCC can achieve highly realistic reconstructions for 768x512 pixel Kodak images with only 3072 symbols (<0.008 symbols per pixel) under 1dB SNR. Our code will be released in https://github.com/mingyuyng/DiffJSCC.
Differentiable Learning of Generalized Structured Matrices for Efficient Deep Neural Networks
Oct 29, 2023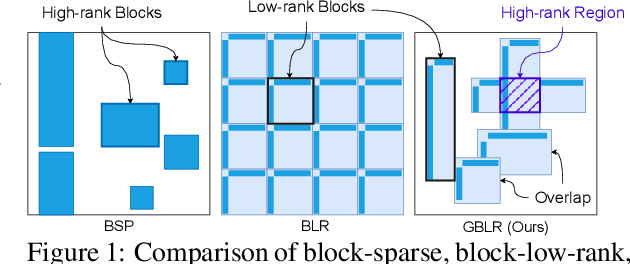
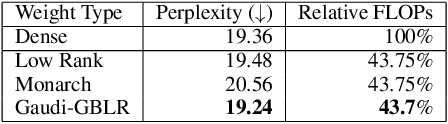
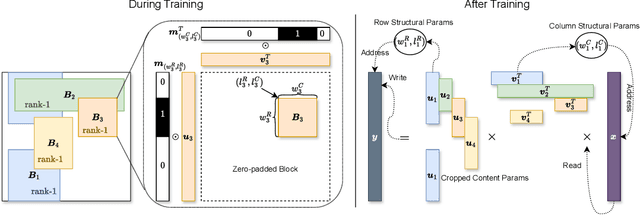
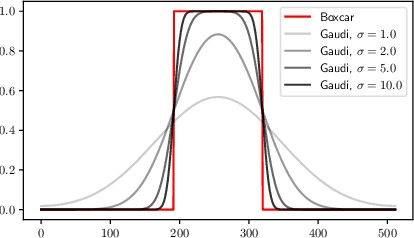
This paper investigates efficient deep neural networks (DNNs) to replace dense unstructured weight matrices with structured ones that possess desired properties. The challenge arises because the optimal weight matrix structure in popular neural network models is obscure in most cases and may vary from layer to layer even in the same network. Prior structured matrices proposed for efficient DNNs were mostly hand-crafted without a generalized framework to systematically learn them. To address this issue, we propose a generalized and differentiable framework to learn efficient structures of weight matrices by gradient descent. We first define a new class of structured matrices that covers a wide range of structured matrices in the literature by adjusting the structural parameters. Then, the frequency-domain differentiable parameterization scheme based on the Gaussian-Dirichlet kernel is adopted to learn the structural parameters by proximal gradient descent. Finally, we introduce an effective initialization method for the proposed scheme. Our method learns efficient DNNs with structured matrices, achieving lower complexity and/or higher performance than prior approaches that employ low-rank, block-sparse, or block-low-rank matrices.
Siamese Learning-based Monarch Butterfly Localization
Jul 04, 2023



A new GPS-less, daily localization method is proposed with deep learning sensor fusion that uses daylight intensity and temperature sensor data for Monarch butterfly tracking. Prior methods suffer from the location-independent day length during the equinox, resulting in high localization errors around that date. This work proposes a new Siamese learning-based localization model that improves the accuracy and reduces the bias of daily Monarch butterfly localization using light and temperature measurements. To train and test the proposed algorithm, we use $5658$ daily measurement records collected through a data measurement campaign involving 306 volunteers across the U.S., Canada, and Mexico from 2018 to 2020. This model achieves a mean absolute error of $1.416^\circ$ in latitude and $0.393^\circ$ in longitude coordinates outperforming the prior method.
MMVC: Learned Multi-Mode Video Compression with Block-based Prediction Mode Selection and Density-Adaptive Entropy Coding
Apr 05, 2023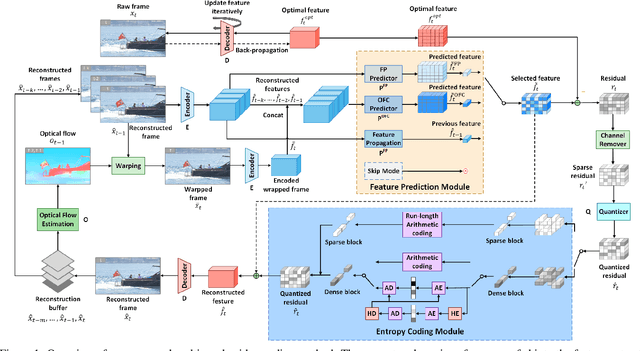


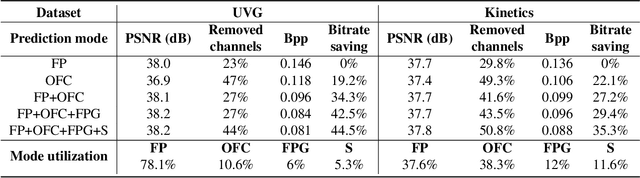
Learning-based video compression has been extensively studied over the past years, but it still has limitations in adapting to various motion patterns and entropy models. In this paper, we propose multi-mode video compression (MMVC), a block wise mode ensemble deep video compression framework that selects the optimal mode for feature domain prediction adapting to different motion patterns. Proposed multi-modes include ConvLSTM-based feature domain prediction, optical flow conditioned feature domain prediction, and feature propagation to address a wide range of cases from static scenes without apparent motions to dynamic scenes with a moving camera. We partition the feature space into blocks for temporal prediction in spatial block-based representations. For entropy coding, we consider both dense and sparse post-quantization residual blocks, and apply optional run-length coding to sparse residuals to improve the compression rate. In this sense, our method uses a dual-mode entropy coding scheme guided by a binary density map, which offers significant rate reduction surpassing the extra cost of transmitting the binary selection map. We validate our scheme with some of the most popular benchmarking datasets. Compared with state-of-the-art video compression schemes and standard codecs, our method yields better or competitive results measured with PSNR and MS-SSIM.
Efficient Computation Sharing for Multi-Task Visual Scene Understanding
Mar 16, 2023Solving multiple visual tasks using individual models can be resource-intensive, while multi-task learning can conserve resources by sharing knowledge across different tasks. Despite the benefits of multi-task learning, such techniques can struggle with balancing the loss for each task, leading to potential performance degradation. We present a novel computation- and parameter-sharing framework that balances efficiency and accuracy to perform multiple visual tasks utilizing individually-trained single-task transformers. Our method is motivated by transfer learning schemes to reduce computational and parameter storage costs while maintaining the desired performance. Our approach involves splitting the tasks into a base task and the other sub-tasks, and sharing a significant portion of activations and parameters/weights between the base and sub-tasks to decrease inter-task redundancies and enhance knowledge sharing. The evaluation conducted on NYUD-v2 and PASCAL-context datasets shows that our method is superior to the state-of-the-art transformer-based multi-task learning techniques with higher accuracy and reduced computational resources. Moreover, our method is extended to video stream inputs, further reducing computational costs by efficiently sharing information across the temporal domain as well as the task domain. Our codes and models will be publicly available.
Deep Joint Source-Channel Coding with Iterative Source Error Correction
Feb 17, 2023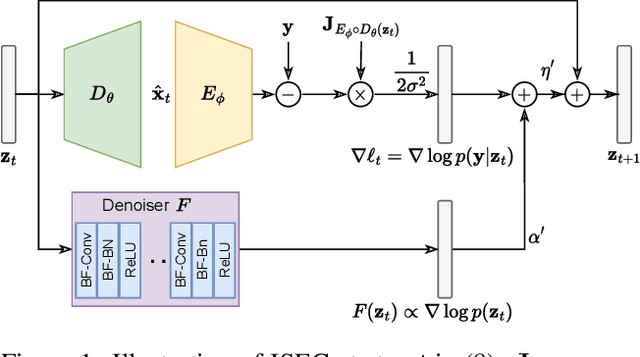
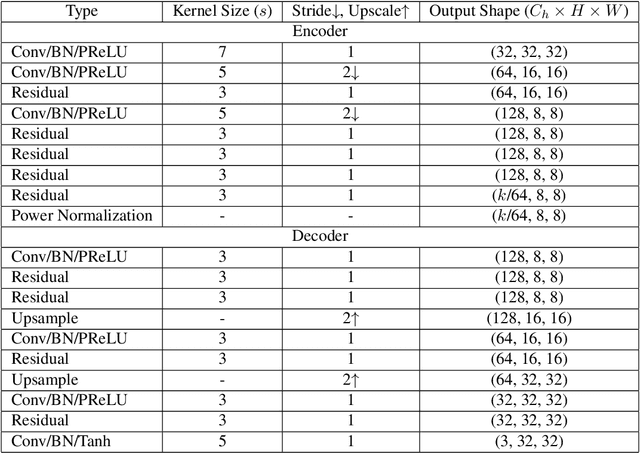

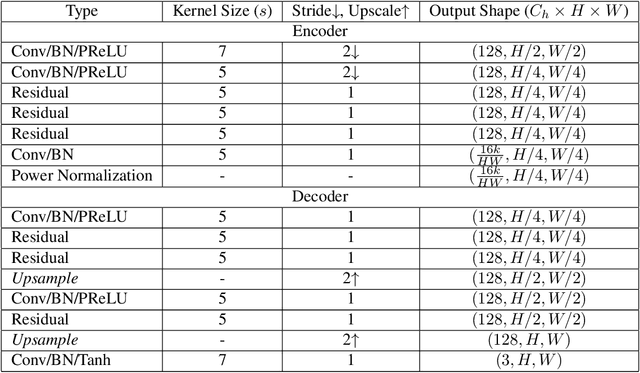
In this paper, we propose an iterative source error correction (ISEC) decoding scheme for deep-learning-based joint source-channel coding (Deep JSCC). Given a noisy codeword received through the channel, we use a Deep JSCC encoder and decoder pair to update the codeword iteratively to find a (modified) maximum a-posteriori (MAP) solution. For efficient MAP decoding, we utilize a neural network-based denoiser to approximate the gradient of the log-prior density of the codeword space. Albeit the non-convexity of the optimization problem, our proposed scheme improves various distortion and perceptual quality metrics from the conventional one-shot (non-iterative) Deep JSCC decoding baseline. Furthermore, the proposed scheme produces more reliable source reconstruction results compared to the baseline when the channel noise characteristics do not match the ones used during training.