 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHD-Fusion: Detailed Text-to-3D Generation Leveraging Multiple Noise Estimation
Paper and Code
Jul 30, 2023
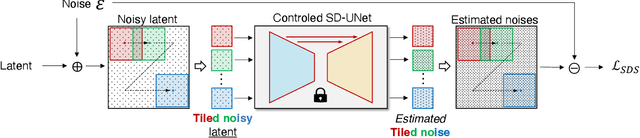
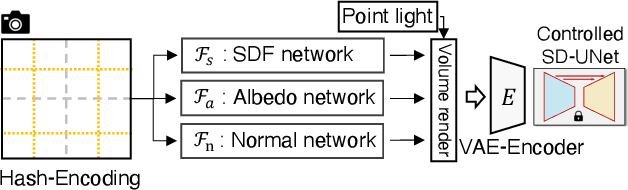
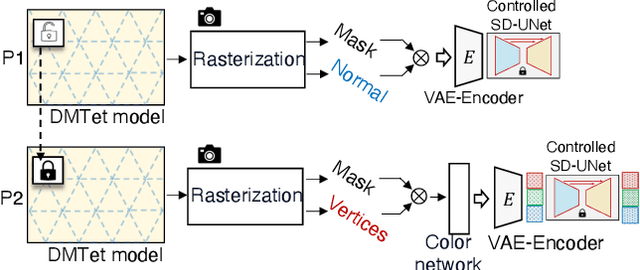
In this paper, we study Text-to-3D content generation leveraging 2D diffusion priors to enhance the quality and detail of the generated 3D models. Recent progress (Magic3D) in text-to-3D has shown that employing high-resolution (e.g., 512 x 512) renderings can lead to the production of high-quality 3D models using latent diffusion priors. To enable rendering at even higher resolutions, which has the potential to further augment the quality and detail of the models, we propose a novel approach that combines multiple noise estimation processes with a pretrained 2D diffusion prior. Distinct from the Bar-Tal et al.s' study which binds multiple denoised results to generate images from texts, our approach integrates the computation of scoring distillation losses such as SDS loss and VSD loss which are essential techniques for the 3D content generation with 2D diffusion priors. We experimentally evaluated the proposed approach. The results show that the proposed approach can generate high-quality details compared to the baselines.