 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightAvatar: Efficient Head Avatar as Dynamic Neural Light Field
Sep 26, 2024
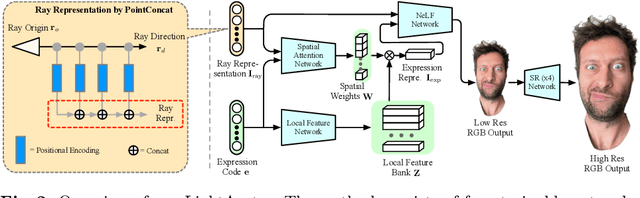


Recent works have shown that neural radiance fields (NeRFs) on top of parametric models have reached SOTA quality to build photorealistic head avatars from a monocular video. However, one major limitation of the NeRF-based avatars is the slow rendering speed due to the dense point sampling of NeRF, preventing them from broader utility on resource-constrained devices. We introduce LightAvatar, the first head avatar model based on neural light fields (NeLFs). LightAvatar renders an image from 3DMM parameters and a camera pose via a single network forward pass, without using mesh or volume rendering. The proposed approach, while being conceptually appealing, poses a significant challenge towards real-time efficiency and training stability. To resolve them, we introduce dedicated network designs to obtain proper representations for the NeLF model and maintain a low FLOPs budget. Meanwhile, we tap into a distillation-based training strategy that uses a pretrained avatar model as teacher to synthesize abundant pseudo data for training. A warping field network is introduced to correct the fitting error in the real data so that the model can learn better. Extensive experiments suggest that our method can achieve new SOTA image quality quantitatively or qualitatively, while being significantly faster than the counterparts, reporting 174.1 FPS (512x512 resolution) on a consumer-grade GPU (RTX3090) with no customized optimization.
On the Efficacy of Multi-scale Data Samplers for Vision Applications
Sep 08, 2023



Multi-scale resolution training has seen an increased adoption across multiple vision tasks, including classification and detection. Training with smaller resolutions enables faster training at the expense of a drop in accuracy. Conversely, training with larger resolutions has been shown to improve performance, but memory constraints often make this infeasible. In this paper, we empirically study the properties of multi-scale training procedures. We focus on variable batch size multi-scale data samplers that randomly sample an input resolution at each training iteration and dynamically adjust their batch size according to the resolution. Such samplers have been shown to improve model accuracy beyond standard training with a fixed batch size and resolution, though it is not clear why this is the case. We explore the properties of these data samplers by performing extensive experiments on ResNet-101 and validate our conclusions across multiple architectures, tasks, and datasets. We show that multi-scale samplers behave as implicit data regularizers and accelerate training speed. Compared to models trained with single-scale samplers, we show that models trained with multi-scale samplers retain or improve accuracy, while being better-calibrated and more robust to scaling and data distribution shifts. We additionally extend a multi-scale variable batch sampler with a simple curriculum that progressively grows resolutions throughout training, allowing for a compute reduction of more than 30%. We show that the benefits of multi-scale training extend to detection and instance segmentation tasks, where we observe a 37% reduction in training FLOPs along with a 3-4% mAP increase on MS-COCO using a Mask R-CNN model.
SPIN: An Empirical Evaluation on Sharing Parameters of Isotropic Networks
Jul 21, 2022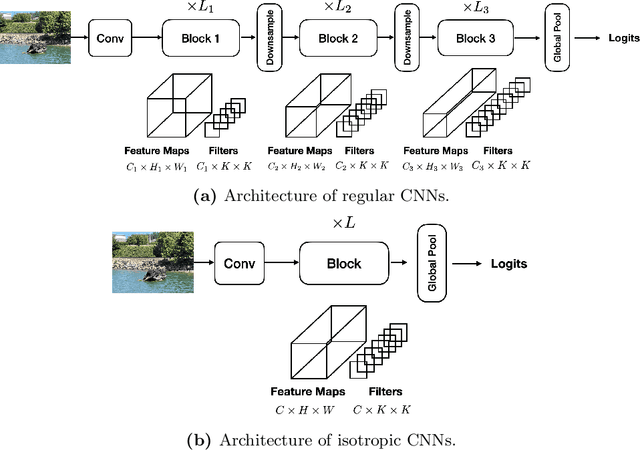
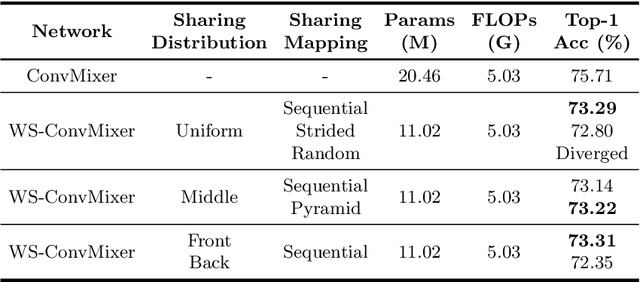
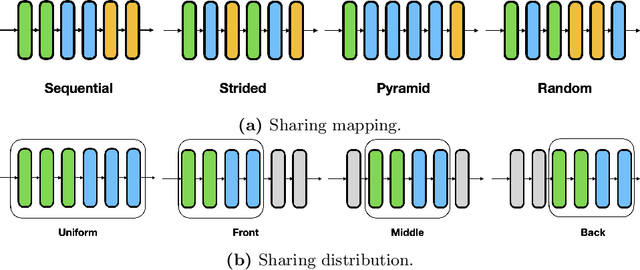
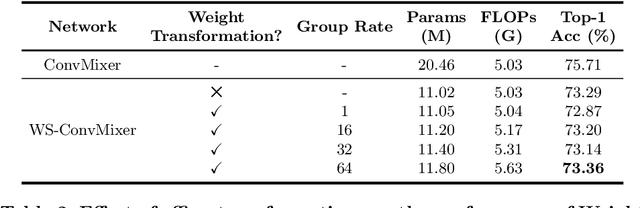
Recent isotropic networks, such as ConvMixer and vision transformers, have found significant success across visual recognition tasks, matching or outperforming non-isotropic convolutional neural networks (CNNs). Isotropic architectures are particularly well-suited to cross-layer weight sharing, an effective neural network compression technique. In this paper, we perform an empirical evaluation on methods for sharing parameters in isotropic networks (SPIN). We present a framework to formalize major weight sharing design decisions and perform a comprehensive empirical evaluation of this design space. Guided by our experimental results, we propose a weight sharing strategy to generate a family of models with better overall efficiency, in terms of FLOPs and parameters versus accuracy, compared to traditional scaling methods alone, for example compressing ConvMixer by 1.9x while improving accuracy on ImageNet. Finally, we perform a qualitative study to further understand the behavior of weight sharing in isotropic architectures. The code is available at https://github.com/apple/ml-spin.
Token Pooling in Vision Transformers
Oct 11, 2021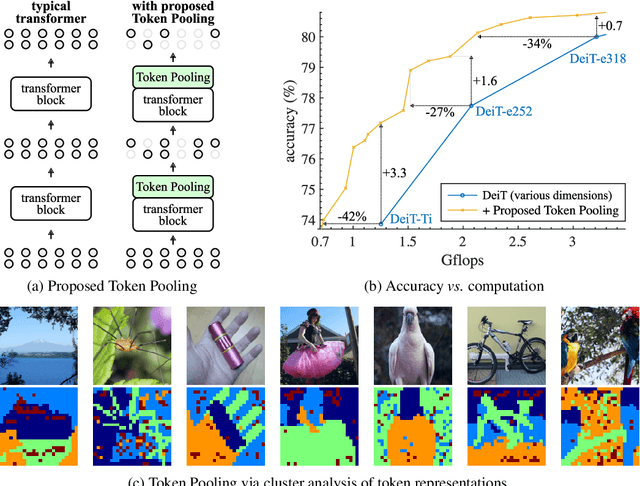
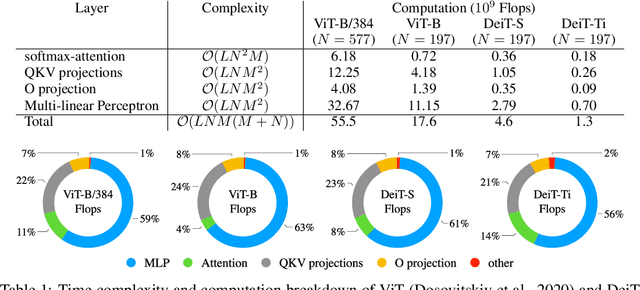
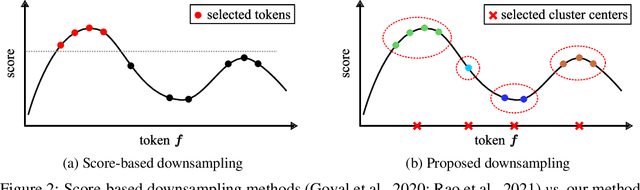
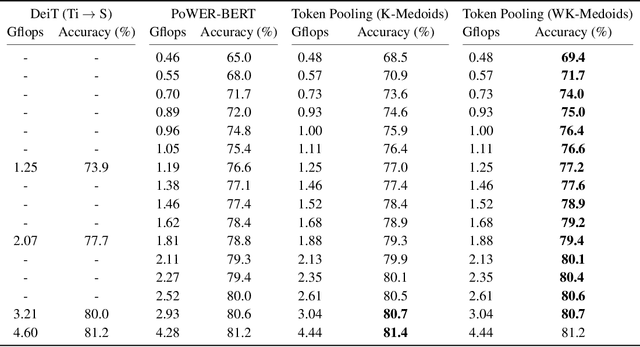
Despite the recent success in many applications, the high computational requirements of vision transformers limit their use in resource-constrained settings. While many existing methods improve the quadratic complexity of attention, in most vision transformers, self-attention is not the major computation bottleneck, e.g., more than 80% of the computation is spent on fully-connected layers. To improve the computational complexity of all layers, we propose a novel token downsampling method, called Token Pooling, efficiently exploiting redundancies in the images and intermediate token representations. We show that, under mild assumptions, softmax-attention acts as a high-dimensional low-pass (smoothing) filter. Thus, its output contains redundancy that can be pruned to achieve a better trade-off between the computational cost and accuracy. Our new technique accurately approximates a set of tokens by minimizing the reconstruction error caused by downsampling. We solve this optimization problem via cost-efficient clustering. We rigorously analyze and compare to prior downsampling methods. Our experiments show that Token Pooling significantly improves the cost-accuracy trade-off over the state-of-the-art downsampling. Token Pooling is a simple and effective operator that can benefit many architectures. Applied to DeiT, it achieves the same ImageNet top-1 accuracy using 42% fewer computations.
LCS: Learning Compressible Subspaces for Adaptive Network Compression at Inference Time
Oct 08, 2021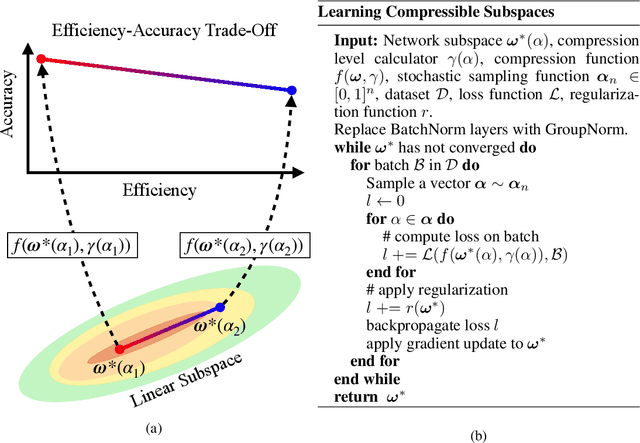

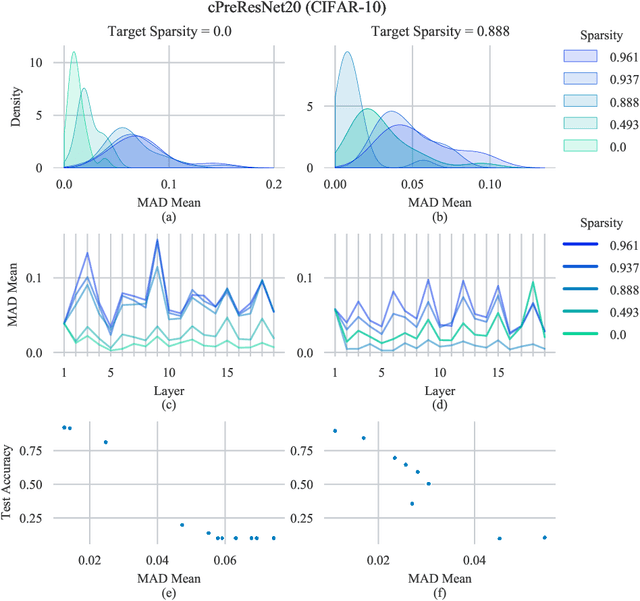
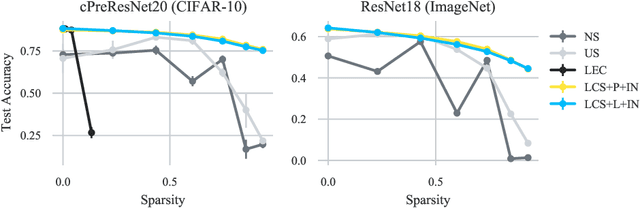
When deploying deep learning models to a device, it is traditionally assumed that available computational resources (compute, memory, and power) remain static. However, real-world computing systems do not always provide stable resource guarantees. Computational resources need to be conserved when load from other processes is high or battery power is low. Inspired by recent works on neural network subspaces, we propose a method for training a "compressible subspace" of neural networks that contains a fine-grained spectrum of models that range from highly efficient to highly accurate. Our models require no retraining, thus our subspace of models can be deployed entirely on-device to allow adaptive network compression at inference time. We present results for achieving arbitrarily fine-grained accuracy-efficiency trade-offs at inference time for structured and unstructured sparsity. We achieve accuracies on-par with standard models when testing our uncompressed models, and maintain high accuracy for sparsity rates above 90% when testing our compressed models. We also demonstrate that our algorithm extends to quantization at variable bit widths, achieving accuracy on par with individually trained networks.