 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp in Gaussians: Fast Monocular Reconstruction of Dynamic Hand-Object Interactions
Apr 14, 2026We present Grasp in Gaussians (GraG), a fast and robust method for reconstructing dynamic 3D hand-object interactions from a single monocular video. Unlike recent approaches that optimize heavy neural representations, our method focuses on tracking the hand and the object efficiently, once initialized from pretrained large models. Our key insight is that accurate and temporally stable hand-object motion can be recovered using a compact Sum-of-Gaussians (SoG) representation, revived from classical tracking literature and integrated with generative Gaussian-based initializations. We initialize object pose and geometry using a video-adapted SAM3D pipeline, then convert the resulting dense Gaussian representation into a lightweight SoG via subsampling. This compact representation enables efficient and fast tracking while preserving geometric fidelity. For the hand, we adopt a complementary strategy: starting from off-the-shelf monocular hand pose initialization, we refine hand motion using simple yet effective 2D joint and depth alignment losses, avoiding per-frame refinement of a detailed 3D hand appearance model while maintaining stable articulation. Extensive experiments on public benchmarks demonstrate that GraG reconstructs temporally coherent hand-object interactions on long sequences 6.4x faster than prior work while improving object reconstruction by 13.4% and reducing hand's per-joint position error by over 65%.
Structured Contrastive Learning for Interpretable Latent Representations
Nov 18, 2025Neural networks exhibit severe brittleness to semantically irrelevant transformations. A mere 75ms electrocardiogram (ECG) phase shift degrades latent cosine similarity from 1.0 to 0.2, while sensor rotations collapse activity recognition performance with inertial measurement units (IMUs). We identify the root cause as "laissez-faire" representation learning, where latent spaces evolve unconstrained provided task performance is satisfied. We propose Structured Contrastive Learning (SCL), a framework that partitions latent space representations into three semantic groups: invariant features that remain consistent under given transformations (e.g., phase shifts or rotations), variant features that actively differentiate transformations via a novel variant mechanism, and free features that preserve task flexibility. This creates controllable push-pull dynamics where different latent dimensions serve distinct, interpretable purposes. The variant mechanism enhances contrastive learning by encouraging variant features to differentiate within positive pairs, enabling simultaneous robustness and interpretability. Our approach requires no architectural modifications and integrates seamlessly into existing training pipelines. Experiments on ECG phase invariance and IMU rotation robustness demonstrate superior performance: ECG similarity improves from 0.25 to 0.91 under phase shifts, while WISDM activity recognition achieves 86.65% accuracy with 95.38% rotation consistency, consistently outperforming traditional data augmentation. This work represents a paradigm shift from reactive data augmentation to proactive structural learning, enabling interpretable latent representations in neural networks.
CardioRAG: A Retrieval-Augmented Generation Framework for Multimodal Chagas Disease Detection
Oct 02, 2025


Chagas disease affects nearly 6 million people worldwide, with Chagas cardiomyopathy representing its most severe complication. In regions where serological testing capacity is limited, AI-enhanced electrocardiogram (ECG) screening provides a critical diagnostic alternative. However, existing machine learning approaches face challenges such as limited accuracy, reliance on large labeled datasets, and more importantly, weak integration with evidence-based clinical diagnostic indicators. We propose a retrieval-augmented generation framework, CardioRAG, integrating large language models with interpretable ECG-based clinical features, including right bundle branch block, left anterior fascicular block, and heart rate variability metrics. The framework uses variational autoencoder-learned representations for semantic case retrieval, providing contextual cases to guide clinical reasoning. Evaluation demonstrated high recall performance of 89.80%, with a maximum F1 score of 0.68 for effective identification of positive cases requiring prioritized serological testing. CardioRAG provides an interpretable, clinical evidence-based approach particularly valuable for resource-limited settings, demonstrating a pathway for embedding clinical indicators into trustworthy medical AI systems.
COBRA: Multimodal Sensing Deep Learning Framework for Remote Chronic Obesity Management via Wrist-Worn Activity Monitoring
Sep 04, 2025Chronic obesity management requires continuous monitoring of energy balance behaviors, yet traditional self-reported methods suffer from significant underreporting and recall bias, and difficulty in integration with modern digital health systems. This study presents COBRA (Chronic Obesity Behavioral Recognition Architecture), a novel deep learning framework for objective behavioral monitoring using wrist-worn multimodal sensors. COBRA integrates a hybrid D-Net architecture combining U-Net spatial modeling, multi-head self-attention mechanisms, and BiLSTM temporal processing to classify daily activities into four obesity-relevant categories: Food Intake, Physical Activity, Sedentary Behavior, and Daily Living. Validated on the WISDM-Smart dataset with 51 subjects performing 18 activities, COBRA's optimal preprocessing strategy combines spectral-temporal feature extraction, achieving high performance across multiple architectures. D-Net demonstrates 96.86% overall accuracy with category-specific F1-scores of 98.55% (Physical Activity), 95.53% (Food Intake), 94.63% (Sedentary Behavior), and 98.68% (Daily Living), outperforming state-of-the-art baselines by 1.18% in accuracy. The framework shows robust generalizability with low demographic variance (<3%), enabling scalable deployment for personalized obesity interventions and continuous lifestyle monitoring.
FltLM: An Intergrated Long-Context Large Language Model for Effective Context Filtering and Understanding
Oct 09, 2024
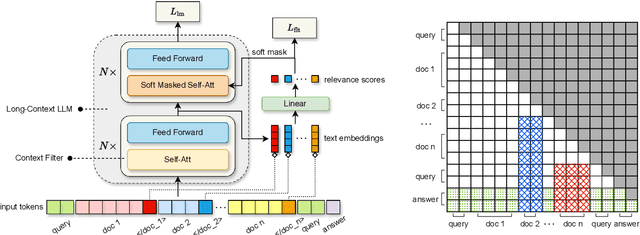

The development of Long-Context Large Language Models (LLMs) has markedly advanced natural language processing by facilitating the process of textual data across long documents and multiple corpora. However, Long-Context LLMs still face two critical challenges: The lost in the middle phenomenon, where crucial middle-context information is likely to be missed, and the distraction issue that the models lose focus due to overly extended contexts. To address these challenges, we propose the Context Filtering Language Model (FltLM), a novel integrated Long-Context LLM which enhances the ability of the model on multi-document question-answering (QA) tasks. Specifically, FltLM innovatively incorporates a context filter with a soft mask mechanism, identifying and dynamically excluding irrelevant content to concentrate on pertinent information for better comprehension and reasoning. Our approach not only mitigates these two challenges, but also enables the model to operate conveniently in a single forward pass. Experimental results demonstrate that FltLM significantly outperforms supervised fine-tuning and retrieval-based methods in complex QA scenarios, suggesting a promising solution for more accurate and reliable long-context natural language understanding applications.
Spectral Graphormer: Spectral Graph-based Transformer for Egocentric Two-Hand Reconstruction using Multi-View Color Images
Aug 21, 2023We propose a novel transformer-based framework that reconstructs two high fidelity hands from multi-view RGB images. Unlike existing hand pose estimation methods, where one typically trains a deep network to regress hand model parameters from single RGB image, we consider a more challenging problem setting where we directly regress the absolute root poses of two-hands with extended forearm at high resolution from egocentric view. As existing datasets are either infeasible for egocentric viewpoints or lack background variations, we create a large-scale synthetic dataset with diverse scenarios and collect a real dataset from multi-calibrated camera setup to verify our proposed multi-view image feature fusion strategy. To make the reconstruction physically plausible, we propose two strategies: (i) a coarse-to-fine spectral graph convolution decoder to smoothen the meshes during upsampling and (ii) an optimisation-based refinement stage at inference to prevent self-penetrations. Through extensive quantitative and qualitative evaluations, we show that our framework is able to produce realistic two-hand reconstructions and demonstrate the generalisation of synthetic-trained models to real data, as well as real-time AR/VR applications.
HD-Fusion: Detailed Text-to-3D Generation Leveraging Multiple Noise Estimation
Jul 30, 2023
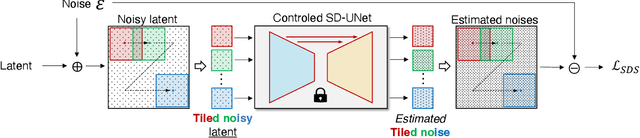
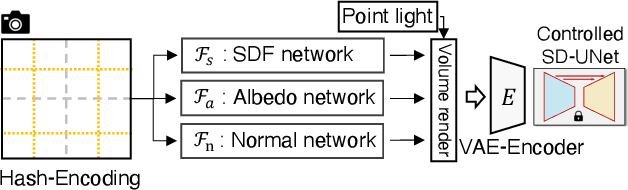
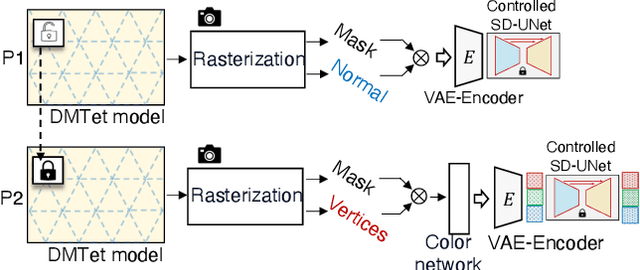
In this paper, we study Text-to-3D content generation leveraging 2D diffusion priors to enhance the quality and detail of the generated 3D models. Recent progress (Magic3D) in text-to-3D has shown that employing high-resolution (e.g., 512 x 512) renderings can lead to the production of high-quality 3D models using latent diffusion priors. To enable rendering at even higher resolutions, which has the potential to further augment the quality and detail of the models, we propose a novel approach that combines multiple noise estimation processes with a pretrained 2D diffusion prior. Distinct from the Bar-Tal et al.s' study which binds multiple denoised results to generate images from texts, our approach integrates the computation of scoring distillation losses such as SDS loss and VSD loss which are essential techniques for the 3D content generation with 2D diffusion priors. We experimentally evaluated the proposed approach. The results show that the proposed approach can generate high-quality details compared to the baselines.
PDO-s3DCNNs: Partial Differential Operator Based Steerable 3D CNNs
Aug 07, 2022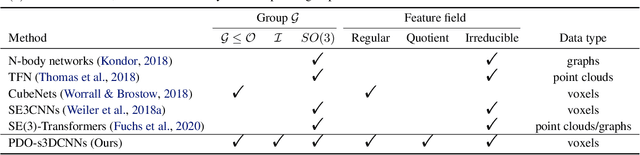
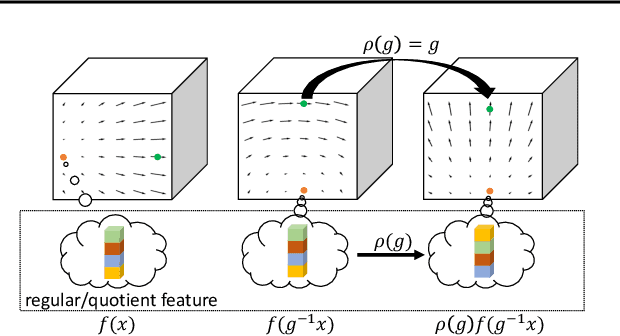

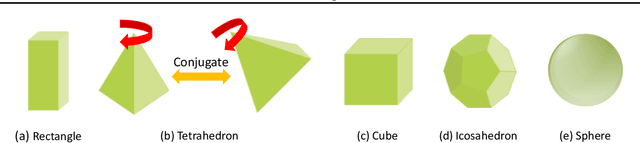
Steerable models can provide very general and flexible equivariance by formulating equivariance requirements in the language of representation theory and feature fields, which has been recognized to be effective for many vision tasks. However, deriving steerable models for 3D rotations is much more difficult than that in the 2D case, due to more complicated mathematics of 3D rotations. In this work, we employ partial differential operators (PDOs) to model 3D filters, and derive general steerable 3D CNNs, which are called PDO-s3DCNNs. We prove that the equivariant filters are subject to linear constraints, which can be solved efficiently under various conditions. As far as we know, PDO-s3DCNNs are the most general steerable CNNs for 3D rotations, in the sense that they cover all common subgroups of $SO(3)$ and their representations, while existing methods can only be applied to specific groups and representations. Extensive experiments show that our models can preserve equivariance well in the discrete domain, and outperform previous works on SHREC'17 retrieval and ISBI 2012 segmentation tasks with a low network complexity.
Fluid registration between lung CT and stationary chest tomosynthesis images
Mar 06, 2022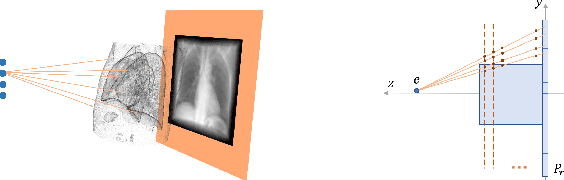

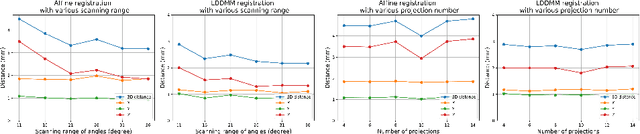
Registration is widely used in image-guided therapy and image-guided surgery to estimate spatial correspondences between organs of interest between planning and treatment images. However, while high-quality computed tomography (CT) images are often available at planning time, limited angle acquisitions are frequently used during treatment because of radiation concerns or imaging time constraints. This requires algorithms to register CT images based on limited angle acquisitions. We, therefore, formulate a 3D/2D registration approach which infers a 3D deformation based on measured projections and digitally reconstructed radiographs of the CT. Most 3D/2D registration approaches use simple transformation models or require complex mathematical derivations to formulate the underlying optimization problem. Instead, our approach entirely relies on differentiable operations which can be combined with modern computational toolboxes supporting automatic differentiation. This then allows for rapid prototyping, integration with deep neural networks, and to support a variety of transformation models including fluid flow models. We demonstrate our approach for the registration between CT and stationary chest tomosynthesis (sDCT) images and show how it naturally leads to an iterative image reconstruction approach.
Accurate Point Cloud Registration with Robust Optimal Transport
Nov 01, 2021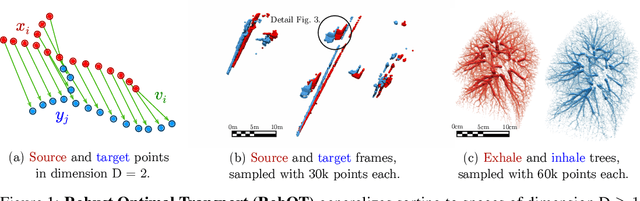
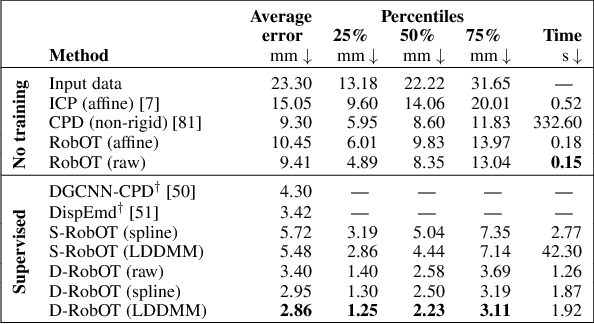
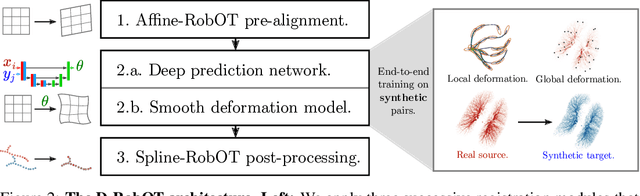
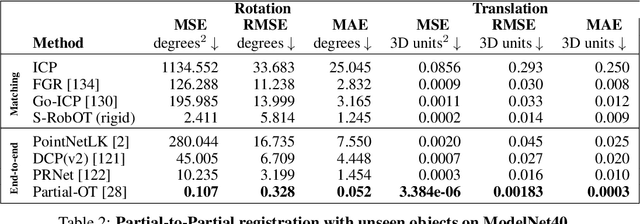
This work investigates the use of robust optimal transport (OT) for shape matching. Specifically, we show that recent OT solvers improve both optimization-based and deep learning methods for point cloud registration, boosting accuracy at an affordable computational cost. This manuscript starts with a practical overview of modern OT theory. We then provide solutions to the main difficulties in using this framework for shape matching. Finally, we showcase the performance of transport-enhanced registration models on a wide range of challenging tasks: rigid registration for partial shapes; scene flow estimation on the Kitti dataset; and nonparametric registration of lung vascular trees between inspiration and expiration. Our OT-based methods achieve state-of-the-art results on Kitti and for the challenging lung registration task, both in terms of accuracy and scalability. We also release PVT1010, a new public dataset of 1,010 pairs of lung vascular trees with densely sampled points. This dataset provides a challenging use case for point cloud registration algorithms with highly complex shapes and deformations. Our work demonstrates that robust OT enables fast pre-alignment and fine-tuning for a wide range of registration models, thereby providing a new key method for the computer vision toolbox. Our code and dataset are available online at: https://github.com/uncbiag/robot.