 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegacyAvatars: Volumetric Face Avatars For Traditional Graphics Pipelines
Jan 18, 2026We introduce a novel representation for efficient classical rendering of photorealistic 3D face avatars. Leveraging recent advances in radiance fields anchored to parametric face models, our approach achieves controllable volumetric rendering of complex facial features, including hair, skin, and eyes. At enrollment time, we learn a set of radiance manifolds in 3D space to extract an explicit layered mesh, along with appearance and warp textures. During deployment, this allows us to control and animate the face through simple linear blending and alpha compositing of textures over a static mesh. This explicit representation also enables the generated avatar to be efficiently streamed online and then rendered using classical mesh and shader-based rendering on legacy graphics platforms, eliminating the need for any custom engineering or integration.
S^2VG: 3D Stereoscopic and Spatial Video Generation via Denoising Frame Matrix
Aug 11, 2025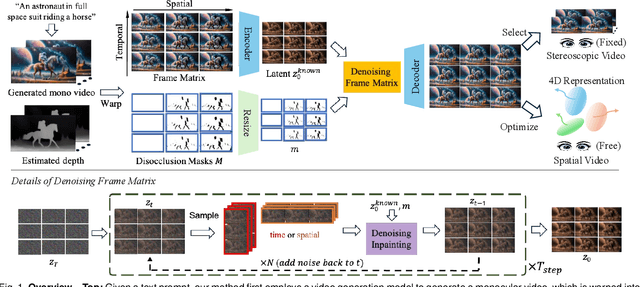

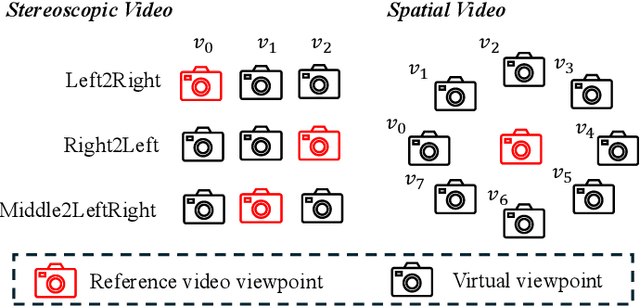

While video generation models excel at producing high-quality monocular videos, generating 3D stereoscopic and spatial videos for immersive applications remains an underexplored challenge. We present a pose-free and training-free method that leverages an off-the-shelf monocular video generation model to produce immersive 3D videos. Our approach first warps the generated monocular video into pre-defined camera viewpoints using estimated depth information, then applies a novel \textit{frame matrix} inpainting framework. This framework utilizes the original video generation model to synthesize missing content across different viewpoints and timestamps, ensuring spatial and temporal consistency without requiring additional model fine-tuning. Moreover, we develop a \dualupdate~scheme that further improves the quality of video inpainting by alleviating the negative effects propagated from disoccluded areas in the latent space. The resulting multi-view videos are then adapted into stereoscopic pairs or optimized into 4D Gaussians for spatial video synthesis. We validate the efficacy of our proposed method by conducting experiments on videos from various generative models, such as Sora, Lumiere, WALT, and Zeroscope. The experiments demonstrate that our method has a significant improvement over previous methods. Project page at: https://daipengwa.github.io/S-2VG_ProjectPage/
ToolGrad: Efficient Tool-use Dataset Generation with Textual "Gradients"
Aug 06, 2025Prior work synthesizes tool-use LLM datasets by first generating a user query, followed by complex tool-use annotations like DFS. This leads to inevitable annotation failures and low efficiency in data generation. We introduce ToolGrad, an agentic framework that inverts this paradigm. ToolGrad first constructs valid tool-use chains through an iterative process guided by textual "gradients", and then synthesizes corresponding user queries. This "answer-first" approach led to ToolGrad-5k, a dataset generated with more complex tool use, lower cost, and 100% pass rate. Experiments show that models trained on ToolGrad-5k outperform those on expensive baseline datasets and proprietary LLMs, even on OOD benchmarks.
Arm Robot: AR-Enhanced Embodied Control and Visualization for Intuitive Robot Arm Manipulation
Nov 21, 2024Embodied interaction has been introduced to human-robot interaction (HRI) as a type of teleoperation, in which users control robot arms with bodily action via handheld controllers or haptic gloves. Embodied teleoperation has made robot control intuitive to non-technical users, but differences between humans' and robots' capabilities \eg ranges of motion and response time, remain challenging. In response, we present Arm Robot, an embodied robot arm teleoperation system that helps users tackle human-robot discrepancies. Specifically, Arm Robot (1) includes AR visualization as real-time feedback on temporal and spatial discrepancies, and (2) allows users to change observing perspectives and expand action space. We conducted a user study (N=18) to investigate the usability of the Arm Robot and learn how users perceive the embodiment. Our results show users could use Arm Robot's features to effectively control the robot arm, providing insights for continued work in embodied HRI.
Thing2Reality: Transforming 2D Content into Conditioned Multiviews and 3D Gaussian Objects for XR Communication
Oct 09, 2024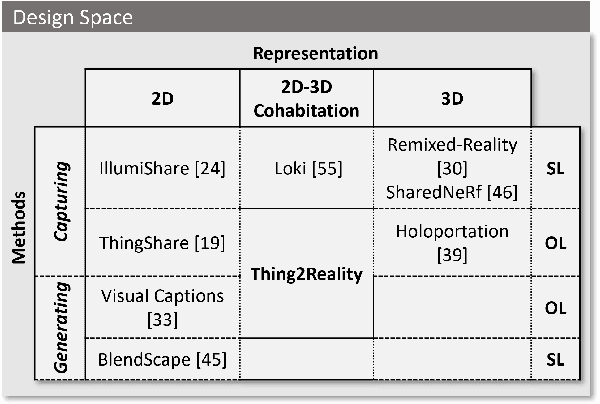
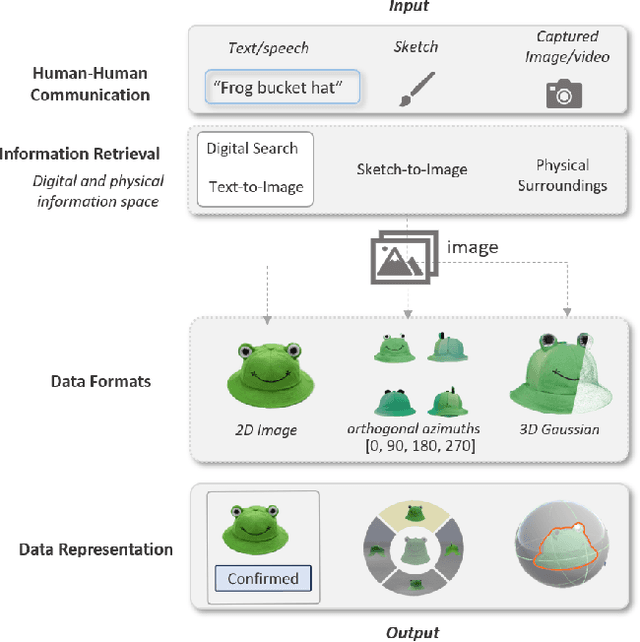
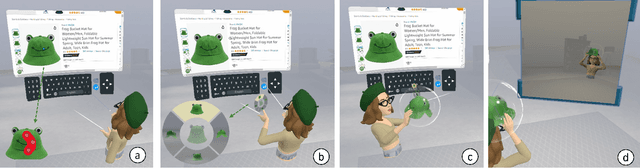
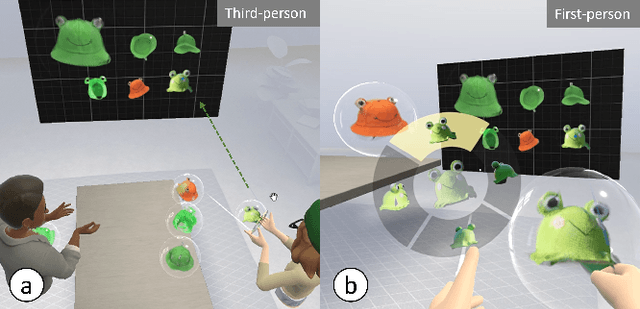
During remote communication, participants often share both digital and physical content, such as product designs, digital assets, and environments, to enhance mutual understanding. Recent advances in augmented communication have facilitated users to swiftly create and share digital 2D copies of physical objects from video feeds into a shared space. However, conventional 2D representations of digital objects restricts users' ability to spatially reference items in a shared immersive environment. To address this, we propose Thing2Reality, an Extended Reality (XR) communication platform that enhances spontaneous discussions of both digital and physical items during remote sessions. With Thing2Reality, users can quickly materialize ideas or physical objects in immersive environments and share them as conditioned multiview renderings or 3D Gaussians. Thing2Reality enables users to interact with remote objects or discuss concepts in a collaborative manner. Our user study revealed that the ability to interact with and manipulate 3D representations of objects significantly enhances the efficiency of discussions, with the potential to augment discussion of 2D artifacts.
SVG: 3D Stereoscopic Video Generation via Denoising Frame Matrix
Jun 29, 2024



Video generation models have demonstrated great capabilities of producing impressive monocular videos, however, the generation of 3D stereoscopic video remains under-explored. We propose a pose-free and training-free approach for generating 3D stereoscopic videos using an off-the-shelf monocular video generation model. Our method warps a generated monocular video into camera views on stereoscopic baseline using estimated video depth, and employs a novel frame matrix video inpainting framework. The framework leverages the video generation model to inpaint frames observed from different timestamps and views. This effective approach generates consistent and semantically coherent stereoscopic videos without scene optimization or model fine-tuning. Moreover, we develop a disocclusion boundary re-injection scheme that further improves the quality of video inpainting by alleviating the negative effects propagated from disoccluded areas in the latent space. We validate the efficacy of our proposed method by conducting experiments on videos from various generative models, including Sora [4 ], Lumiere [2], WALT [8 ], and Zeroscope [ 42]. The experiments demonstrate that our method has a significant improvement over previous methods. The code will be released at \url{https://daipengwa.github.io/SVG_ProjectPage}.
Augmented Object Intelligence: Making the Analog World Interactable with XR-Objects
Apr 23, 2024



Seamless integration of physical objects as interactive digital entities remains a challenge for spatial computing. This paper introduces Augmented Object Intelligence (AOI), a novel XR interaction paradigm designed to blur the lines between digital and physical by equipping real-world objects with the ability to interact as if they were digital, where every object has the potential to serve as a portal to vast digital functionalities. Our approach utilizes object segmentation and classification, combined with the power of Multimodal Large Language Models (MLLMs), to facilitate these interactions. We implement the AOI concept in the form of XR-Objects, an open-source prototype system that provides a platform for users to engage with their physical environment in rich and contextually relevant ways. This system enables analog objects to not only convey information but also to initiate digital actions, such as querying for details or executing tasks. Our contributions are threefold: (1) we define the AOI concept and detail its advantages over traditional AI assistants, (2) detail the XR-Objects system's open-source design and implementation, and (3) show its versatility through a variety of use cases and a user study.
FaceFolds: Meshed Radiance Manifolds for Efficient Volumetric Rendering of Dynamic Faces
Apr 22, 2024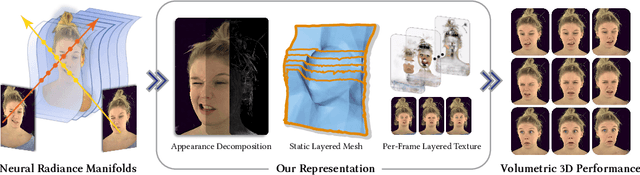

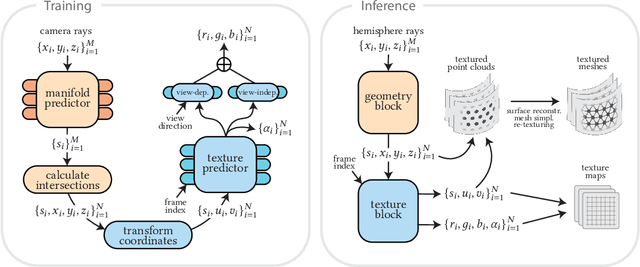
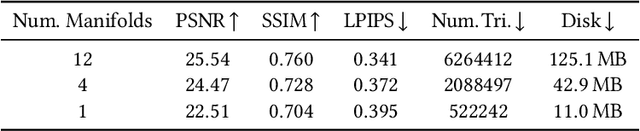
3D rendering of dynamic face captures is a challenging problem, and it demands improvements on several fronts$\unicode{x2014}$photorealism, efficiency, compatibility, and configurability. We present a novel representation that enables high-quality volumetric rendering of an actor's dynamic facial performances with minimal compute and memory footprint. It runs natively on commodity graphics soft- and hardware, and allows for a graceful trade-off between quality and efficiency. Our method utilizes recent advances in neural rendering, particularly learning discrete radiance manifolds to sparsely sample the scene to model volumetric effects. We achieve efficient modeling by learning a single set of manifolds for the entire dynamic sequence, while implicitly modeling appearance changes as temporal canonical texture. We export a single layered mesh and view-independent RGBA texture video that is compatible with legacy graphics renderers without additional ML integration. We demonstrate our method by rendering dynamic face captures of real actors in a game engine, at comparable photorealism to state-of-the-art neural rendering techniques at previously unseen frame rates.
Sandwiched Compression: Repurposing Standard Codecs with Neural Network Wrappers
Feb 08, 2024
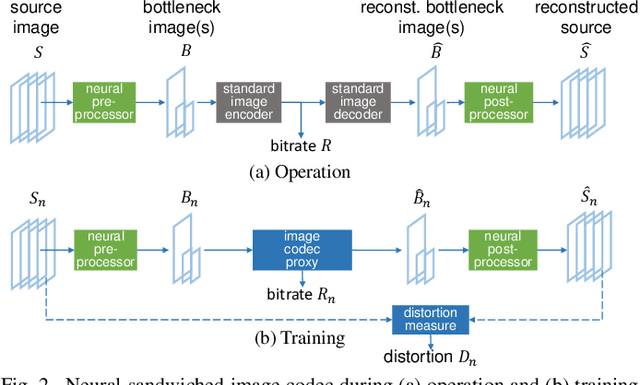
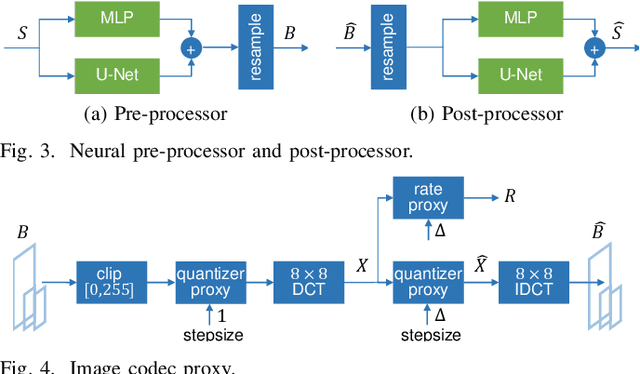
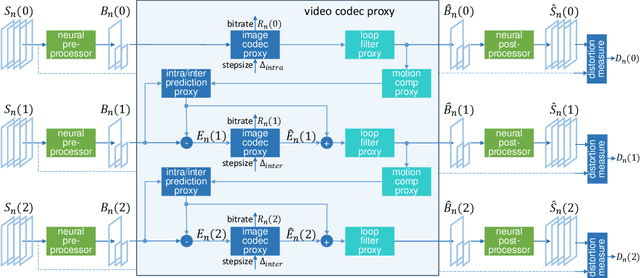
We propose sandwiching standard image and video codecs between pre- and post-processing neural networks. The networks are jointly trained through a differentiable codec proxy to minimize a given rate-distortion loss. This sandwich architecture not only improves the standard codec's performance on its intended content, it can effectively adapt the codec to other types of image/video content and to other distortion measures. Essentially, the sandwich learns to transmit ``neural code images'' that optimize overall rate-distortion performance even when the overall problem is well outside the scope of the codec's design. Through a variety of examples, we apply the sandwich architecture to sources with different numbers of channels, higher resolution, higher dynamic range, and perceptual distortion measures. The results demonstrate substantial improvements (up to 9 dB gains or up to 30\% bitrate reductions) compared to alternative adaptations. We derive VQ equivalents for the sandwich, establish optimality properties, and design differentiable codec proxies approximating current standard codecs. We further analyze model complexity, visual quality under perceptual metrics, as well as sandwich configurations that offer interesting potentials in image/video compression and streaming.
InstructPipe: Building Visual Programming Pipelines with Human Instructions
Dec 15, 2023



Visual programming provides beginner-level programmers with a coding-free experience to build their customized pipelines. Existing systems require users to build a pipeline entirely from scratch, implying that novice users need to set up and link appropriate nodes all by themselves, starting from a blank workspace. We present InstructPipe, an AI assistant that enables users to start prototyping machine learning (ML) pipelines with text instructions. We designed two LLM modules and a code interpreter to execute our solution. LLM modules generate pseudocode of a target pipeline, and the interpreter renders a pipeline in the node-graph editor for further human-AI collaboration. Technical evaluations reveal that InstructPipe reduces user interactions by 81.1% compared to traditional methods. Our user study (N=16) showed that InstructPipe empowers novice users to streamline their workflow in creating desired ML pipelines, reduce their learning curve, and spark innovative ideas with open-ended commands.