 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRL-Bench: Standardizing Cross-Paradigm Representation-Level Evaluation of Tabular Encoders
Jun 08, 2026Tabular encoders are usually evaluated inside task-specific end-to-end pipelines, so models from different training paradigms are difficult to compare directly even when they operate on similar tabular signals. We introduce TRL-Bench, a multi-granular tabular representation learning (TRL) benchmark that standardizes cross-paradigm representation-level evaluation: each encoder exports row-, column-, or table embeddings through its supported wrapper, and shared lightweight heads probe them across three suites: TRL-CTbench (column/table), TRL-Rbench (row), and TRL-DLTE (compositional Data-Lake Table Enrichment spanning all three granularities). To support this standardized setting, we release curated benchmark assets and task reformulations, including 50 OpenML tables with 123 verified targets, 16 row-pair linkage rewrites, and a 47,772-table DLTE lake derived from 1,379 parent tables. Across 20 models and 16 tasks, TRL-Bench shows that once downstream conditions are standardized, encoder quality is capability-specific rather than captured by a single leaderboard. In TRL-CTbench, generic text encoders often lead on tasks with strong surface-text signal, while tabular specialists win where their pretraining objective aligns with the task. In TRL-Rbench, within-table prediction and cross-table linkage favor different training regimes, with atomic linkage performance correlating strongly with the row-matching stage of DLTE pipelines. In TRL-DLTE, the strongest pipelines combine capability-matched specialists rather than reuse a single encoder, and top end-to-end quality depends on non-additive compositional fit rather than per-stage marginal rank alone. TRL-Bench provides a common protocol for measuring reusable signal in exported tabular representations under shared downstream conditions. Code and data: https://github.com/LOGO-CUHKSZ/TRL-Bench
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
One2Avatar: Generative Implicit Head Avatar For Few-shot User Adaptation
Feb 19, 2024



Traditional methods for constructing high-quality, personalized head avatars from monocular videos demand extensive face captures and training time, posing a significant challenge for scalability. This paper introduces a novel approach to create high quality head avatar utilizing only a single or a few images per user. We learn a generative model for 3D animatable photo-realistic head avatar from a multi-view dataset of expressions from 2407 subjects, and leverage it as a prior for creating personalized avatar from few-shot images. Different from previous 3D-aware face generative models, our prior is built with a 3DMM-anchored neural radiance field backbone, which we show to be more effective for avatar creation through auto-decoding based on few-shot inputs. We also handle unstable 3DMM fitting by jointly optimizing the 3DMM fitting and camera calibration that leads to better few-shot adaptation. Our method demonstrates compelling results and outperforms existing state-of-the-art methods for few-shot avatar adaptation, paving the way for more efficient and personalized avatar creation.
HUMBI: A Large Multiview Dataset of Human Body Expressions and Benchmark Challenge
Sep 30, 2021

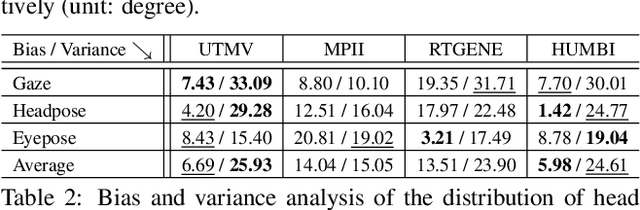
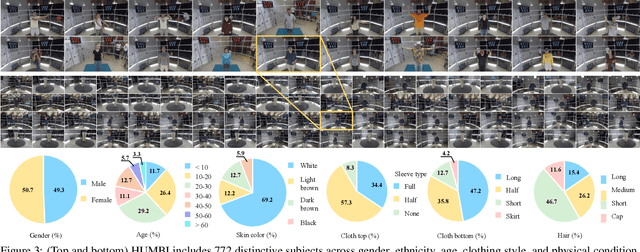
This paper presents a new large multiview dataset called HUMBI for human body expressions with natural clothing. The goal of HUMBI is to facilitate modeling view-specific appearance and geometry of five primary body signals including gaze, face, hand, body, and garment from assorted people. 107 synchronized HD cameras are used to capture 772 distinctive subjects across gender, ethnicity, age, and style. With the multiview image streams, we reconstruct high fidelity body expressions using 3D mesh models, which allows representing view-specific appearance. We demonstrate that HUMBI is highly effective in learning and reconstructing a complete human model and is complementary to the existing datasets of human body expressions with limited views and subjects such as MPII-Gaze, Multi-PIE, Human3.6M, and Panoptic Studio datasets. Based on HUMBI, we formulate a new benchmark challenge of a pose-guided appearance rendering task that aims to substantially extend photorealism in modeling diverse human expressions in 3D, which is the key enabling factor of authentic social tele-presence. HUMBI is publicly available at http://humbi-data.net
Semi-supervised Dense Keypointsusing Unlabeled Multiview Images
Sep 20, 2021
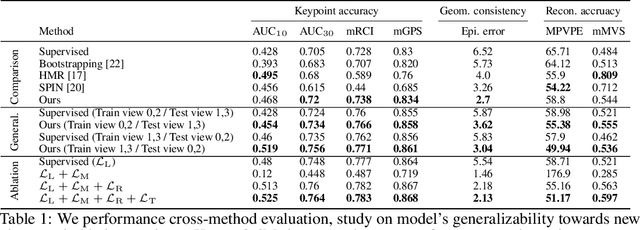


This paper presents a new end-to-end semi-supervised framework to learn a dense keypoint detector using unlabeled multiview images. A key challenge lies in finding the exact correspondences between the dense keypoints in multiple views since the inverse of keypoint mapping can be neither analytically derived nor differentiated. This limits applying existing multiview supervision approaches on sparse keypoint detection that rely on the exact correspondences. To address this challenge, we derive a new probabilistic epipolar constraint that encodes the two desired properties. (1) Soft correspondence: we define a matchability, which measures a likelihood of a point matching to the other image's corresponding point, thus relaxing the exact correspondences' requirement. (2) Geometric consistency: every point in the continuous correspondence fields must satisfy the multiview consistency collectively. We formulate a probabilistic epipolar constraint using a weighted average of epipolar errors through the matchability thereby generalizing the point-to-point geometric error to the field-to-field geometric error. This generalization facilitates learning a geometrically coherent dense keypoint detection model by utilizing a large number of unlabeled multiview images. Additionally, to prevent degenerative cases, we employ a distillation-based regularization by using a pretrained model. Finally, we design a new neural network architecture, made of twin networks, that effectively minimizes the probabilistic epipolar errors of all possible correspondences between two view images by building affinity matrices. Our method shows superior performance compared to existing methods, including non-differentiable bootstrapping in terms of keypoint accuracy, multiview consistency, and 3D reconstruction accuracy.
HUMBI 1.0: HUman Multiview Behavioral Imaging Dataset
Dec 01, 2018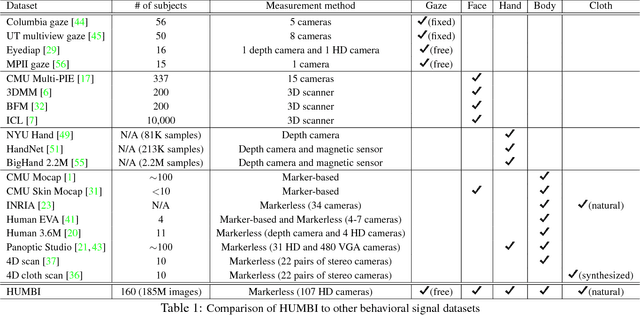



This paper presents a new dataset called HUMBI - a large corpus of high fidelity models of behavioral signals in 3D from a diverse population measured by a massive multi-camera system. With our novel design of a portable imaging system (consists of 107 HD cameras), we collect human behaviors from 164 subjects across gender, ethnicity, age, and physical condition at a public venue. Using the multiview image streams, we reconstruct high fidelity models of five elementary parts: gaze, face, hands, body, and cloth. As a byproduct, the 3D model provides geometrically consistent image annotation via 2D projection, e.g., body part segmentation. This dataset is a significant departure from the existing human datasets that suffers from subject diversity. We hope the HUMBI opens up a new opportunity for the development for behavioral imaging.