 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMVC: Learned Multi-Mode Video Compression with Block-based Prediction Mode Selection and Density-Adaptive Entropy Coding
Apr 05, 2023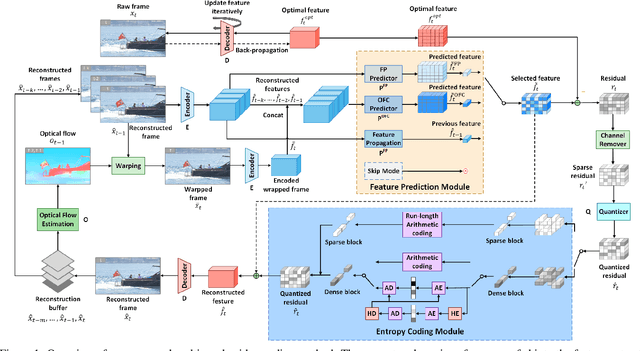


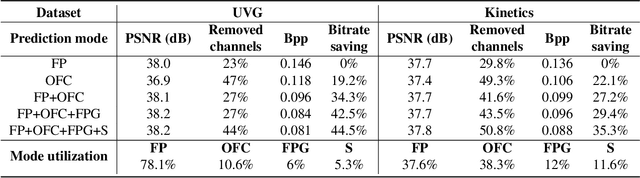
Learning-based video compression has been extensively studied over the past years, but it still has limitations in adapting to various motion patterns and entropy models. In this paper, we propose multi-mode video compression (MMVC), a block wise mode ensemble deep video compression framework that selects the optimal mode for feature domain prediction adapting to different motion patterns. Proposed multi-modes include ConvLSTM-based feature domain prediction, optical flow conditioned feature domain prediction, and feature propagation to address a wide range of cases from static scenes without apparent motions to dynamic scenes with a moving camera. We partition the feature space into blocks for temporal prediction in spatial block-based representations. For entropy coding, we consider both dense and sparse post-quantization residual blocks, and apply optional run-length coding to sparse residuals to improve the compression rate. In this sense, our method uses a dual-mode entropy coding scheme guided by a binary density map, which offers significant rate reduction surpassing the extra cost of transmitting the binary selection map. We validate our scheme with some of the most popular benchmarking datasets. Compared with state-of-the-art video compression schemes and standard codecs, our method yields better or competitive results measured with PSNR and MS-SSIM.