 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking Together: Synthesizing Co-Located 3D Conversations from Audio
Mar 09, 2026We tackle the challenging task of generating complete 3D facial animations for two interacting, co-located participants from a mixed audio stream. While existing methods often produce disembodied "talking heads" akin to a video conference call, our work is the first to explicitly model the dynamic 3D spatial relationship -- including relative position, orientation, and mutual gaze -- that is crucial for realistic in-person dialogues. Our system synthesizes the full performance of both individuals, including precise lip-sync, and uniquely allows their relative head poses to be controlled via textual descriptions. To achieve this, we propose a dual-stream architecture where each stream is responsible for one participant's output. We employ speaker's role embeddings and inter-speaker cross-attention mechanisms designed to disentangle the mixed audio and model the interaction. Furthermore, we introduce a novel eye gaze loss to promote natural, mutual eye contact. To power our data-hungry approach, we introduce a novel pipeline to curate a large-scale conversational dataset consisting of over 2 million dyadic pairs from in-the-wild videos. Our method generates fluid, controllable, and spatially aware dyadic animations suitable for immersive applications in VR and telepresence, significantly outperforming existing baselines in perceived realism and interaction coherence.
LegacyAvatars: Volumetric Face Avatars For Traditional Graphics Pipelines
Jan 18, 2026We introduce a novel representation for efficient classical rendering of photorealistic 3D face avatars. Leveraging recent advances in radiance fields anchored to parametric face models, our approach achieves controllable volumetric rendering of complex facial features, including hair, skin, and eyes. At enrollment time, we learn a set of radiance manifolds in 3D space to extract an explicit layered mesh, along with appearance and warp textures. During deployment, this allows us to control and animate the face through simple linear blending and alpha compositing of textures over a static mesh. This explicit representation also enables the generated avatar to be efficiently streamed online and then rendered using classical mesh and shader-based rendering on legacy graphics platforms, eliminating the need for any custom engineering or integration.
IM-Portrait: Learning 3D-aware Video Diffusion for Photorealistic Talking Heads from Monocular Videos
Apr 29, 2025We propose a novel 3D-aware diffusion-based method for generating photorealistic talking head videos directly from a single identity image and explicit control signals (e.g., expressions). Our method generates Multiplane Images (MPIs) that ensure geometric consistency, making them ideal for immersive viewing experiences like binocular videos for VR headsets. Unlike existing methods that often require a separate stage or joint optimization to reconstruct a 3D representation (such as NeRF or 3D Gaussians), our approach directly generates the final output through a single denoising process, eliminating the need for post-processing steps to render novel views efficiently. To effectively learn from monocular videos, we introduce a training mechanism that reconstructs the output MPI randomly in either the target or the reference camera space. This approach enables the model to simultaneously learn sharp image details and underlying 3D information. Extensive experiments demonstrate the effectiveness of our method, which achieves competitive avatar quality and novel-view rendering capabilities, even without explicit 3D reconstruction or high-quality multi-view training data.
LightAvatar: Efficient Head Avatar as Dynamic Neural Light Field
Sep 26, 2024
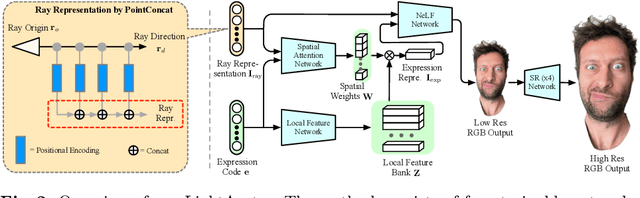


Recent works have shown that neural radiance fields (NeRFs) on top of parametric models have reached SOTA quality to build photorealistic head avatars from a monocular video. However, one major limitation of the NeRF-based avatars is the slow rendering speed due to the dense point sampling of NeRF, preventing them from broader utility on resource-constrained devices. We introduce LightAvatar, the first head avatar model based on neural light fields (NeLFs). LightAvatar renders an image from 3DMM parameters and a camera pose via a single network forward pass, without using mesh or volume rendering. The proposed approach, while being conceptually appealing, poses a significant challenge towards real-time efficiency and training stability. To resolve them, we introduce dedicated network designs to obtain proper representations for the NeLF model and maintain a low FLOPs budget. Meanwhile, we tap into a distillation-based training strategy that uses a pretrained avatar model as teacher to synthesize abundant pseudo data for training. A warping field network is introduced to correct the fitting error in the real data so that the model can learn better. Extensive experiments suggest that our method can achieve new SOTA image quality quantitatively or qualitatively, while being significantly faster than the counterparts, reporting 174.1 FPS (512x512 resolution) on a consumer-grade GPU (RTX3090) with no customized optimization.
Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Apr 02, 20243D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
One2Avatar: Generative Implicit Head Avatar For Few-shot User Adaptation
Feb 19, 2024



Traditional methods for constructing high-quality, personalized head avatars from monocular videos demand extensive face captures and training time, posing a significant challenge for scalability. This paper introduces a novel approach to create high quality head avatar utilizing only a single or a few images per user. We learn a generative model for 3D animatable photo-realistic head avatar from a multi-view dataset of expressions from 2407 subjects, and leverage it as a prior for creating personalized avatar from few-shot images. Different from previous 3D-aware face generative models, our prior is built with a 3DMM-anchored neural radiance field backbone, which we show to be more effective for avatar creation through auto-decoding based on few-shot inputs. We also handle unstable 3DMM fitting by jointly optimizing the 3DMM fitting and camera calibration that leads to better few-shot adaptation. Our method demonstrates compelling results and outperforms existing state-of-the-art methods for few-shot avatar adaptation, paving the way for more efficient and personalized avatar creation.
Learning Personalized High Quality Volumetric Head Avatars from Monocular RGB Videos
Apr 04, 2023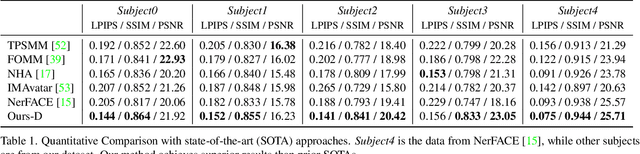
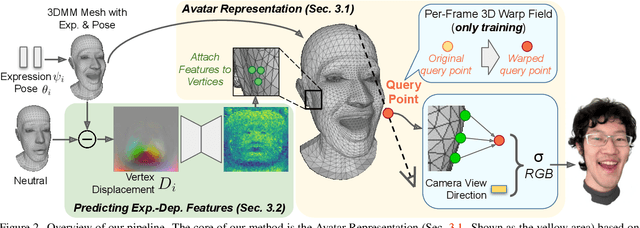
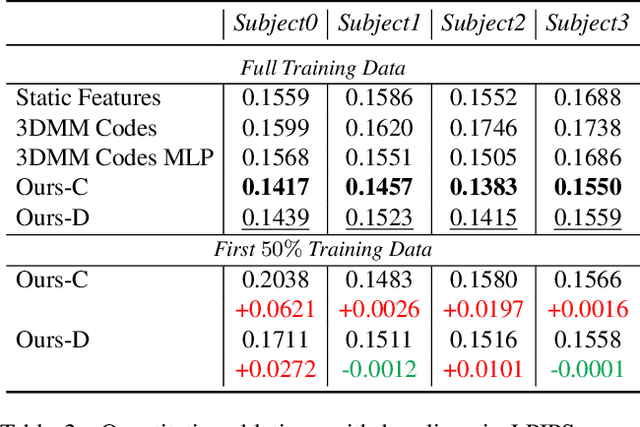
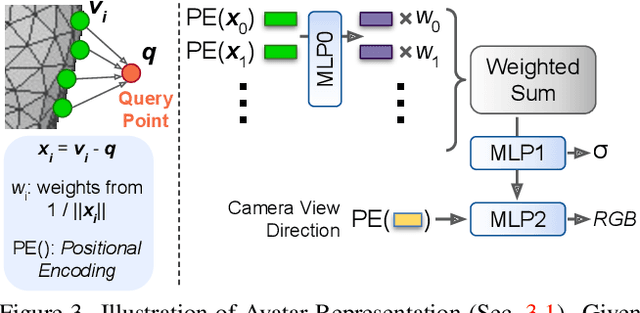
We propose a method to learn a high-quality implicit 3D head avatar from a monocular RGB video captured in the wild. The learnt avatar is driven by a parametric face model to achieve user-controlled facial expressions and head poses. Our hybrid pipeline combines the geometry prior and dynamic tracking of a 3DMM with a neural radiance field to achieve fine-grained control and photorealism. To reduce over-smoothing and improve out-of-model expressions synthesis, we propose to predict local features anchored on the 3DMM geometry. These learnt features are driven by 3DMM deformation and interpolated in 3D space to yield the volumetric radiance at a designated query point. We further show that using a Convolutional Neural Network in the UV space is critical in incorporating spatial context and producing representative local features. Extensive experiments show that we are able to reconstruct high-quality avatars, with more accurate expression-dependent details, good generalization to out-of-training expressions, and quantitatively superior renderings compared to other state-of-the-art approaches.
AutoAvatar: Autoregressive Neural Fields for Dynamic Avatar Modeling
Mar 25, 2022
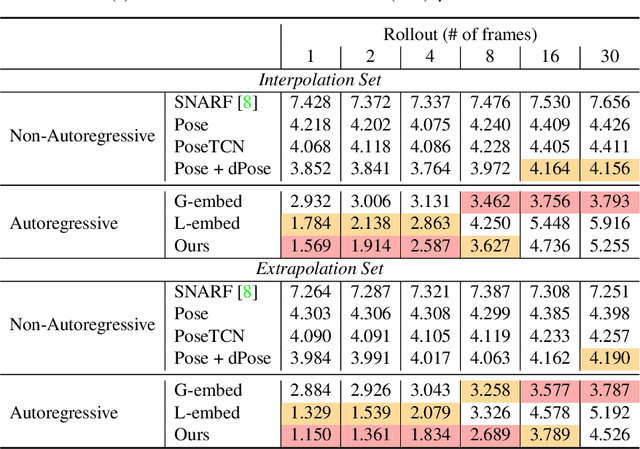
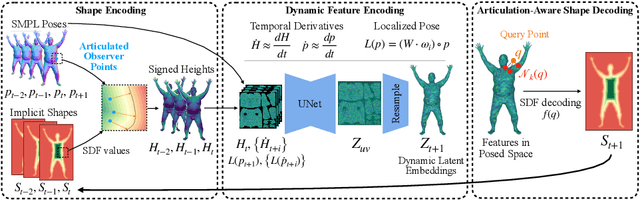
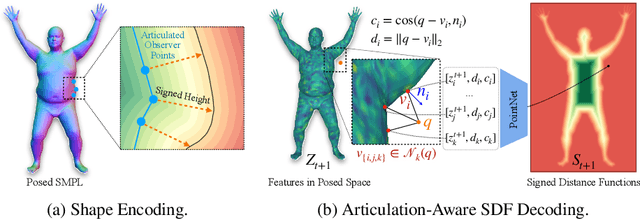
Neural fields such as implicit surfaces have recently enabled avatar modeling from raw scans without explicit temporal correspondences. In this work, we exploit autoregressive modeling to further extend this notion to capture dynamic effects, such as soft-tissue deformations. Although autoregressive models are naturally capable of handling dynamics, it is non-trivial to apply them to implicit representations, as explicit state decoding is infeasible due to prohibitive memory requirements. In this work, for the first time, we enable autoregressive modeling of implicit avatars. To reduce the memory bottleneck and efficiently model dynamic implicit surfaces, we introduce the notion of articulated observer points, which relate implicit states to the explicit surface of a parametric human body model. We demonstrate that encoding implicit surfaces as a set of height fields defined on articulated observer points leads to significantly better generalization compared to a latent representation. The experiments show that our approach outperforms the state of the art, achieving plausible dynamic deformations even for unseen motions. https://zqbai-jeremy.github.io/autoavatar
Riggable 3D Face Reconstruction via In-Network Optimization
Apr 08, 2021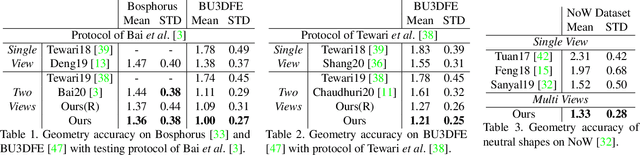
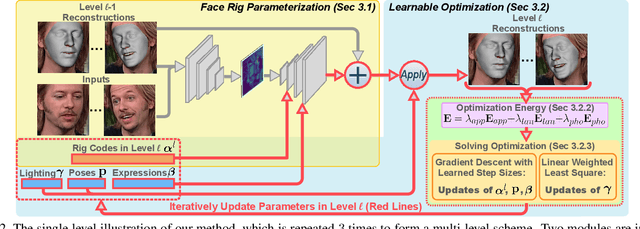
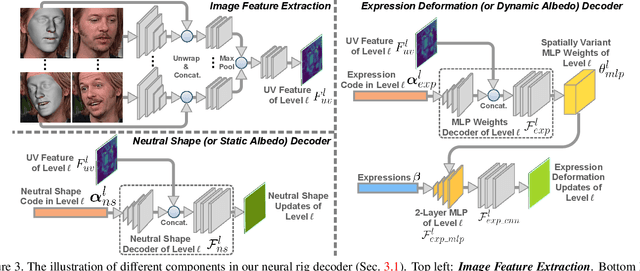

This paper presents a method for riggable 3D face reconstruction from monocular images, which jointly estimates a personalized face rig and per-image parameters including expressions, poses, and illuminations. To achieve this goal, we design an end-to-end trainable network embedded with a differentiable in-network optimization. The network first parameterizes the face rig as a compact latent code with a neural decoder, and then estimates the latent code as well as per-image parameters via a learnable optimization. By estimating a personalized face rig, our method goes beyond static reconstructions and enables downstream applications such as video retargeting. In-network optimization explicitly enforces constraints derived from the first principles, thus introduces additional priors than regression-based methods. Finally, data-driven priors from deep learning are utilized to constrain the ill-posed monocular setting and ease the optimization difficulty. Experiments demonstrate that our method achieves SOTA reconstruction accuracy, reasonable robustness and generalization ability, and supports standard face rig applications.
CodeNet: Training Large Scale Neural Networks in Presence of Soft-Errors
Mar 04, 2019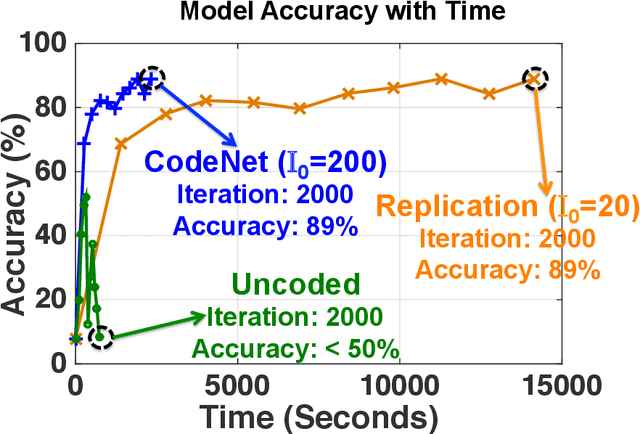
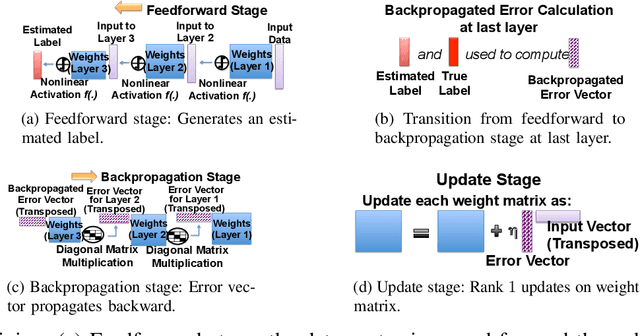
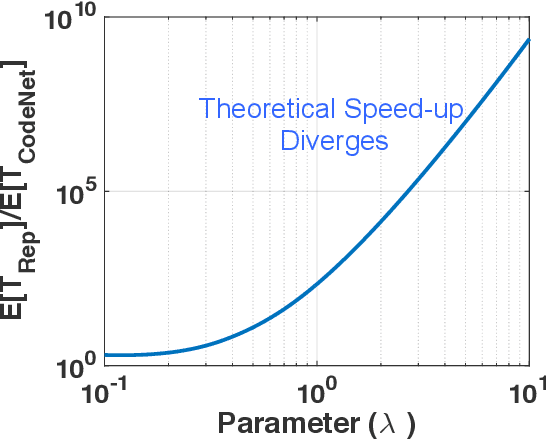
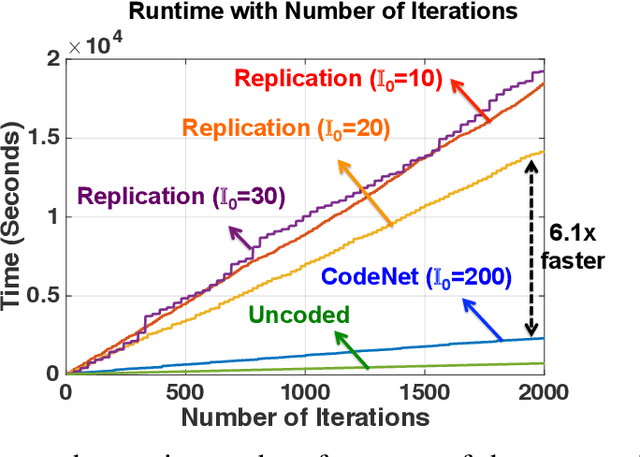
This work proposes the first strategy to make distributed training of neural networks resilient to computing errors, a problem that has remained unsolved despite being first posed in 1956 by von Neumann. He also speculated that the efficiency and reliability of the human brain is obtained by allowing for low power but error-prone components with redundancy for error-resilience. It is surprising that this problem remains open, even as massive artificial neural networks are being trained on increasingly low-cost and unreliable processing units. Our coding-theory-inspired strategy, "CodeNet," solves this problem by addressing three challenges in the science of reliable computing: (i) Providing the first strategy for error-resilient neural network training by encoding each layer separately; (ii) Keeping the overheads of coding (encoding/error-detection/decoding) low by obviating the need to re-encode the updated parameter matrices after each iteration from scratch. (iii) Providing a completely decentralized implementation with no central node (which is a single point of failure), allowing all primary computational steps to be error-prone. We theoretically demonstrate that CodeNet has higher error tolerance than replication, which we leverage to speed up computation time. Simultaneously, CodeNet requires lower redundancy than replication, and equal computational and communication costs in scaling sense. We first demonstrate the benefits of CodeNet in reducing expected computation time over replication when accounting for checkpointing. Our experiments show that CodeNet achieves the best accuracy-runtime tradeoff compared to both replication and uncoded strategies. CodeNet is a significant step towards biologically plausible neural network training, that could hold the key to orders of magnitude efficiency improvements.