 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Agent: Explicit Reasoning Agent for Graphs
Oct 25, 2023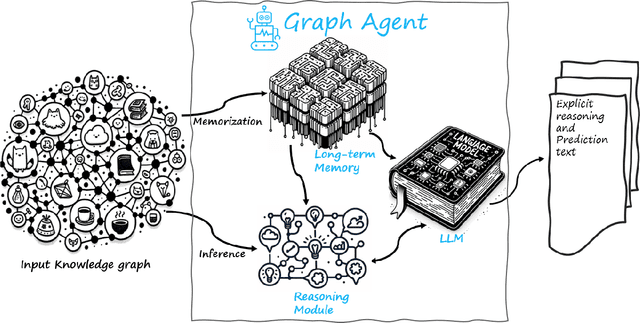
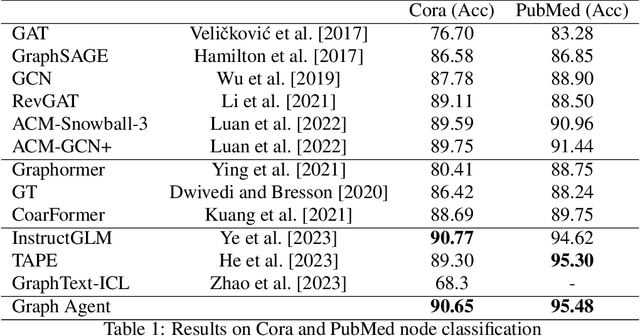
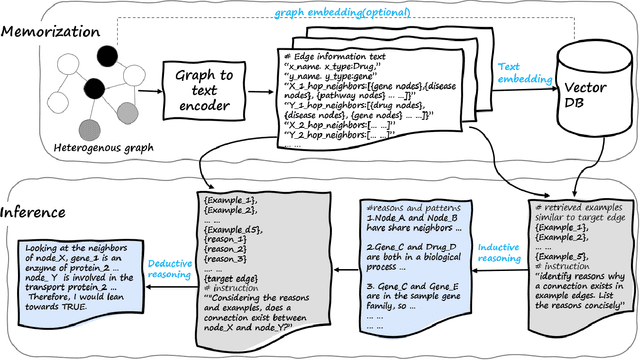
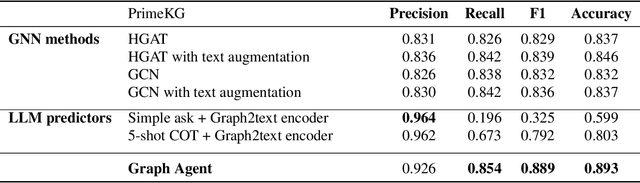
Graph embedding methods such as Graph Neural Networks (GNNs) and Graph Transformers have contributed to the development of graph reasoning algorithms for various tasks on knowledge graphs. However, the lack of interpretability and explainability of graph embedding methods has limited their applicability in scenarios requiring explicit reasoning. In this paper, we introduce the Graph Agent (GA), an intelligent agent methodology of leveraging large language models (LLMs), inductive-deductive reasoning modules, and long-term memory for knowledge graph reasoning tasks. GA integrates aspects of symbolic reasoning and existing graph embedding methods to provide an innovative approach for complex graph reasoning tasks. By converting graph structures into textual data, GA enables LLMs to process, reason, and provide predictions alongside human-interpretable explanations. The effectiveness of the GA was evaluated on node classification and link prediction tasks. Results showed that GA reached state-of-the-art performance, demonstrating accuracy of 90.65%, 95.48%, and 89.32% on Cora, PubMed, and PrimeKG datasets, respectively. Compared to existing GNN and transformer models, GA offered advantages of explicit reasoning ability, free-of-training, easy adaption to various graph reasoning tasks
Exploring the In-context Learning Ability of Large Language Model for Biomedical Concept Linking
Jul 03, 2023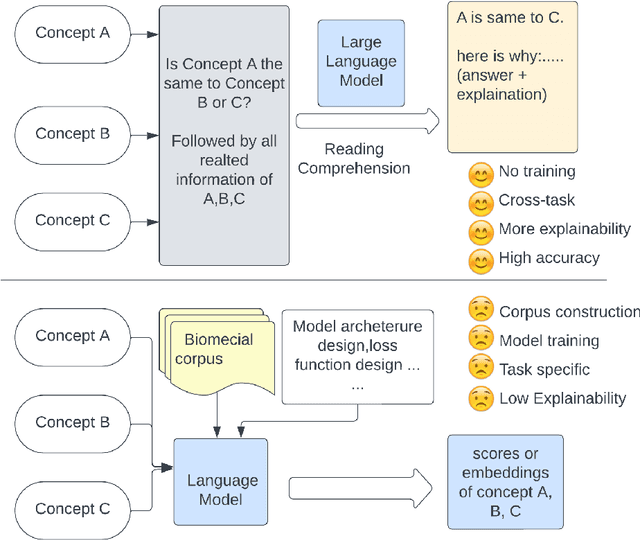
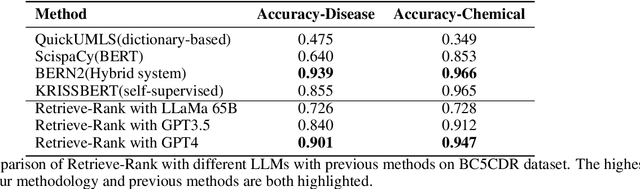

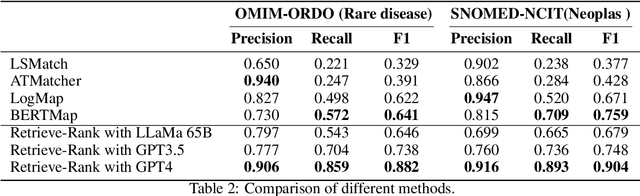
The biomedical field relies heavily on concept linking in various areas such as literature mining, graph alignment, information retrieval, question-answering, data, and knowledge integration. Although large language models (LLMs) have made significant strides in many natural language processing tasks, their effectiveness in biomedical concept mapping is yet to be fully explored. This research investigates a method that exploits the in-context learning (ICL) capabilities of large models for biomedical concept linking. The proposed approach adopts a two-stage retrieve-and-rank framework. Initially, biomedical concepts are embedded using language models, and then embedding similarity is utilized to retrieve the top candidates. These candidates' contextual information is subsequently incorporated into the prompt and processed by a large language model to re-rank the concepts. This approach achieved an accuracy of 90.% in BC5CDR disease entity normalization and 94.7% in chemical entity normalization, exhibiting a competitive performance relative to supervised learning methods. Further, it showed a significant improvement, with an over 20-point absolute increase in F1 score on an oncology matching dataset. Extensive qualitative assessments were conducted, and the benefits and potential shortcomings of using large language models within the biomedical domain were discussed. were discussed.
Physics-enhanced machine learning for virtual fluorescence microscopy
Apr 21, 2020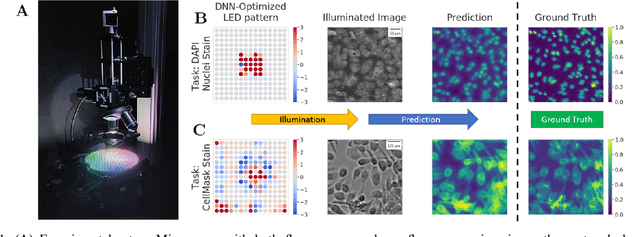
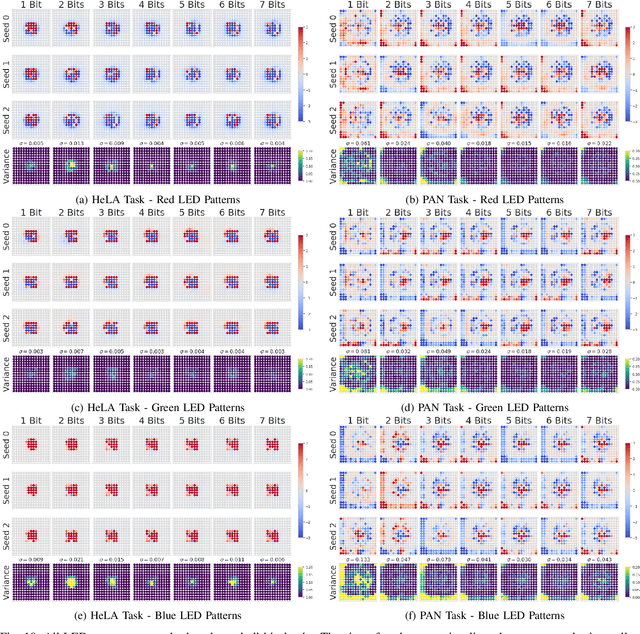
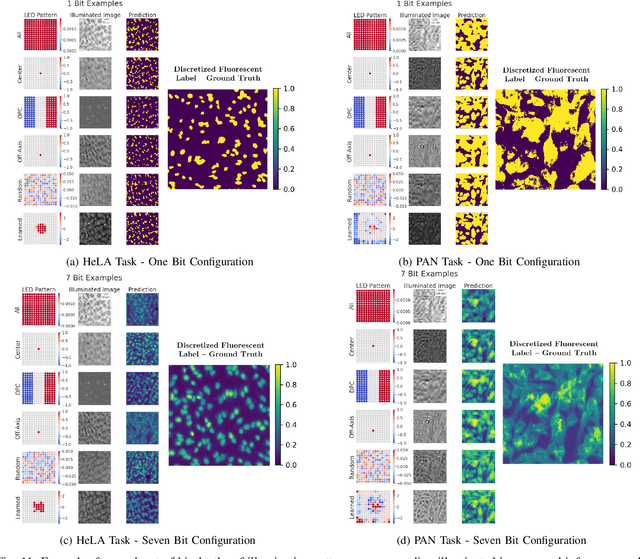

This paper introduces a new method of data-driven microscope design for virtual fluorescence microscopy. Our results show that by including a model of illumination within the first layers of a deep convolutional neural network, it is possible to learn task-specific LED patterns that substantially improve the ability to infer fluorescence image information from unstained transmission microscopy images. We validated our method on two different experimental setups, with different magnifications and different sample types, to show a consistent improvement in performance as compared to conventional illumination methods. Additionally, to understand the importance of learned illumination on inference task, we varied the dynamic range of the fluorescent image targets (from one to seven bits), and showed that the margin of improvement for learned patterns increased with the information content of the target. This work demonstrates the power of programmable optical elements at enabling better machine learning algorithm performance and at providing physical insight into next generation of machine-controlled imaging systems.
PS-RCNN: Detecting Secondary Human Instances in a Crowd via Primary Object Suppression
Mar 16, 2020


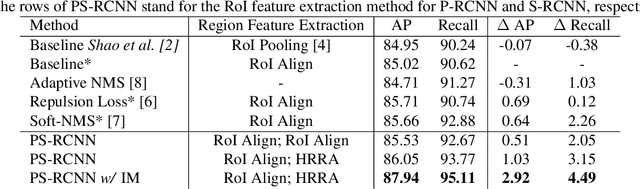
Detecting human bodies in highly crowded scenes is a challenging problem. Two main reasons result in such a problem: 1). weak visual cues of heavily occluded instances can hardly provide sufficient information for accurate detection; 2). heavily occluded instances are easier to be suppressed by Non-Maximum-Suppression (NMS). To address these two issues, we introduce a variant of two-stage detectors called PS-RCNN. PS-RCNN first detects slightly/none occluded objects by an R-CNN module (referred as P-RCNN), and then suppress the detected instances by human-shaped masks so that the features of heavily occluded instances can stand out. After that, PS-RCNN utilizes another R-CNN module specialized in heavily occluded human detection (referred as S-RCNN) to detect the rest missed objects by P-RCNN. Final results are the ensemble of the outputs from these two R-CNNs. Moreover, we introduce a High Resolution RoI Align (HRRA) module to retain as much of fine-grained features of visible parts of the heavily occluded humans as possible. Our PS-RCNN significantly improves recall and AP by 4.49% and 2.92% respectively on CrowdHuman, compared to the baseline. Similar improvements on Widerperson are also achieved by the PS-RCNN.