 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnapshot 3D image projection using a diffractive decoder
Dec 23, 20253D image display is essential for next-generation volumetric imaging; however, dense depth multiplexing for 3D image projection remains challenging because diffraction-induced cross-talk rapidly increases as the axial image planes get closer. Here, we introduce a 3D display system comprising a digital encoder and a diffractive optical decoder, which simultaneously projects different images onto multiple target axial planes with high axial resolution. By leveraging multi-layer diffractive wavefront decoding and deep learning-based end-to-end optimization, the system achieves high-fidelity depth-resolved 3D image projection in a snapshot, enabling axial plane separations on the order of a wavelength. The digital encoder leverages a Fourier encoder network to capture multi-scale spatial and frequency-domain features from input images, integrates axial position encoding, and generates a unified phase representation that simultaneously encodes all images to be axially projected in a single snapshot through a jointly-optimized diffractive decoder. We characterized the impact of diffractive decoder depth, output diffraction efficiency, spatial light modulator resolution, and axial encoding density, revealing trade-offs that govern axial separation and 3D image projection quality. We further demonstrated the capability to display volumetric images containing 28 axial slices, as well as the ability to dynamically reconfigure the axial locations of the image planes, performed on demand. Finally, we experimentally validated the presented approach, demonstrating close agreement between the measured results and the target images. These results establish the diffractive 3D display system as a compact and scalable framework for depth-resolved snapshot 3D image projection, with potential applications in holographic displays, AR/VR interfaces, and volumetric optical computing.
Pixel Super-Resolved Fluorescence Lifetime Imaging Using Deep Learning
Dec 18, 2025



Fluorescence lifetime imaging microscopy (FLIM) is a powerful quantitative technique that provides metabolic and molecular contrast, offering strong translational potential for label-free, real-time diagnostics. However, its clinical adoption remains limited by long pixel dwell times and low signal-to-noise ratio (SNR), which impose a stricter resolution-speed trade-off than conventional optical imaging approaches. Here, we introduce FLIM_PSR_k, a deep learning-based multi-channel pixel super-resolution (PSR) framework that reconstructs high-resolution FLIM images from data acquired with up to a 5-fold increased pixel size. The model is trained using the conditional generative adversarial network (cGAN) framework, which, compared to diffusion model-based alternatives, delivers a more robust PSR reconstruction with substantially shorter inference times, a crucial advantage for practical deployment. FLIM_PSR_k not only enables faster image acquisition but can also alleviate SNR limitations in autofluorescence-based FLIM. Blind testing on held-out patient-derived tumor tissue samples demonstrates that FLIM_PSR_k reliably achieves a super-resolution factor of k = 5, resulting in a 25-fold increase in the space-bandwidth product of the output images and revealing fine architectural features lost in lower-resolution inputs, with statistically significant improvements across various image quality metrics. By increasing FLIM's effective spatial resolution, FLIM_PSR_k advances lifetime imaging toward faster, higher-resolution, and hardware-flexible implementations compatible with low-numerical-aperture and miniaturized platforms, better positioning FLIM for translational applications.
AtomWorld: A Benchmark for Evaluating Spatial Reasoning in Large Language Models on Crystalline Materials
Oct 06, 2025

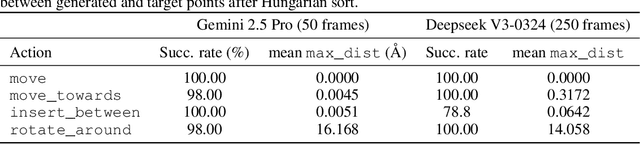
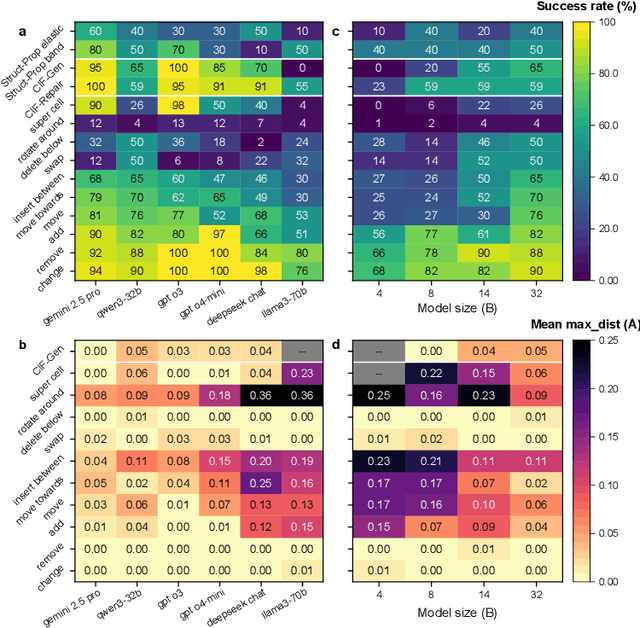
Large Language Models (LLMs) excel at textual reasoning and are beginning to develop spatial understanding, prompting the question of whether these abilities can be combined for complex, domain-specific tasks. This question is essential in fields like materials science, where deep understanding of 3D atomic structures is fundamental. While initial studies have successfully applied LLMs to tasks involving pure crystal generation or coordinate understandings, a standardized benchmark to systematically evaluate their core reasoning abilities across diverse atomic structures has been notably absent. To address this gap, we introduce the AtomWorld benchmark to evaluate LLMs on tasks based in Crystallographic Information Files (CIFs), a standard structure representation format. These tasks, including structural editing, CIF perception, and property-guided modeling, reveal a critical limitation: current models, despite establishing promising baselines, consistently fail in structural understanding and spatial reasoning. Our experiments show that these models make frequent errors on structure modification tasks, and even in the basic CIF format understandings, potentially leading to cumulative errors in subsequent analysis and materials insights. By defining these standardized tasks, AtomWorld lays the ground for advancing LLMs toward robust atomic-scale modeling, crucial for accelerating materials research and automating scientific workflows.
Llama-3.1-FoundationAI-SecurityLLM-Base-8B Technical Report
Apr 28, 2025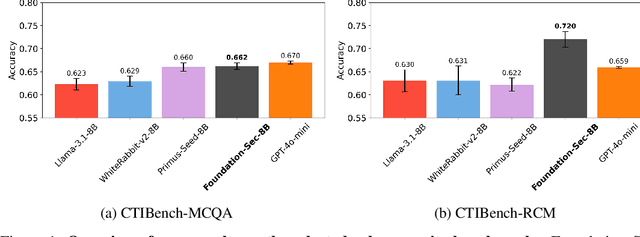
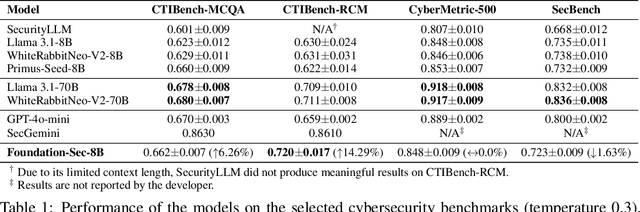

As transformer-based large language models (LLMs) increasingly permeate society, they have revolutionized domains such as software engineering, creative writing, and digital arts. However, their adoption in cybersecurity remains limited due to challenges like scarcity of specialized training data and complexity of representing cybersecurity-specific knowledge. To address these gaps, we present Foundation-Sec-8B, a cybersecurity-focused LLM built on the Llama 3.1 architecture and enhanced through continued pretraining on a carefully curated cybersecurity corpus. We evaluate Foundation-Sec-8B across both established and new cybersecurity benchmarks, showing that it matches Llama 3.1-70B and GPT-4o-mini in certain cybersecurity-specific tasks. By releasing our model to the public, we aim to accelerate progress and adoption of AI-driven tools in both public and private cybersecurity contexts.
Arm Robot: AR-Enhanced Embodied Control and Visualization for Intuitive Robot Arm Manipulation
Nov 21, 2024Embodied interaction has been introduced to human-robot interaction (HRI) as a type of teleoperation, in which users control robot arms with bodily action via handheld controllers or haptic gloves. Embodied teleoperation has made robot control intuitive to non-technical users, but differences between humans' and robots' capabilities \eg ranges of motion and response time, remain challenging. In response, we present Arm Robot, an embodied robot arm teleoperation system that helps users tackle human-robot discrepancies. Specifically, Arm Robot (1) includes AR visualization as real-time feedback on temporal and spatial discrepancies, and (2) allows users to change observing perspectives and expand action space. We conducted a user study (N=18) to investigate the usability of the Arm Robot and learn how users perceive the embodiment. Our results show users could use Arm Robot's features to effectively control the robot arm, providing insights for continued work in embodied HRI.
TeMPO: Efficient Time-Multiplexed Dynamic Photonic Tensor Core for Edge AI with Compact Slow-Light Electro-Optic Modulator
Feb 12, 2024Electronic-photonic computing systems offer immense potential in energy-efficient artificial intelligence (AI) acceleration tasks due to the superior computing speed and efficiency of optics, especially for real-time, low-energy deep neural network (DNN) inference tasks on resource-restricted edge platforms. However, current optical neural accelerators based on foundry-available devices and conventional system architecture still encounter a performance gap compared to highly customized electronic counterparts. To bridge the performance gap due to lack of domain specialization, we present a time-multiplexed dynamic photonic tensor accelerator, dubbed TeMPO, with cross-layer device/circuit/architecture customization. At the device level, we present foundry-compatible, customized photonic devices, including a slow-light electro-optic modulator with experimental demonstration, optical splitters, and phase shifters that significantly reduce the footprint and power in input encoding and dot-product calculation. At the circuit level, partial products are hierarchically accumulated via parallel photocurrent aggregation, lightweight capacitive temporal integration, and sequential digital summation, considerably relieving the analog-to-digital conversion bottleneck. We also employ a multi-tile, multi-core architecture to maximize hardware sharing for higher efficiency. Across diverse edge AI workloads, TeMPO delivers digital-comparable task accuracy with superior quantization/noise tolerance. We achieve a 368.6 TOPS peak performance, 22.3 TOPS/W energy efficiency, and 1.2 TOPS/mm$^2$ compute density, pushing the Pareto frontier in edge AI hardware. This work signifies the power of cross-layer co-design and domain-specific customization, paving the way for future electronic-photonic accelerators with even greater performance and efficiency.