 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Framework for Bearing Fault Diagnosis
Paper and Code
Nov 05, 2024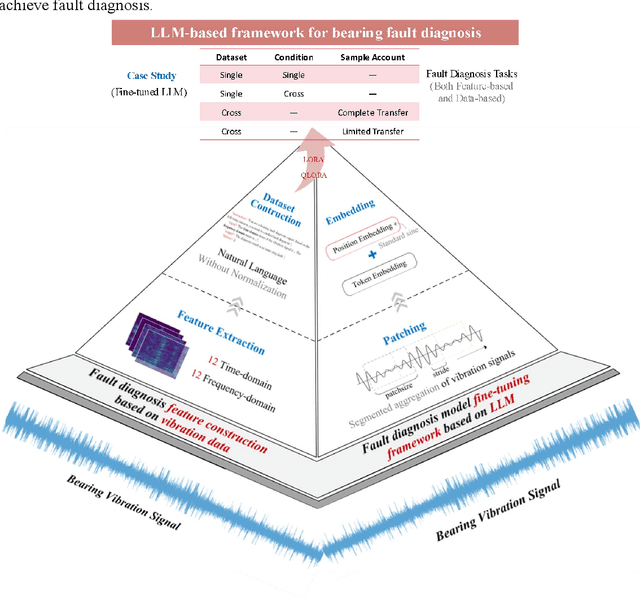



Accurately diagnosing bearing faults is crucial for maintaining the efficient operation of rotating machinery. However, traditional diagnosis methods face challenges due to the diversification of application environments, including cross-condition adaptability, small-sample learning difficulties, and cross-dataset generalization. These challenges have hindered the effectiveness and limited the application of existing approaches. Large language models (LLMs) offer new possibilities for improving the generalization of diagnosis models. However, the integration of LLMs with traditional diagnosis techniques for optimal generalization remains underexplored. This paper proposed an LLM-based bearing fault diagnosis framework to tackle these challenges. First, a signal feature quantification method was put forward to address the issue of extracting semantic information from vibration data, which integrated time and frequency domain feature extraction based on a statistical analysis framework. This method textualized time-series data, aiming to efficiently learn cross-condition and small-sample common features through concise feature selection. Fine-tuning methods based on LoRA and QLoRA were employed to enhance the generalization capability of LLMs in analyzing vibration data features. In addition, the two innovations (textualizing vibration features and fine-tuning pre-trained models) were validated by single-dataset cross-condition and cross-dataset transfer experiment with complete and limited data. The results demonstrated the ability of the proposed framework to perform three types of generalization tasks simultaneously. Trained cross-dataset models got approximately a 10% improvement in accuracy, proving the adaptability of LLMs to input patterns. Ultimately, the results effectively enhance the generalization capability and fill the research gap in using LLMs for bearing fault diagnosis.