 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEPHand: View-Efficient Photometric Hand Performance Capture at Scale
Jun 18, 2026Robust, high-fidelity 3D hand capture, while fundamental to digital human creation, remains challenging with practical multi-view systems that balance rich photometry with the geometric ambiguities of reconstruction arising from limited viewpoint density. This paper presents an end-to-end pipeline for dynamic hand performance capture and registration, specifically designed for view-efficient setups ($\sim$20 views). We address key challenges with two primary innovations. First, to overcome reconstruction difficulties like limited view overlap and background clutter, our mask-free neural method robustly extracts detailed hand geometry and appearance from unmasked images using scene parameterization and scenario-specific density regularization. Second, addressing registration challenges such as accurately capturing non-linear skin deformations and ensuring plausible results during severe self-contact, we propose a physics-inspired framework. It aligns reconstructions to a personalized hand model by optimizing intrinsic volumetric offsets within its canonical tetrahedral mesh, alongside pose parameters. This approach, supported by robust losses and optimization, captures fine surface deformations, ensures plausible results under severe articulation and self-contact, and demonstrates strong tolerance to input noise. We demonstrate the scalability and robustness of our automated pipeline on an extensive dataset of over 12,000 sequences, from which we also derive a large-scale, high-quality synthetic 2D/3D hand dataset for training downstream tasks. This showcases its effectiveness for single hands, intricate two-hand interactions, and natural hand-object manipulations. Our method achieves state-of-the-art reconstruction fidelity in view-efficient, unmasked scenarios and highly accurate registration. Our project page are available at https://vephand.github.io/.
High-Fidelity 4D Hand-Object Capture via Multi-View Spatiotemporal Tracking and Physics-Aware Gaussians
Jun 18, 2026The growing demand for high-fidelity 4D hand-object interaction (HOI) data in embodied AI and spatial computing is currently bottlenecked by the reliance on pre-scanned object templates and physical markers. While recent methods have demonstrated promising results in reconstructing 4D hand-object interaction from videos, they are highly sensitive to initial estimates of hand and object poses. Yet, estimating these poses from images is challenging, in particular under severe occlusion which is inherent in hand-object interaction scenarios. We propose a novel system for the robust and accurate reconstruction of hands and objects from synchronized and calibrated multi-view videos without requiring any templates or markers. Our system consists of two main components with key innovations: (1) a multi-view feed-forward transformer model that aggregates cross-view geometry and temporal cues to provide a reliable, metric-consistent initialization for both poses and dense object geometry, and (2) a hand-object physics-aware Gaussian-based optimization framework to refine the initial estimates, integrating tetrahedral constraints, collision refinement, and appearance decomposition to produce physically plausible and visually accurate reconstruction. Validated on public benchmarks and an extensive internal dataset, our pipeline achieves highly robust, artifact-free reconstruction, providing an efficient foundation for automated 4D asset generation. Our project page are available at https://zyshen021.github.io/HOSTPG/.
Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Apr 02, 20243D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
Spectral Graphormer: Spectral Graph-based Transformer for Egocentric Two-Hand Reconstruction using Multi-View Color Images
Aug 21, 2023We propose a novel transformer-based framework that reconstructs two high fidelity hands from multi-view RGB images. Unlike existing hand pose estimation methods, where one typically trains a deep network to regress hand model parameters from single RGB image, we consider a more challenging problem setting where we directly regress the absolute root poses of two-hands with extended forearm at high resolution from egocentric view. As existing datasets are either infeasible for egocentric viewpoints or lack background variations, we create a large-scale synthetic dataset with diverse scenarios and collect a real dataset from multi-calibrated camera setup to verify our proposed multi-view image feature fusion strategy. To make the reconstruction physically plausible, we propose two strategies: (i) a coarse-to-fine spectral graph convolution decoder to smoothen the meshes during upsampling and (ii) an optimisation-based refinement stage at inference to prevent self-penetrations. Through extensive quantitative and qualitative evaluations, we show that our framework is able to produce realistic two-hand reconstructions and demonstrate the generalisation of synthetic-trained models to real data, as well as real-time AR/VR applications.
Learning Personalized High Quality Volumetric Head Avatars from Monocular RGB Videos
Apr 04, 2023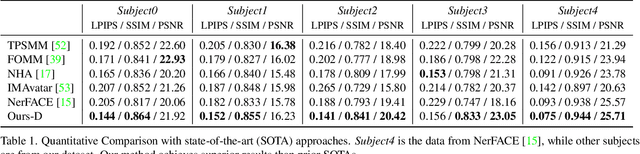
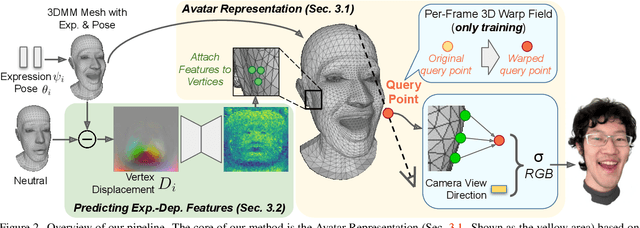
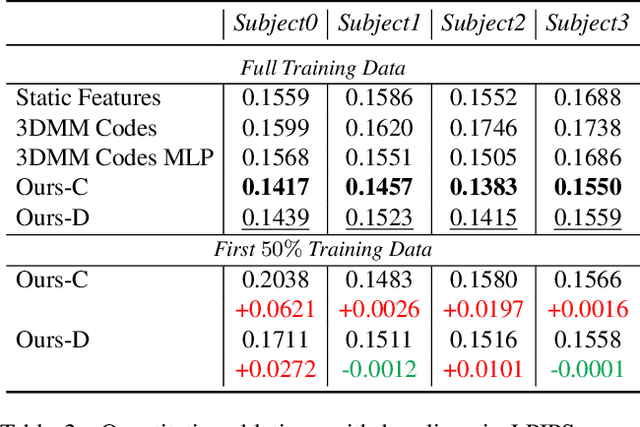
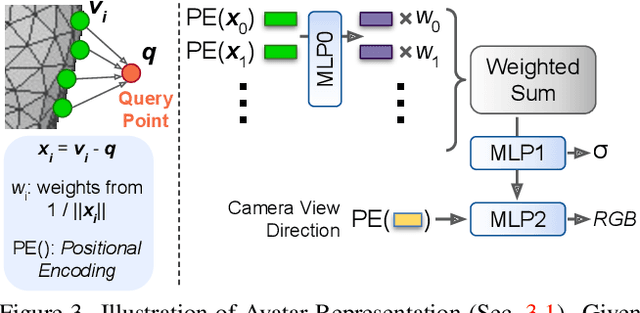
We propose a method to learn a high-quality implicit 3D head avatar from a monocular RGB video captured in the wild. The learnt avatar is driven by a parametric face model to achieve user-controlled facial expressions and head poses. Our hybrid pipeline combines the geometry prior and dynamic tracking of a 3DMM with a neural radiance field to achieve fine-grained control and photorealism. To reduce over-smoothing and improve out-of-model expressions synthesis, we propose to predict local features anchored on the 3DMM geometry. These learnt features are driven by 3DMM deformation and interpolated in 3D space to yield the volumetric radiance at a designated query point. We further show that using a Convolutional Neural Network in the UV space is critical in incorporating spatial context and producing representative local features. Extensive experiments show that we are able to reconstruct high-quality avatars, with more accurate expression-dependent details, good generalization to out-of-training expressions, and quantitatively superior renderings compared to other state-of-the-art approaches.
LoRD: Local 4D Implicit Representation for High-Fidelity Dynamic Human Modeling
Aug 18, 2022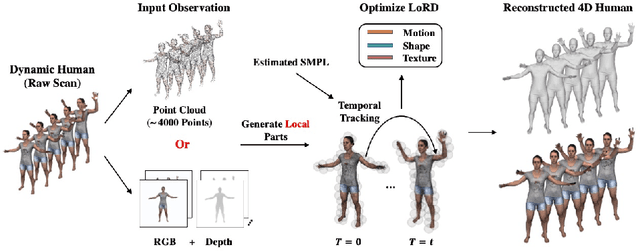

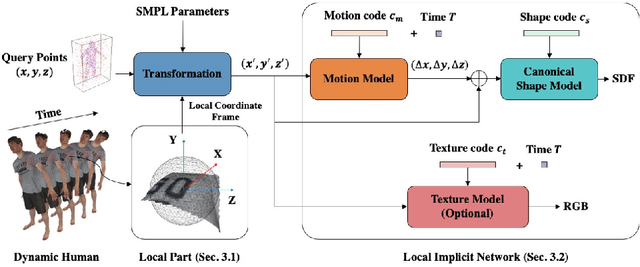
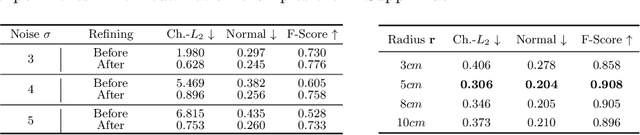
Recent progress in 4D implicit representation focuses on globally controlling the shape and motion with low dimensional latent vectors, which is prone to missing surface details and accumulating tracking error. While many deep local representations have shown promising results for 3D shape modeling, their 4D counterpart does not exist yet. In this paper, we fill this blank by proposing a novel Local 4D implicit Representation for Dynamic clothed human, named LoRD, which has the merits of both 4D human modeling and local representation, and enables high-fidelity reconstruction with detailed surface deformations, such as clothing wrinkles. Particularly, our key insight is to encourage the network to learn the latent codes of local part-level representation, capable of explaining the local geometry and temporal deformations. To make the inference at test-time, we first estimate the inner body skeleton motion to track local parts at each time step, and then optimize the latent codes for each part via auto-decoding based on different types of observed data. Extensive experiments demonstrate that the proposed method has strong capability for representing 4D human, and outperforms state-of-the-art methods on practical applications, including 4D reconstruction from sparse points, non-rigid depth fusion, both qualitatively and quantitatively.
HumanGPS: Geodesic PreServing Feature for Dense Human Correspondences
Mar 29, 2021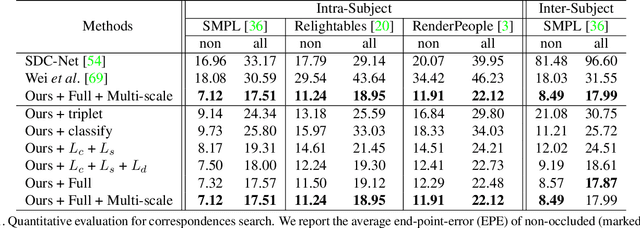

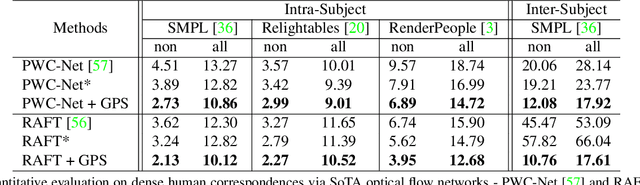
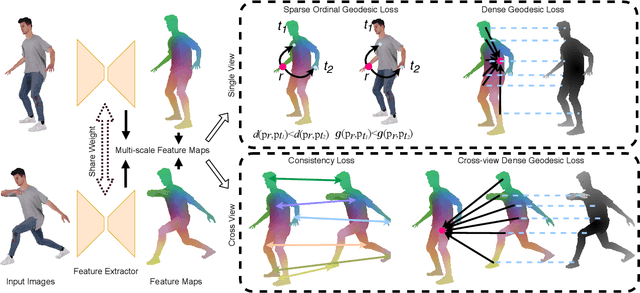
In this paper, we address the problem of building dense correspondences between human images under arbitrary camera viewpoints and body poses. Prior art either assumes small motion between frames or relies on local descriptors, which cannot handle large motion or visually ambiguous body parts, e.g., left vs. right hand. In contrast, we propose a deep learning framework that maps each pixel to a feature space, where the feature distances reflect the geodesic distances among pixels as if they were projected onto the surface of a 3D human scan. To this end, we introduce novel loss functions to push features apart according to their geodesic distances on the surface. Without any semantic annotation, the proposed embeddings automatically learn to differentiate visually similar parts and align different subjects into an unified feature space. Extensive experiments show that the learned embeddings can produce accurate correspondences between images with remarkable generalization capabilities on both intra and inter subjects.
Deep Implicit Volume Compression
May 18, 2020

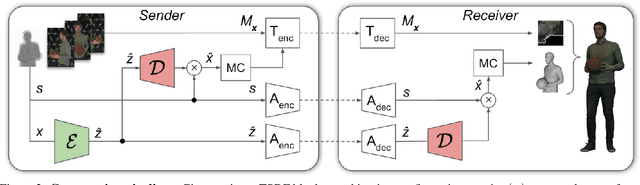
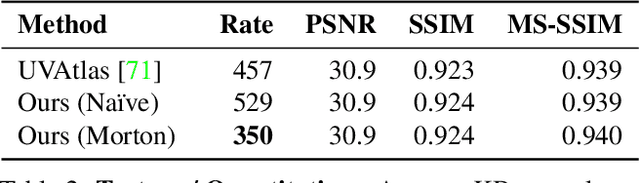
We describe a novel approach for compressing truncated signed distance fields (TSDF) stored in 3D voxel grids, and their corresponding textures. To compress the TSDF, our method relies on a block-based neural network architecture trained end-to-end, achieving state-of-the-art rate-distortion trade-off. To prevent topological errors, we losslessly compress the signs of the TSDF, which also upper bounds the reconstruction error by the voxel size. To compress the corresponding texture, we designed a fast block-based UV parameterization, generating coherent texture maps that can be effectively compressed using existing video compression algorithms. We demonstrate the performance of our algorithms on two 4D performance capture datasets, reducing bitrate by 66% for the same distortion, or alternatively reducing the distortion by 50% for the same bitrate, compared to the state-of-the-art.