 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaDorsal: Enhancing Hand Pose Estimation with Dorsal Features in Egocentric Views
Jan 26, 2026The proliferation of XR devices has made egocentric hand pose estimation a vital task, yet this perspective is inherently challenged by frequent finger occlusions. To address this, we propose a novel approach that leverages the rich information in dorsal hand skin deformation, unlocked by recent advances in dense visual featurizers. We introduce a dual-stream delta encoder that learns pose by contrasting features from a dynamic hand with a baseline relaxed position. Our evaluation demonstrates that, using only cropped dorsal images, our method reduces the Mean Per Joint Angle Error (MPJAE) by 18% in self-occluded scenarios (fingers >= 50% occluded) compared to state-of-the-art techniques that depend on the whole hand's geometry and large model backbones. Consequently, our method not only enhances the reliability of downstream tasks like index finger pinch and tap estimation in occluded scenarios but also unlocks new interaction paradigms, such as detecting isometric force for a surface "click" without visible movement while minimizing model size.
Arm Robot: AR-Enhanced Embodied Control and Visualization for Intuitive Robot Arm Manipulation
Nov 21, 2024Embodied interaction has been introduced to human-robot interaction (HRI) as a type of teleoperation, in which users control robot arms with bodily action via handheld controllers or haptic gloves. Embodied teleoperation has made robot control intuitive to non-technical users, but differences between humans' and robots' capabilities \eg ranges of motion and response time, remain challenging. In response, we present Arm Robot, an embodied robot arm teleoperation system that helps users tackle human-robot discrepancies. Specifically, Arm Robot (1) includes AR visualization as real-time feedback on temporal and spatial discrepancies, and (2) allows users to change observing perspectives and expand action space. We conducted a user study (N=18) to investigate the usability of the Arm Robot and learn how users perceive the embodiment. Our results show users could use Arm Robot's features to effectively control the robot arm, providing insights for continued work in embodied HRI.
WheelPose: Data Synthesis Techniques to Improve Pose Estimation Performance on Wheelchair Users
Apr 25, 2024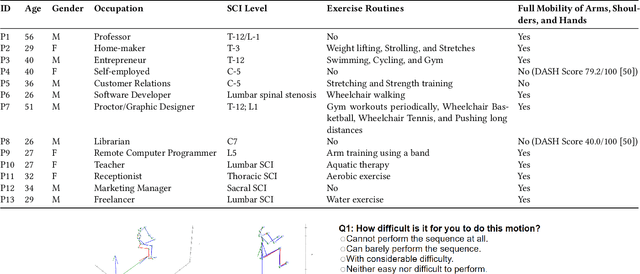

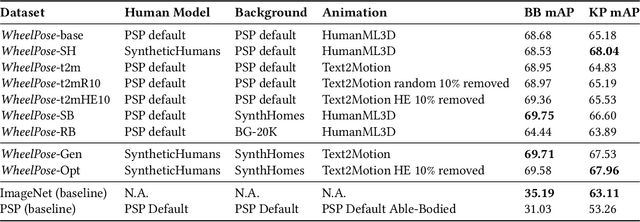

Existing pose estimation models perform poorly on wheelchair users due to a lack of representation in training data. We present a data synthesis pipeline to address this disparity in data collection and subsequently improve pose estimation performance for wheelchair users. Our configurable pipeline generates synthetic data of wheelchair users using motion capture data and motion generation outputs simulated in the Unity game engine. We validated our pipeline by conducting a human evaluation, investigating perceived realism, diversity, and an AI performance evaluation on a set of synthetic datasets from our pipeline that synthesized different backgrounds, models, and postures. We found our generated datasets were perceived as realistic by human evaluators, had more diversity than existing image datasets, and had improved person detection and pose estimation performance when fine-tuned on existing pose estimation models. Through this work, we hope to create a foothold for future efforts in tackling the inclusiveness of AI in a data-centric and human-centric manner with the data synthesis techniques demonstrated in this work. Finally, for future works to extend upon, we open source all code in this research and provide a fully configurable Unity Environment used to generate our datasets. In the case of any models we are unable to share due to redistribution and licensing policies, we provide detailed instructions on how to source and replace said models.
Quick Question: Interrupting Users for Microtasks with Reinforcement Learning
Jul 18, 2020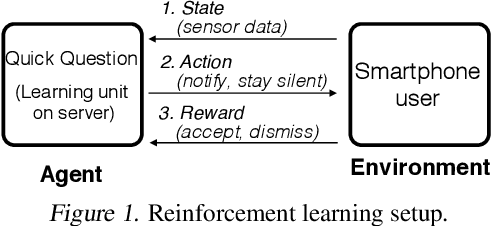
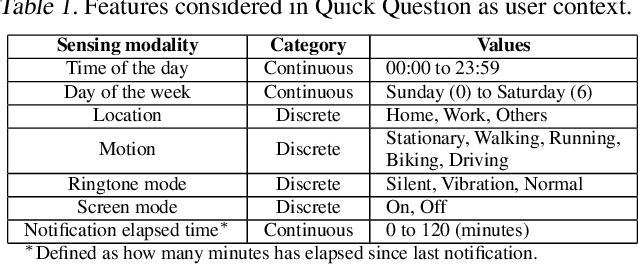
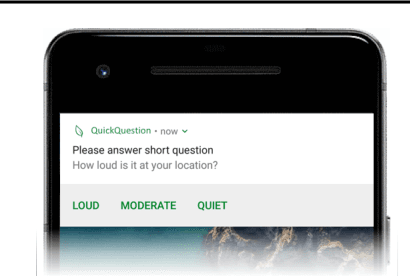

Human attention is a scarce resource in modern computing. A multitude of microtasks vie for user attention to crowdsource information, perform momentary assessments, personalize services, and execute actions with a single touch. A lot gets done when these tasks take up the invisible free moments of the day. However, an interruption at an inappropriate time degrades productivity and causes annoyance. Prior works have exploited contextual cues and behavioral data to identify interruptibility for microtasks with much success. With Quick Question, we explore use of reinforcement learning (RL) to schedule microtasks while minimizing user annoyance and compare its performance with supervised learning. We model the problem as a Markov decision process and use Advantage Actor Critic algorithm to identify interruptible moments based on context and history of user interactions. In our 5-week, 30-participant study, we compare the proposed RL algorithm against supervised learning methods. While the mean number of responses between both methods is commensurate, RL is more effective at avoiding dismissal of notifications and improves user experience over time.