 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-MIG: Multi-view Information Gain-based Retrieval-Augmented Generation for Clinical Diagnosis Reasoning
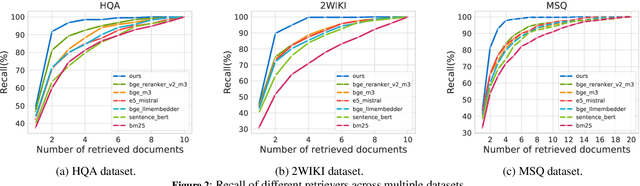
May 27, 2026Retrieval-augmented generation combined with reinforcement learning has shown promise for grounding large language models in trustworthy medical evidence. However, existing methods rely on exact-match binary rewards, which in clinical diagnosis cause two issues: (i) semantically relevant but non-verbatim steps receive zero signal, discarding valuable learning signals; and (ii) uni-dimensional rewards cannot effectively supervise heterogeneous reasoning capabilities. To address these issues, we propose C-MIG, a Multi-view Information Gain-based retrieval-augmented generation framework for Clinical diagnosis. C-MIG estimates information gain under a frozen reference model from two complementary views, retrieved-document and document-refinement, to jointly guide what to retrieve and how to refine, alleviating the issues of valuable reward signal loss and credit assignment. We further design a multi-subquery retrieval augmentation strategy that improves knowledge recall coverage in clinical diagnostic scenarios. Comprehensive experiments on four medical benchmarks demonstrate that C-MIG achieves the best performance among all RAG-RL methods on both in-domain and out-of-domain sets, and outperforms state-of-the-art general-purpose LLMs for clinical diagnosis.
EAPO: Entropy-Driven Adaptive Positive-Negative Sample Weighting for Policy Optimization in Open-Ended QA
May 27, 2026Large Reasoning Models are typically trained via reinforcement learning from verifiable rewards (RLVR). However, existing approaches adopt fixed weights for positive and negative samples, and the conclusions hardly generalize to open-ended question answering (QA). In this paper, we systematically investigate the roles of positive and negative samples in reinforcement learning for open-ended QA. We propose a reward-mean-based strategy for distinguishing positive from negative samples, and observe that negative samples predominantly govern response diversity and the performance upper bound, whereas positive samples primarily determine response quality and convergence stability. Building on these observations, we propose EAPO, an Entropy-driven Adaptive Policy Optimization method that adaptively computes the weighting coefficients of positive samples based on the ratio of the current policy entropy to the initial entropy. During the entropy-decreasing phase, the weight assigned to positive samples is reduced to preserve exploration, whereas during the entropy-increasing phase it is amplified to reinforce stability, thereby mitigating entropy collapse. Experiments on two publicly available open-ended medical QA datasets demonstrate that EAPO consistently and substantially outperforms fixed-weight baselines in both response diversity and stability.
Dr. Assistant: Enhancing Clinical Diagnostic Inquiry via Structured Diagnostic Reasoning Data and Reinforcement Learning
Jan 20, 2026Clinical Decision Support Systems (CDSSs) provide reasoning and inquiry guidance for physicians, yet they face notable challenges, including high maintenance costs and low generalization capability. Recently, Large Language Models (LLMs) have been widely adopted in healthcare due to their extensive knowledge reserves, retrieval, and communication capabilities. While LLMs show promise and excel at medical benchmarks, their diagnostic reasoning and inquiry skills are constrained. To mitigate this issue, we propose (1) Clinical Diagnostic Reasoning Data (CDRD) structure to capture abstract clinical reasoning logic, and a pipeline for its construction, and (2) the Dr. Assistant, a clinical diagnostic model equipped with clinical reasoning and inquiry skills. Its training involves a two-stage process: SFT, followed by RL with a tailored reward function. We also introduce a benchmark to evaluate both diagnostic reasoning and inquiry. Our experiments demonstrate that the Dr. Assistant outperforms open-source models and achieves competitive performance to closed-source models, providing an effective solution for clinical diagnostic inquiry guidance.
Proactive Guidance of Multi-Turn Conversation in Industrial Search
May 30, 2025



The evolution of Large Language Models (LLMs) has significantly advanced multi-turn conversation systems, emphasizing the need for proactive guidance to enhance users' interactions. However, these systems face challenges in dynamically adapting to shifts in users' goals and maintaining low latency for real-time interactions. In the Baidu Search AI assistant, an industrial-scale multi-turn search system, we propose a novel two-phase framework to provide proactive guidance. The first phase, Goal-adaptive Supervised Fine-Tuning (G-SFT), employs a goal adaptation agent that dynamically adapts to user goal shifts and provides goal-relevant contextual information. G-SFT also incorporates scalable knowledge transfer to distill insights from LLMs into a lightweight model for real-time interaction. The second phase, Click-oriented Reinforcement Learning (C-RL), adopts a generate-rank paradigm, systematically constructs preference pairs from user click signals, and proactively improves click-through rates through more engaging guidance. This dual-phase architecture achieves complementary objectives: G-SFT ensures accurate goal tracking, while C-RL optimizes interaction quality through click signal-driven reinforcement learning. Extensive experiments demonstrate that our framework achieves 86.10% accuracy in offline evaluation (+23.95% over baseline) and 25.28% CTR in online deployment (149.06% relative improvement), while reducing inference latency by 69.55% through scalable knowledge distillation.
An Extended Symbolic-Arithmetic Model for Teaching Double-Black Removal with Rotation in Red-Black Trees
Apr 04, 2025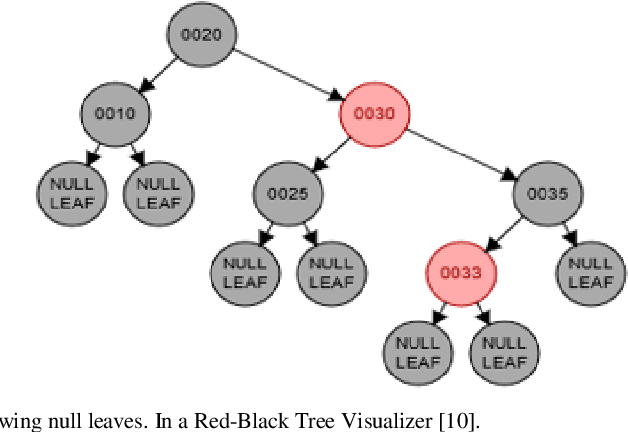

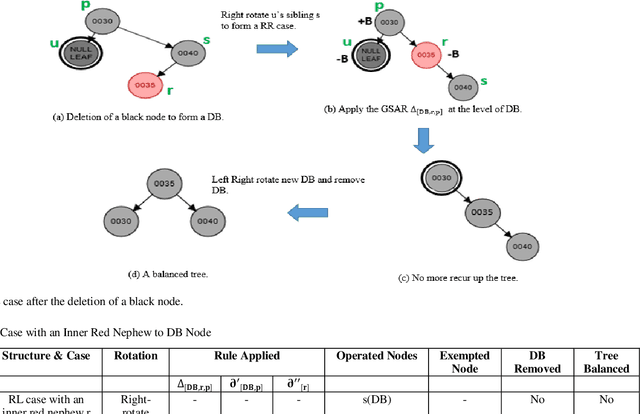
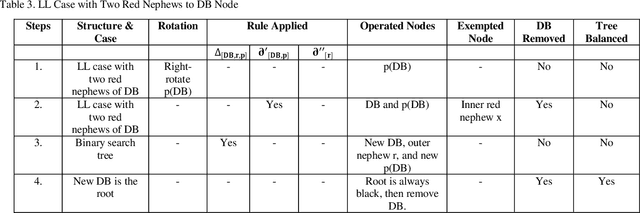
Double-black (DB) nodes have no place in red-black (RB) trees. So when DB nodes are formed, they are immediately removed. The removal of DB nodes that cause rotation and recoloring of other connected nodes poses greater challenges in the teaching and learning of RB trees. To ease this difficulty, this paper extends our previous work on the symbolic arithmetic algebraic (SA) method for removing DB nodes. The SA operations that are given as, Red + Black = Black; Black - Black = Red; Black + Black = DB; and DB - Black = Black removes DB nodes and rebalances black heights in RB trees. By extension, this paper projects three SA mathematical equations, namely, general symbolic arithmetic rule; partial symbolic arithmetic rule1; and partial symbolic arithmetic rule2. The removal of a DB node ultimately affects black heights in RB trees. To balance black heights using the SA equations, all the RB tree cases, namely, LR, RL, LL, and RR, were considered in this work; and the position of the nodes connected directly or indirectly to the DB node was also tested. In this study, to balance a RB tree, the issues considered w.r.t. the different cases of the RB tree were i) whether a DB node has an inner, outer, or both inner and outer black nephews; or ii) whether a DB node has an inner, outer or both inner and outer red nephews. The nephews r and x in this work are the children of the sibling s to a DB, and further up the tree, the parent p of a DB is their grandparent g. Thus, r and x have indirect relationships to a DB at the point of formation of the DB node. The novelty of the SA equations is in their effectiveness in the removal of DB that involves rotation of nodes as well as the recoloring of nodes along any simple path so as to balance black heights in a tree.
FltLM: An Intergrated Long-Context Large Language Model for Effective Context Filtering and Understanding
Oct 09, 2024
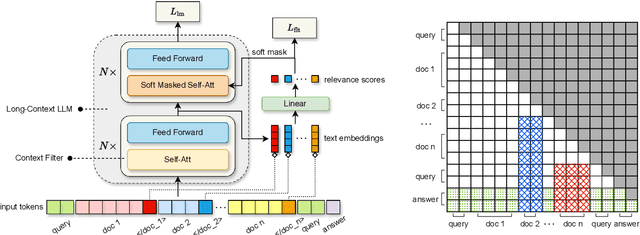

The development of Long-Context Large Language Models (LLMs) has markedly advanced natural language processing by facilitating the process of textual data across long documents and multiple corpora. However, Long-Context LLMs still face two critical challenges: The lost in the middle phenomenon, where crucial middle-context information is likely to be missed, and the distraction issue that the models lose focus due to overly extended contexts. To address these challenges, we propose the Context Filtering Language Model (FltLM), a novel integrated Long-Context LLM which enhances the ability of the model on multi-document question-answering (QA) tasks. Specifically, FltLM innovatively incorporates a context filter with a soft mask mechanism, identifying and dynamically excluding irrelevant content to concentrate on pertinent information for better comprehension and reasoning. Our approach not only mitigates these two challenges, but also enables the model to operate conveniently in a single forward pass. Experimental results demonstrate that FltLM significantly outperforms supervised fine-tuning and retrieval-based methods in complex QA scenarios, suggesting a promising solution for more accurate and reliable long-context natural language understanding applications.
DaRec: A Disentangled Alignment Framework for Large Language Model and Recommender System
Aug 15, 2024Benefiting from the strong reasoning capabilities, Large language models (LLMs) have demonstrated remarkable performance in recommender systems. Various efforts have been made to distill knowledge from LLMs to enhance collaborative models, employing techniques like contrastive learning for representation alignment. In this work, we prove that directly aligning the representations of LLMs and collaborative models is sub-optimal for enhancing downstream recommendation tasks performance, based on the information theorem. Consequently, the challenge of effectively aligning semantic representations between collaborative models and LLMs remains unresolved. Inspired by this viewpoint, we propose a novel plug-and-play alignment framework for LLMs and collaborative models. Specifically, we first disentangle the latent representations of both LLMs and collaborative models into specific and shared components via projection layers and representation regularization. Subsequently, we perform both global and local structure alignment on the shared representations to facilitate knowledge transfer. Additionally, we theoretically prove that the specific and shared representations contain more pertinent and less irrelevant information, which can enhance the effectiveness of downstream recommendation tasks. Extensive experimental results on benchmark datasets demonstrate that our method is superior to existing state-of-the-art algorithms.
GOVERN: Gradient Orientation Vote Ensemble for Multi-Teacher Reinforced Distillation
May 06, 2024Pre-trained language models have become an integral component of question-answering systems, achieving remarkable performance. For practical deployment, it is critical to carry out knowledge distillation to preserve high performance under computational constraints. In this paper, we address a key question: given the importance of unsupervised distillation for student performance, how does one effectively ensemble knowledge from multiple teachers at this stage without the guidance of ground-truth labels? We propose a novel algorithm, GOVERN, to tackle this issue. GOVERN has demonstrated significant improvements in both offline and online experiments. The proposed algorithm has been successfully deployed in a real-world commercial question-answering system.
VisLingInstruct: Elevating Zero-Shot Learning in Multi-Modal Language Models with Autonomous Instruction Optimization
Feb 12, 2024This paper presents VisLingInstruct, a novel approach to advancing Multi-Modal Language Models (MMLMs) in zero-shot learning. Current MMLMs show impressive zero-shot abilities in multi-modal tasks, but their performance depends heavily on the quality of instructions. VisLingInstruct tackles this by autonomously evaluating and optimizing instructional texts through In-Context Learning, improving the synergy between visual perception and linguistic expression in MMLMs. Alongside this instructional advancement, we have also optimized the visual feature extraction modules in MMLMs, further augmenting their responsiveness to textual cues. Our comprehensive experiments on MMLMs, based on FlanT5 and Vicuna, show that VisLingInstruct significantly improves zero-shot performance in visual multi-modal tasks. Notably, it achieves a 13.1% and 9% increase in accuracy over the prior state-of-the-art on the TextVQA and HatefulMemes datasets.
Text-Video Retrieval via Variational Multi-Modal Hypergraph Networks
Jan 06, 2024Text-video retrieval is a challenging task that aims to identify relevant videos given textual queries. Compared to conventional textual retrieval, the main obstacle for text-video retrieval is the semantic gap between the textual nature of queries and the visual richness of video content. Previous works primarily focus on aligning the query and the video by finely aggregating word-frame matching signals. Inspired by the human cognitive process of modularly judging the relevance between text and video, the judgment needs high-order matching signal due to the consecutive and complex nature of video contents. In this paper, we propose chunk-level text-video matching, where the query chunks are extracted to describe a specific retrieval unit, and the video chunks are segmented into distinct clips from videos. We formulate the chunk-level matching as n-ary correlations modeling between words of the query and frames of the video and introduce a multi-modal hypergraph for n-ary correlation modeling. By representing textual units and video frames as nodes and using hyperedges to depict their relationships, a multi-modal hypergraph is constructed. In this way, the query and the video can be aligned in a high-order semantic space. In addition, to enhance the model's generalization ability, the extracted features are fed into a variational inference component for computation, obtaining the variational representation under the Gaussian distribution. The incorporation of hypergraphs and variational inference allows our model to capture complex, n-ary interactions among textual and visual contents. Experimental results demonstrate that our proposed method achieves state-of-the-art performance on the text-video retrieval task.