 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking Together: Synthesizing Co-Located 3D Conversations from Audio
Mar 09, 2026We tackle the challenging task of generating complete 3D facial animations for two interacting, co-located participants from a mixed audio stream. While existing methods often produce disembodied "talking heads" akin to a video conference call, our work is the first to explicitly model the dynamic 3D spatial relationship -- including relative position, orientation, and mutual gaze -- that is crucial for realistic in-person dialogues. Our system synthesizes the full performance of both individuals, including precise lip-sync, and uniquely allows their relative head poses to be controlled via textual descriptions. To achieve this, we propose a dual-stream architecture where each stream is responsible for one participant's output. We employ speaker's role embeddings and inter-speaker cross-attention mechanisms designed to disentangle the mixed audio and model the interaction. Furthermore, we introduce a novel eye gaze loss to promote natural, mutual eye contact. To power our data-hungry approach, we introduce a novel pipeline to curate a large-scale conversational dataset consisting of over 2 million dyadic pairs from in-the-wild videos. Our method generates fluid, controllable, and spatially aware dyadic animations suitable for immersive applications in VR and telepresence, significantly outperforming existing baselines in perceived realism and interaction coherence.
LightAvatar: Efficient Head Avatar as Dynamic Neural Light Field
Sep 26, 2024
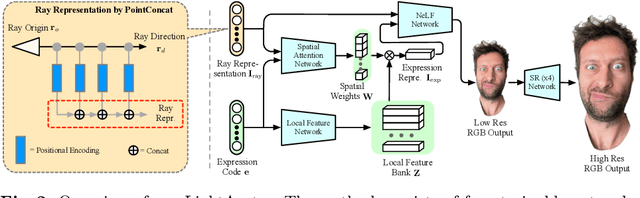


Recent works have shown that neural radiance fields (NeRFs) on top of parametric models have reached SOTA quality to build photorealistic head avatars from a monocular video. However, one major limitation of the NeRF-based avatars is the slow rendering speed due to the dense point sampling of NeRF, preventing them from broader utility on resource-constrained devices. We introduce LightAvatar, the first head avatar model based on neural light fields (NeLFs). LightAvatar renders an image from 3DMM parameters and a camera pose via a single network forward pass, without using mesh or volume rendering. The proposed approach, while being conceptually appealing, poses a significant challenge towards real-time efficiency and training stability. To resolve them, we introduce dedicated network designs to obtain proper representations for the NeLF model and maintain a low FLOPs budget. Meanwhile, we tap into a distillation-based training strategy that uses a pretrained avatar model as teacher to synthesize abundant pseudo data for training. A warping field network is introduced to correct the fitting error in the real data so that the model can learn better. Extensive experiments suggest that our method can achieve new SOTA image quality quantitatively or qualitatively, while being significantly faster than the counterparts, reporting 174.1 FPS (512x512 resolution) on a consumer-grade GPU (RTX3090) with no customized optimization.
Evaluating the Visual Similarity of Southwest China's Ethnic Minority Brocade Based on Deep Learning
Aug 26, 2024



This paper employs deep learning methods to investigate the visual similarity of ethnic minority patterns in Southwest China. A customized SResNet-18 network was developed, achieving an accuracy of 98.7% on the test set, outperforming ResNet-18, VGGNet-16, and AlexNet. The extracted feature vectors from SResNet-18 were evaluated using three metrics: cosine similarity, Euclidean distance, and Manhattan distance. The analysis results were visually represented on an ethnic thematic map, highlighting the connections between ethnic patterns and their regional distributions.
Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Apr 02, 20243D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
MVDD: Multi-View Depth Diffusion Models
Dec 19, 2023Denoising diffusion models have demonstrated outstanding results in 2D image generation, yet it remains a challenge to replicate its success in 3D shape generation. In this paper, we propose leveraging multi-view depth, which represents complex 3D shapes in a 2D data format that is easy to denoise. We pair this representation with a diffusion model, MVDD, that is capable of generating high-quality dense point clouds with 20K+ points with fine-grained details. To enforce 3D consistency in multi-view depth, we introduce an epipolar line segment attention that conditions the denoising step for a view on its neighboring views. Additionally, a depth fusion module is incorporated into diffusion steps to further ensure the alignment of depth maps. When augmented with surface reconstruction, MVDD can also produce high-quality 3D meshes. Furthermore, MVDD stands out in other tasks such as depth completion, and can serve as a 3D prior, significantly boosting many downstream tasks, such as GAN inversion. State-of-the-art results from extensive experiments demonstrate MVDD's excellent ability in 3D shape generation, depth completion, and its potential as a 3D prior for downstream tasks.
Generalizing Neural Human Fitting to Unseen Poses With Articulated SE(3) Equivariance
Apr 20, 2023


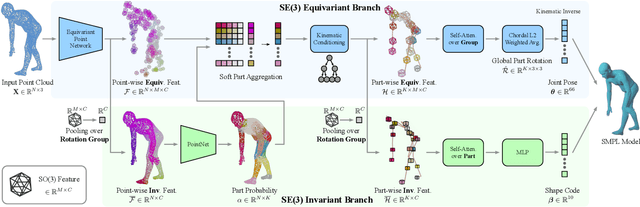
We address the problem of fitting a parametric human body model (SMPL) to point cloud data. Optimization-based methods require careful initialization and are prone to becoming trapped in local optima. Learning-based methods address this but do not generalize well when the input pose is far from those seen during training. For rigid point clouds, remarkable generalization has been achieved by leveraging SE(3)-equivariant networks, but these methods do not work on articulated objects. In this work we extend this idea to human bodies and propose ArtEq, a novel part-based SE(3)-equivariant neural architecture for SMPL model estimation from point clouds. Specifically, we learn a part detection network by leveraging local SO(3) invariance, and regress shape and pose using articulated SE(3) shape-invariant and pose-equivariant networks, all trained end-to-end. Our novel equivariant pose regression module leverages the permutation-equivariant property of self-attention layers to preserve rotational equivariance. Experimental results show that ArtEq can generalize to poses not seen during training, outperforming state-of-the-art methods by 74.5%, without requiring an optimization refinement step. Further, compared with competing works, our method is more than three orders of magnitude faster during inference and has 97.3% fewer parameters. The code and model will be available for research purposes at https://arteq.is.tue.mpg.de.
Exemplar-based Pattern Synthesis with Implicit Periodic Field Network
Apr 15, 2022
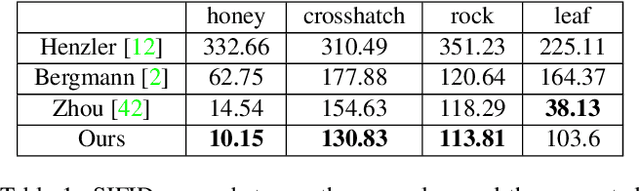
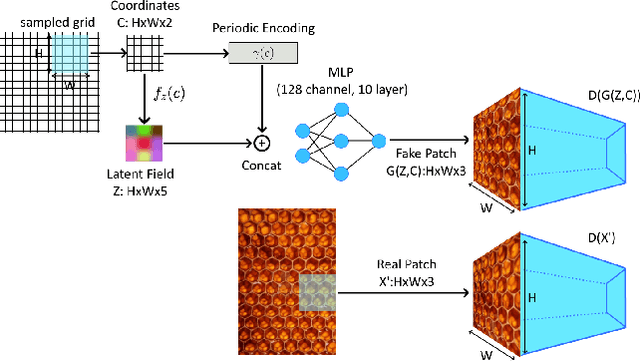
Synthesis of ergodic, stationary visual patterns is widely applicable in texturing, shape modeling, and digital content creation. The wide applicability of this technique thus requires the pattern synthesis approaches to be scalable, diverse, and authentic. In this paper, we propose an exemplar-based visual pattern synthesis framework that aims to model the inner statistics of visual patterns and generate new, versatile patterns that meet the aforementioned requirements. To this end, we propose an implicit network based on generative adversarial network (GAN) and periodic encoding, thus calling our network the Implicit Periodic Field Network (IPFN). The design of IPFN ensures scalability: the implicit formulation directly maps the input coordinates to features, which enables synthesis of arbitrary size and is computationally efficient for 3D shape synthesis. Learning with a periodic encoding scheme encourages diversity: the network is constrained to model the inner statistics of the exemplar based on spatial latent codes in a periodic field. Coupled with continuously designed GAN training procedures, IPFN is shown to synthesize tileable patterns with smooth transitions and local variations. Last but not least, thanks to both the adversarial training technique and the encoded Fourier features, IPFN learns high-frequency functions that produce authentic, high-quality results. To validate our approach, we present novel experimental results on various applications in 2D texture synthesis and 3D shape synthesis.
Topologically Consistent Multi-View Face Inference Using Volumetric Sampling
Oct 06, 2021High-fidelity face digitization solutions often combine multi-view stereo (MVS) techniques for 3D reconstruction and a non-rigid registration step to establish dense correspondence across identities and expressions. A common problem is the need for manual clean-up after the MVS step, as 3D scans are typically affected by noise and outliers and contain hairy surface regions that need to be cleaned up by artists. Furthermore, mesh registration tends to fail for extreme facial expressions. Most learning-based methods use an underlying 3D morphable model (3DMM) to ensure robustness, but this limits the output accuracy for extreme facial expressions. In addition, the global bottleneck of regression architectures cannot produce meshes that tightly fit the ground truth surfaces. We propose ToFu, Topologically consistent Face from multi-view, a geometry inference framework that can produce topologically consistent meshes across facial identities and expressions using a volumetric representation instead of an explicit underlying 3DMM. Our novel progressive mesh generation network embeds the topological structure of the face in a feature volume, sampled from geometry-aware local features. A coarse-to-fine architecture facilitates dense and accurate facial mesh predictions in a consistent mesh topology. ToFu further captures displacement maps for pore-level geometric details and facilitates high-quality rendering in the form of albedo and specular reflectance maps. These high-quality assets are readily usable by production studios for avatar creation, animation and physically-based skin rendering. We demonstrate state-of-the-art geometric and correspondence accuracy, while only taking 0.385 seconds to compute a mesh with 10K vertices, which is three orders of magnitude faster than traditional techniques. The code and the model are available for research purposes at https://tianyeli.github.io/tofu.
NeRD: Neural 3D Reflection Symmetry Detector
Apr 19, 2021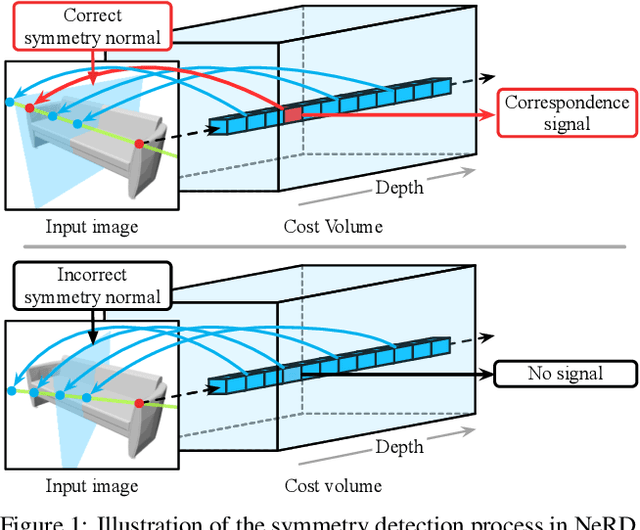
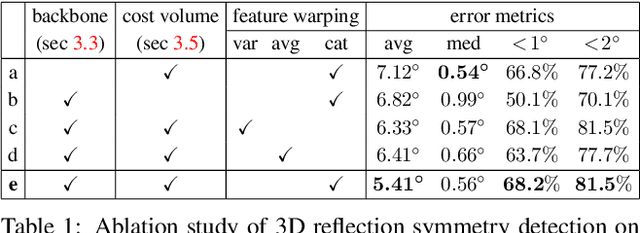
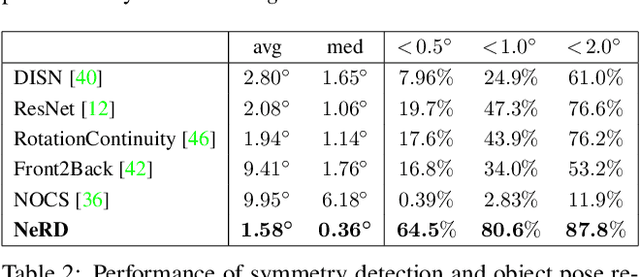
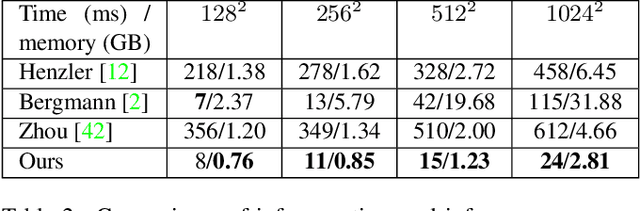
Recent advances have shown that symmetry, a structural prior that most objects exhibit, can support a variety of single-view 3D understanding tasks. However, detecting 3D symmetry from an image remains a challenging task. Previous works either assume that the symmetry is given or detect the symmetry with a heuristic-based method. In this paper, we present NeRD, a Neural 3D Reflection Symmetry Detector, which combines the strength of learning-based recognition and geometry-based reconstruction to accurately recover the normal direction of objects' mirror planes. Specifically, we first enumerate the symmetry planes with a coarse-to-fine strategy and then find the best ones by building 3D cost volumes to examine the intra-image pixel correspondence from the symmetry. Our experiments show that the symmetry planes detected with our method are significantly more accurate than the planes from direct CNN regression on both synthetic and real-world datasets. We also demonstrate that the detected symmetry can be used to improve the performance of downstream tasks such as pose estimation and depth map regression. The code of this paper has been made public at https://github.com/zhou13/nerd.
Equivariant Point Network for 3D Point Cloud Analysis
Apr 02, 2021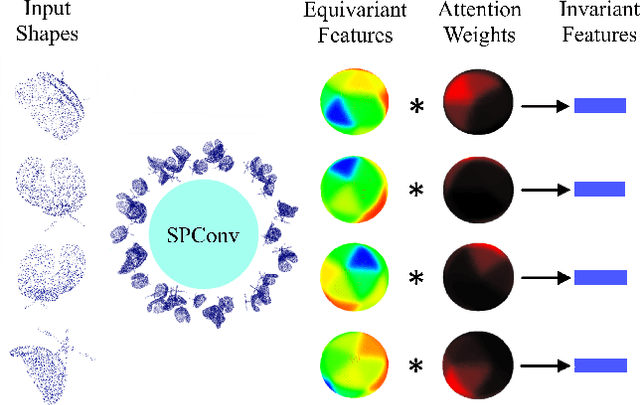
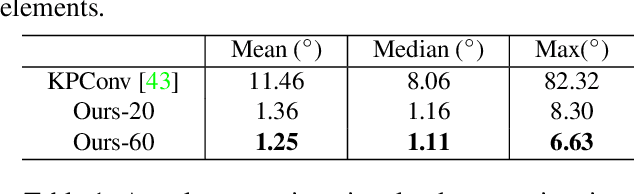
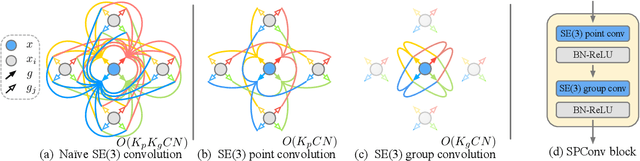
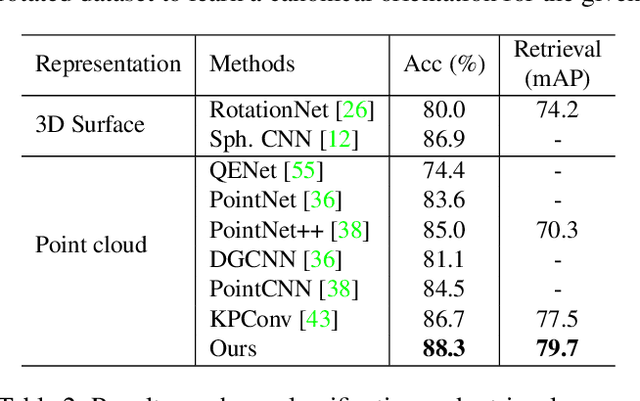
Features that are equivariant to a larger group of symmetries have been shown to be more discriminative and powerful in recent studies. However, higher-order equivariant features often come with an exponentially-growing computational cost. Furthermore, it remains relatively less explored how rotation-equivariant features can be leveraged to tackle 3D shape alignment tasks. While many past approaches have been based on either non-equivariant or invariant descriptors to align 3D shapes, we argue that such tasks may benefit greatly from an equivariant framework. In this paper, we propose an effective and practical SE(3) (3D translation and rotation) equivariant network for point cloud analysis that addresses both problems. First, we present SE(3) separable point convolution, a novel framework that breaks down the 6D convolution into two separable convolutional operators alternatively performed in the 3D Euclidean and SO(3) spaces. This significantly reduces the computational cost without compromising the performance. Second, we introduce an attention layer to effectively harness the expressiveness of the equivariant features. While jointly trained with the network, the attention layer implicitly derives the intrinsic local frame in the feature space and generates attention vectors that can be integrated into different alignment tasks. We evaluate our approach through extensive studies and visual interpretations. The empirical results demonstrate that our proposed model outperforms strong baselines in a variety of benchmarks