 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Aided Joint Source Channel Coding For High Realism Wireless Image Transmission
Paper and Code

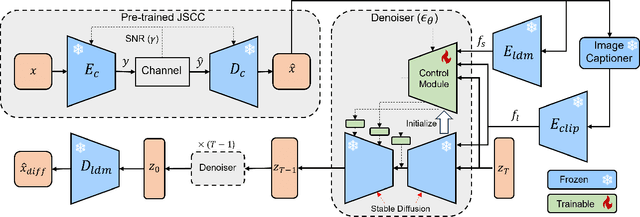
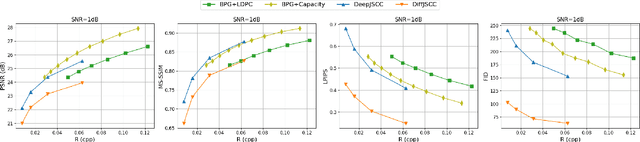
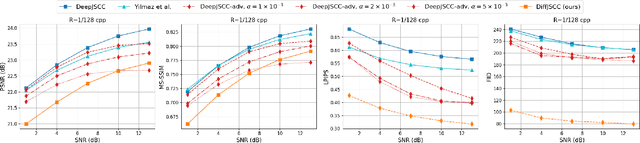
Deep learning-based joint source-channel coding (deep JSCC) has been demonstrated as an effective approach for wireless image transmission. Nevertheless, current research has concentrated on minimizing a standard distortion metric such as Mean Squared Error (MSE), which does not necessarily improve the perceptual quality. To address this issue, we propose DiffJSCC, a novel framework that leverages pre-trained text-to-image diffusion models to enhance the realism of images transmitted over the channel. The proposed DiffJSCC utilizes prior deep JSCC frameworks to deliver an initial reconstructed image at the receiver. Then, the spatial and textual features are extracted from the initial reconstruction, which, together with the channel state information (e.g., signal-to-noise ratio, SNR), are passed to a control module to fine-tune the pre-trained Stable Diffusion model. Extensive experiments on the Kodak dataset reveal that our method significantly surpasses both conventional methods and prior deep JSCC approaches on perceptual metrics such as LPIPS and FID scores, especially with poor channel conditions and limited bandwidth. Notably, DiffJSCC can achieve highly realistic reconstructions for 768x512 pixel Kodak images with only 3072 symbols (<0.008 symbols per pixel) under 1dB SNR. Our code will be released in https://github.com/mingyuyng/DiffJSCC.