 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMRec: Large Language Models with Graph Augmentation for Recommendation
Nov 17, 2023The problem of data sparsity has long been a challenge in recommendation systems, and previous studies have attempted to address this issue by incorporating side information. However, this approach often introduces side effects such as noise, availability issues, and low data quality, which in turn hinder the accurate modeling of user preferences and adversely impact recommendation performance. In light of the recent advancements in large language models (LLMs), which possess extensive knowledge bases and strong reasoning capabilities, we propose a novel framework called LLMRec that enhances recommender systems by employing three simple yet effective LLM-based graph augmentation strategies. Our approach leverages the rich content available within online platforms (e.g., Netflix, MovieLens) to augment the interaction graph in three ways: (i) reinforcing user-item interaction egde, (ii) enhancing the understanding of item node attributes, and (iii) conducting user node profiling, intuitively from the natural language perspective. By employing these strategies, we address the challenges posed by sparse implicit feedback and low-quality side information in recommenders. Besides, to ensure the quality of the augmentation, we develop a denoised data robustification mechanism that includes techniques of noisy implicit feedback pruning and MAE-based feature enhancement that help refine the augmented data and improve its reliability. Furthermore, we provide theoretical analysis to support the effectiveness of LLMRec and clarify the benefits of our method in facilitating model optimization. Experimental results on benchmark datasets demonstrate the superiority of our LLM-based augmentation approach over state-of-the-art techniques. To ensure reproducibility, we have made our code and augmented data publicly available at: https://github.com/HKUDS/LLMRec.git
Graph Agent: Explicit Reasoning Agent for Graphs
Oct 25, 2023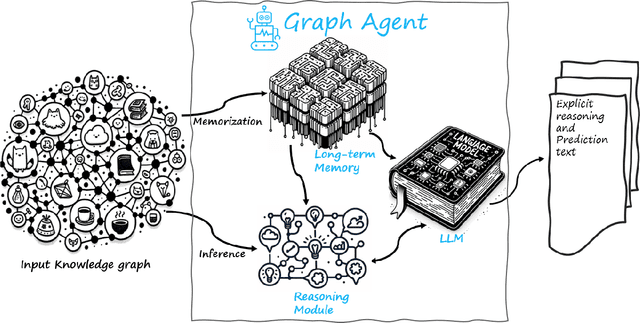
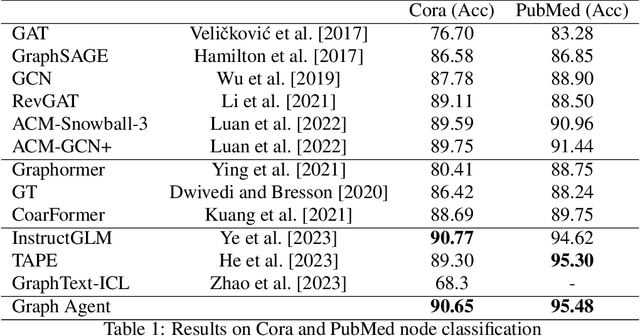
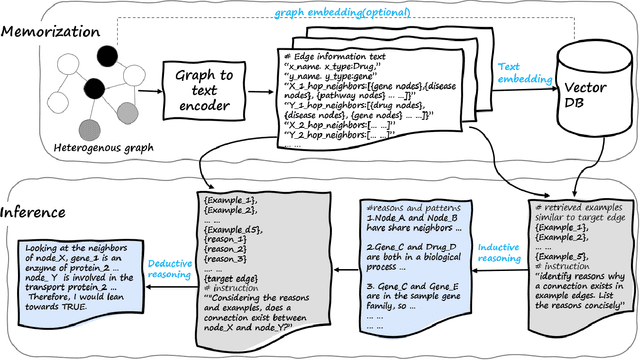
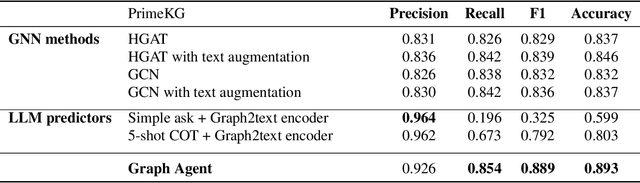
Graph embedding methods such as Graph Neural Networks (GNNs) and Graph Transformers have contributed to the development of graph reasoning algorithms for various tasks on knowledge graphs. However, the lack of interpretability and explainability of graph embedding methods has limited their applicability in scenarios requiring explicit reasoning. In this paper, we introduce the Graph Agent (GA), an intelligent agent methodology of leveraging large language models (LLMs), inductive-deductive reasoning modules, and long-term memory for knowledge graph reasoning tasks. GA integrates aspects of symbolic reasoning and existing graph embedding methods to provide an innovative approach for complex graph reasoning tasks. By converting graph structures into textual data, GA enables LLMs to process, reason, and provide predictions alongside human-interpretable explanations. The effectiveness of the GA was evaluated on node classification and link prediction tasks. Results showed that GA reached state-of-the-art performance, demonstrating accuracy of 90.65%, 95.48%, and 89.32% on Cora, PubMed, and PrimeKG datasets, respectively. Compared to existing GNN and transformer models, GA offered advantages of explicit reasoning ability, free-of-training, easy adaption to various graph reasoning tasks
Exploring the In-context Learning Ability of Large Language Model for Biomedical Concept Linking
Jul 03, 2023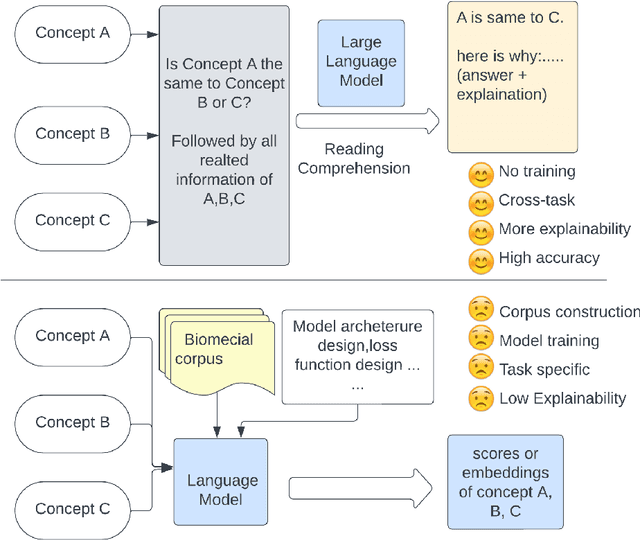
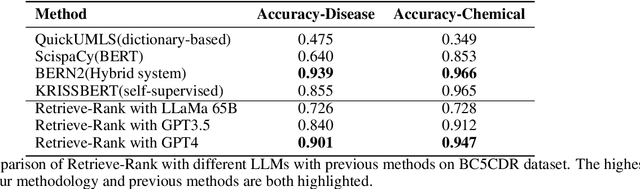

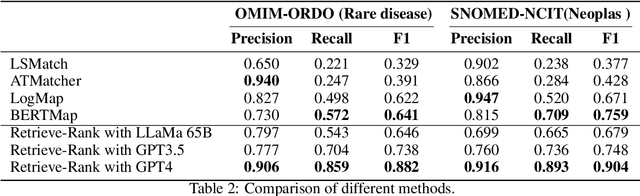
The biomedical field relies heavily on concept linking in various areas such as literature mining, graph alignment, information retrieval, question-answering, data, and knowledge integration. Although large language models (LLMs) have made significant strides in many natural language processing tasks, their effectiveness in biomedical concept mapping is yet to be fully explored. This research investigates a method that exploits the in-context learning (ICL) capabilities of large models for biomedical concept linking. The proposed approach adopts a two-stage retrieve-and-rank framework. Initially, biomedical concepts are embedded using language models, and then embedding similarity is utilized to retrieve the top candidates. These candidates' contextual information is subsequently incorporated into the prompt and processed by a large language model to re-rank the concepts. This approach achieved an accuracy of 90.% in BC5CDR disease entity normalization and 94.7% in chemical entity normalization, exhibiting a competitive performance relative to supervised learning methods. Further, it showed a significant improvement, with an over 20-point absolute increase in F1 score on an oncology matching dataset. Extensive qualitative assessments were conducted, and the benefits and potential shortcomings of using large language models within the biomedical domain were discussed. were discussed.
Efficient On-Device Session-Based Recommendation
Sep 28, 2022

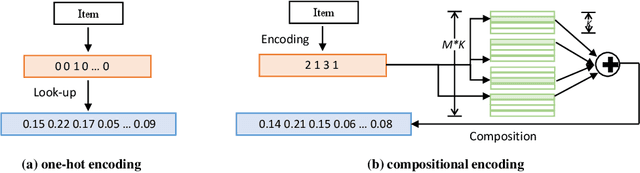

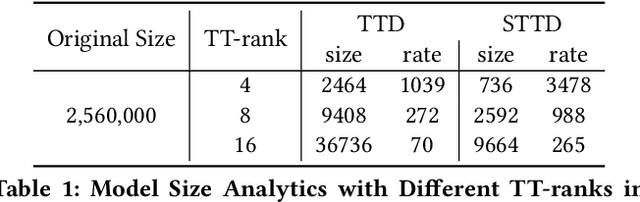
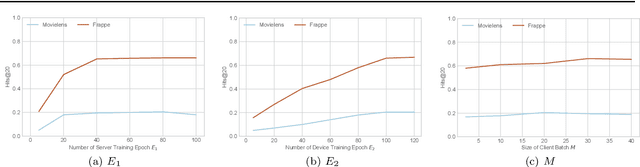
On-device session-based recommendation systems have been achieving increasing attention on account of the low energy/resource consumption and privacy protection while providing promising recommendation performance. To fit the powerful neural session-based recommendation models in resource-constrained mobile devices, tensor-train decomposition and its variants have been widely applied to reduce memory footprint by decomposing the embedding table into smaller tensors, showing great potential in compressing recommendation models. However, these model compression techniques significantly increase the local inference time due to the complex process of generating index lists and a series of tensor multiplications to form item embeddings, and the resultant on-device recommender fails to provide real-time response and recommendation. To improve the online recommendation efficiency, we propose to learn compositional encoding-based compact item representations. Specifically, each item is represented by a compositional code that consists of several codewords, and we learn embedding vectors to represent each codeword instead of each item. Then the composition of the codeword embedding vectors from different embedding matrices (i.e., codebooks) forms the item embedding. Since the size of codebooks can be extremely small, the recommender model is thus able to fit in resource-constrained devices and meanwhile can save the codebooks for fast local inference.Besides, to prevent the loss of model capacity caused by compression, we propose a bidirectional self-supervised knowledge distillation framework. Extensive experimental results on two benchmark datasets demonstrate that compared with existing methods, the proposed on-device recommender not only achieves an 8x inference speedup with a large compression ratio but also shows superior recommendation performance.
On-Device Next-Item Recommendation with Self-Supervised Knowledge Distillation
Apr 23, 2022


Modern recommender systems operate in a fully server-based fashion. To cater to millions of users, the frequent model maintaining and the high-speed processing for concurrent user requests are required, which comes at the cost of a huge carbon footprint. Meanwhile, users need to upload their behavior data even including the immediate environmental context to the server, raising the public concern about privacy. On-device recommender systems circumvent these two issues with cost-conscious settings and local inference. However, due to the limited memory and computing resources, on-device recommender systems are confronted with two fundamental challenges: (1) how to reduce the size of regular models to fit edge devices? (2) how to retain the original capacity? Previous research mostly adopts tensor decomposition techniques to compress the regular recommendation model with limited compression ratio so as to avoid drastic performance degradation. In this paper, we explore ultra-compact models for next-item recommendation, by loosing the constraint of dimensionality consistency in tensor decomposition. Meanwhile, to compensate for the capacity loss caused by compression, we develop a self-supervised knowledge distillation framework which enables the compressed model (student) to distill the essential information lying in the raw data, and improves the long-tail item recommendation through an embedding-recombination strategy with the original model (teacher). The extensive experiments on two benchmarks demonstrate that, with 30x model size reduction, the compressed model almost comes with no accuracy loss, and even outperforms its uncompressed counterpart in most cases.
Fast-adapting and Privacy-preserving Federated Recommender System
Apr 09, 2021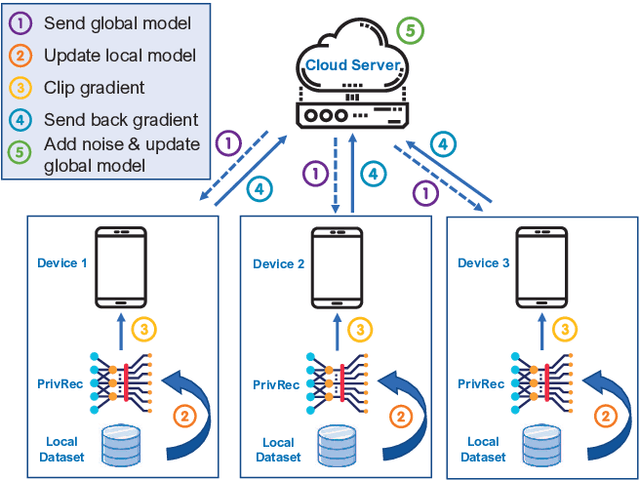
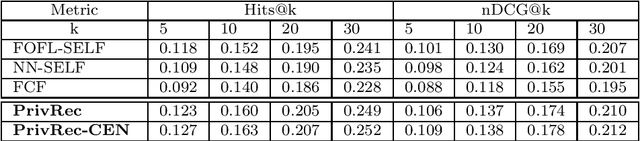
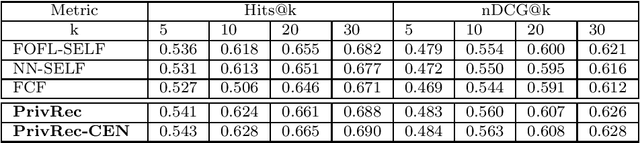
In the mobile Internet era, recommender systems have become an irreplaceable tool to help users discover useful items, thus alleviating the information overload problem. Recent research on deep neural network (DNN)-based recommender systems have made significant progress in improving prediction accuracy, largely attributed to the widely accessible large-scale user data. Such data is commonly collected from users' personal devices, and then centrally stored in the cloud server to facilitate model training. However, with the rising public concerns on user privacy leakage in online platforms, online users are becoming increasingly anxious over abuses of user privacy. Therefore, it is urgent and beneficial to develop a recommender system that can achieve both high prediction accuracy and strong privacy protection. To this end, we propose a DNN-based recommendation model called PrivRec running on the decentralized federated learning (FL) environment, which ensures that a user's data is fully retained on her/his personal device while contributing to training an accurate model. On the other hand, to better embrace the data heterogeneity (e.g., users' data vary in scale and quality significantly) in FL, we innovatively introduce a first-order meta-learning method that enables fast on-device personalization with only a few data points. Furthermore, to defend against potential malicious participants that pose serious security threat to other users, we further develop a user-level differentially private model, namely DP-PrivRec, so attackers are unable to identify any arbitrary user from the trained model. Finally, we conduct extensive experiments on two large-scale datasets in a simulated FL environment, and the results validate the superiority of both PrivRec and DP-PrivRec.
Self-Supervised Multi-Channel Hypergraph Convolutional Network for Social Recommendation
Jan 21, 2021



Social relations are often used to improve recommendation quality when user-item interaction data is sparse in recommender systems. Most existing social recommendation models exploit pairwise relations to mine potential user preferences. However, real-life interactions among users are very complicated and user relations can be high-order. Hypergraph provides a natural way to model complex high-order relations, while its potentials for improving social recommendation are under-explored. In this paper, we fill this gap and propose a multi-channel hypergraph convolutional network to enhance social recommendation by leveraging high-order user relations. Technically, each channel in the network encodes a hypergraph that depicts a common high-order user relation pattern via hypergraph convolution. By aggregating the embeddings learned through multiple channels, we obtain comprehensive user representations to generate recommendation results. However, the aggregation operation might also obscure the inherent characteristics of different types of high-order connectivity information. To compensate for the aggregating loss, we innovatively integrate self-supervised learning into the training of the hypergraph convolutional network to regain the connectivity information with hierarchical mutual information maximization. The experimental results on multiple real-world datasets show that the proposed model outperforms the SOTA methods, and the ablation study verifies the effectiveness of the multi-channel setting and the self-supervised task. The implementation of our model is available via https://github.com/Coder-Yu/RecQ.
Overcoming Data Sparsity in Group Recommendation
Oct 02, 2020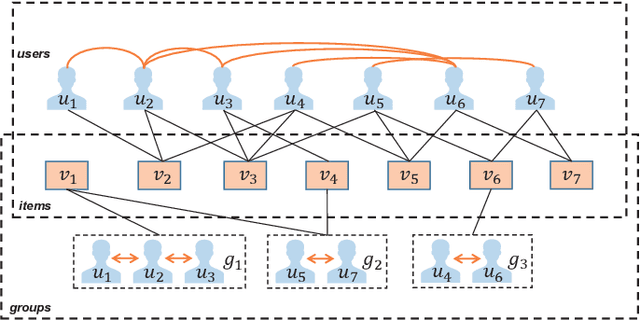
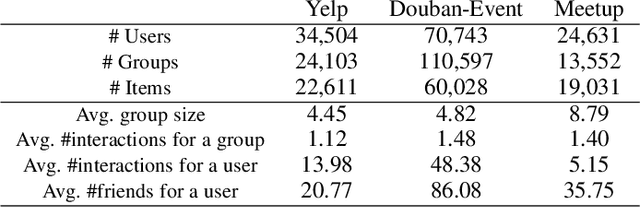
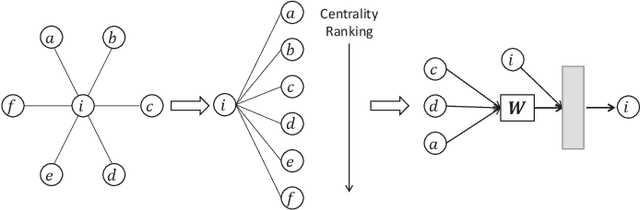
It has been an important task for recommender systems to suggest satisfying activities to a group of users in people's daily social life. The major challenge in this task is how to aggregate personal preferences of group members to infer the decision of a group. Conventional group recommendation methods applied a predefined strategy for preference aggregation. However, these static strategies are too simple to model the real and complex process of group decision-making, especially for occasional groups which are formed ad-hoc. Moreover, group members should have non-uniform influences or weights in a group, and the weight of a user can be varied in different groups. Therefore, an ideal group recommender system should be able to accurately learn not only users' personal preferences but also the preference aggregation strategy from data. In this paper, we propose a novel end-to-end group recommender system named CAGR (short for Centrality Aware Group Recommender"), which takes Bipartite Graph Embedding Model (BGEM), the self-attention mechanism and Graph Convolutional Networks (GCNs) as basic building blocks to learn group and user representations in a unified way. Specifically, we first extend BGEM to model group-item interactions, and then in order to overcome the limitation and sparsity of the interaction data generated by occasional groups, we propose a self-attentive mechanism to represent groups based on the group members. In addition, to overcome the sparsity issue of user-item interaction data, we leverage the user social networks to enhance user representation learning, obtaining centrality-aware user representations. We create three large-scale benchmark datasets and conduct extensive experiments on them. The experimental results show the superiority of our proposed CAGR by comparing it with state-of-the-art group recommender models.