 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaDorsal: Enhancing Hand Pose Estimation with Dorsal Features in Egocentric Views
Jan 26, 2026The proliferation of XR devices has made egocentric hand pose estimation a vital task, yet this perspective is inherently challenged by frequent finger occlusions. To address this, we propose a novel approach that leverages the rich information in dorsal hand skin deformation, unlocked by recent advances in dense visual featurizers. We introduce a dual-stream delta encoder that learns pose by contrasting features from a dynamic hand with a baseline relaxed position. Our evaluation demonstrates that, using only cropped dorsal images, our method reduces the Mean Per Joint Angle Error (MPJAE) by 18% in self-occluded scenarios (fingers >= 50% occluded) compared to state-of-the-art techniques that depend on the whole hand's geometry and large model backbones. Consequently, our method not only enhances the reliability of downstream tasks like index finger pinch and tap estimation in occluded scenarios but also unlocks new interaction paradigms, such as detecting isometric force for a surface "click" without visible movement while minimizing model size.
Window Size Versus Accuracy Experiments in Voice Activity Detectors
Jan 24, 2026Voice activity detection (VAD) plays a vital role in enabling applications such as speech recognition. We analyze the impact of window size on the accuracy of three VAD algorithms: Silero, WebRTC, and Root Mean Square (RMS) across a set of diverse real-world digital audio streams. We additionally explore the use of hysteresis on top of each VAD output. Our results offer practical references for optimizing VAD systems. Silero significantly outperforms WebRTC and RMS, and hysteresis provides a benefit for WebRTC.
Constrained Diffusion with Trust Sampling
Nov 17, 2024



Diffusion models have demonstrated significant promise in various generative tasks; however, they often struggle to satisfy challenging constraints. Our approach addresses this limitation by rethinking training-free loss-guided diffusion from an optimization perspective. We formulate a series of constrained optimizations throughout the inference process of a diffusion model. In each optimization, we allow the sample to take multiple steps along the gradient of the proxy constraint function until we can no longer trust the proxy, according to the variance at each diffusion level. Additionally, we estimate the state manifold of diffusion model to allow for early termination when the sample starts to wander away from the state manifold at each diffusion step. Trust sampling effectively balances between following the unconditional diffusion model and adhering to the loss guidance, enabling more flexible and accurate constrained generation. We demonstrate the efficacy of our method through extensive experiments on complex tasks, and in drastically different domains of images and 3D motion generation, showing significant improvements over existing methods in terms of generation quality. Our implementation is available at https://github.com/will-s-h/trust-sampling.
WheelPose: Data Synthesis Techniques to Improve Pose Estimation Performance on Wheelchair Users
Apr 25, 2024Existing pose estimation models perform poorly on wheelchair users due to a lack of representation in training data. We present a data synthesis pipeline to address this disparity in data collection and subsequently improve pose estimation performance for wheelchair users. Our configurable pipeline generates synthetic data of wheelchair users using motion capture data and motion generation outputs simulated in the Unity game engine. We validated our pipeline by conducting a human evaluation, investigating perceived realism, diversity, and an AI performance evaluation on a set of synthetic datasets from our pipeline that synthesized different backgrounds, models, and postures. We found our generated datasets were perceived as realistic by human evaluators, had more diversity than existing image datasets, and had improved person detection and pose estimation performance when fine-tuned on existing pose estimation models. Through this work, we hope to create a foothold for future efforts in tackling the inclusiveness of AI in a data-centric and human-centric manner with the data synthesis techniques demonstrated in this work. Finally, for future works to extend upon, we open source all code in this research and provide a fully configurable Unity Environment used to generate our datasets. In the case of any models we are unable to share due to redistribution and licensing policies, we provide detailed instructions on how to source and replace said models.
Adversarially Constructed Evaluation Sets Are More Challenging, but May Not Be Fair
Nov 16, 2021


More capable language models increasingly saturate existing task benchmarks, in some cases outperforming humans. This has left little headroom with which to measure further progress. Adversarial dataset creation has been proposed as a strategy to construct more challenging datasets, and two common approaches are: (1) filtering out easy examples and (2) model-in-the-loop data collection. In this work, we study the impact of applying each approach to create more challenging evaluation datasets. We adapt the AFLite algorithm to filter evaluation data, and run experiments against 18 different adversary models. We find that AFLite indeed selects more challenging examples, lowering the performance of evaluated models more as stronger adversary models are used. However, the resulting ranking of models can also be unstable and highly sensitive to the choice of adversary model used. Moreover, AFLite oversamples examples with low annotator agreement, meaning that model comparisons hinge on the most contentiously labeled examples. Smaller-scale experiments on the adversarially collected datasets ANLI and AdversarialQA show similar findings, broadly lowering performance with stronger adversaries while disproportionately affecting the adversary model.
Types of Out-of-Distribution Texts and How to Detect Them
Sep 14, 2021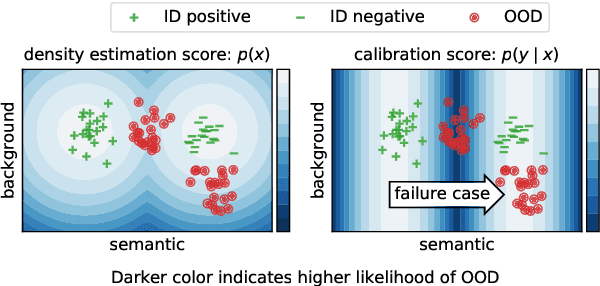
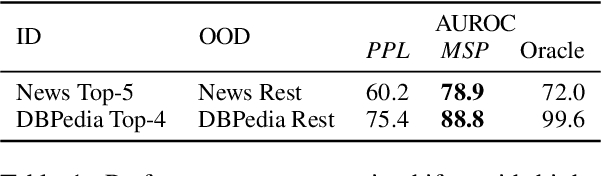
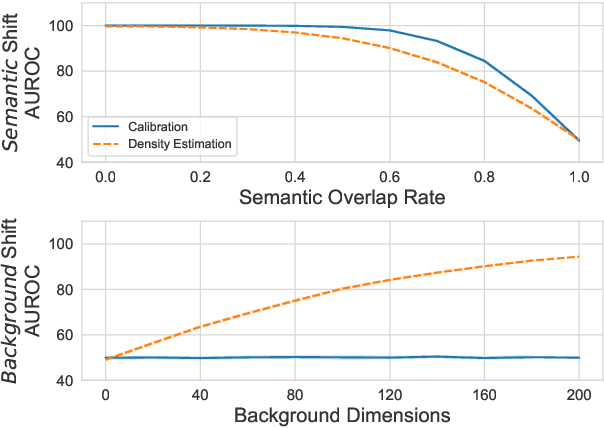
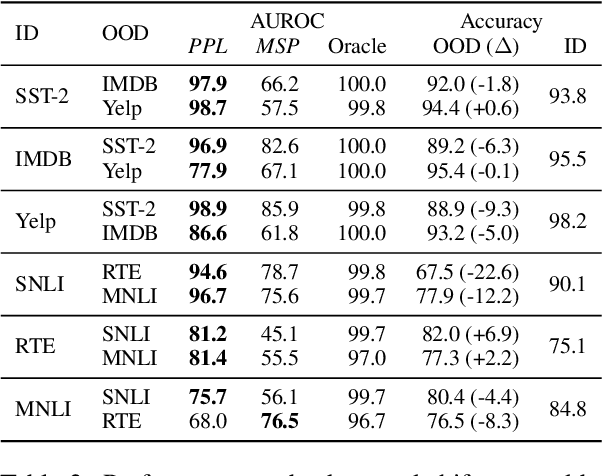
Despite agreement on the importance of detecting out-of-distribution (OOD) examples, there is little consensus on the formal definition of OOD examples and how to best detect them. We categorize these examples by whether they exhibit a background shift or a semantic shift, and find that the two major approaches to OOD detection, model calibration and density estimation (language modeling for text), have distinct behavior on these types of OOD data. Across 14 pairs of in-distribution and OOD English natural language understanding datasets, we find that density estimation methods consistently beat calibration methods in background shift settings, while performing worse in semantic shift settings. In addition, we find that both methods generally fail to detect examples from challenge data, highlighting a weak spot for current methods. Since no single method works well across all settings, our results call for an explicit definition of OOD examples when evaluating different detection methods.
Comparing Test Sets with Item Response Theory
Jun 01, 2021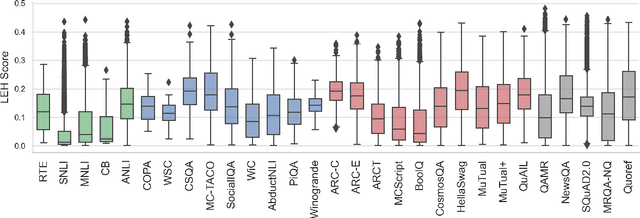
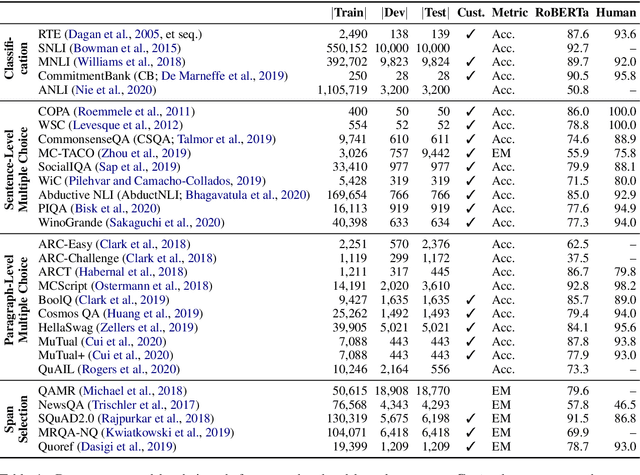
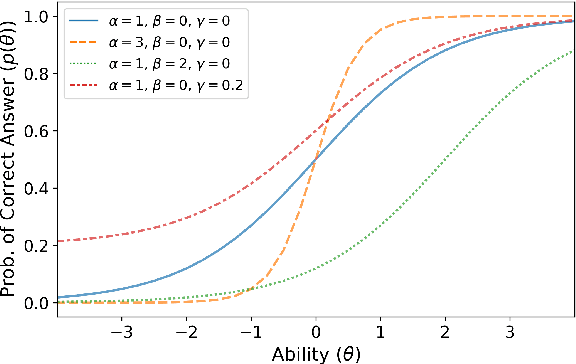

Recent years have seen numerous NLP datasets introduced to evaluate the performance of fine-tuned models on natural language understanding tasks. Recent results from large pretrained models, though, show that many of these datasets are largely saturated and unlikely to be able to detect further progress. What kind of datasets are still effective at discriminating among strong models, and what kind of datasets should we expect to be able to detect future improvements? To measure this uniformly across datasets, we draw on Item Response Theory and evaluate 29 datasets using predictions from 18 pretrained Transformer models on individual test examples. We find that Quoref, HellaSwag, and MC-TACO are best suited for distinguishing among state-of-the-art models, while SNLI, MNLI, and CommitmentBank seem to be saturated for current strong models. We also observe span selection task format, which is used for QA datasets like QAMR or SQuAD2.0, is effective in differentiating between strong and weak models.
Does Putting a Linguist in the Loop Improve NLU Data Collection?
Apr 15, 2021
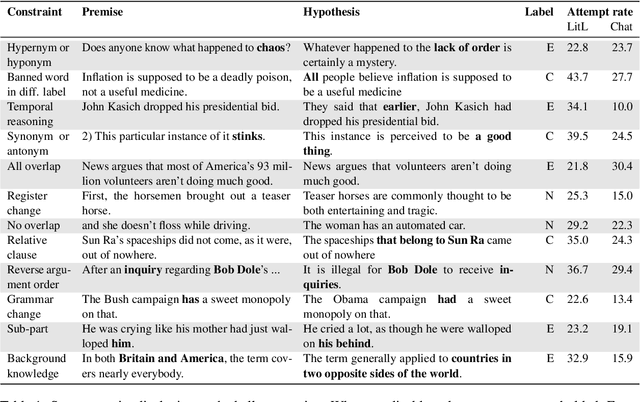

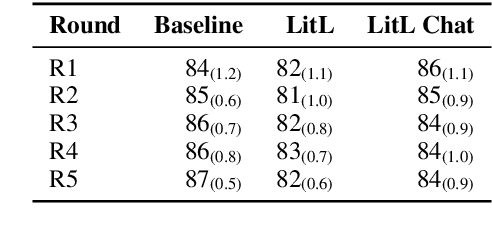
Many crowdsourced NLP datasets contain systematic gaps and biases that are identified only after data collection is complete. Identifying these issues from early data samples during crowdsourcing should make mitigation more efficient, especially when done iteratively. We take natural language inference as a test case and ask whether it is beneficial to put a linguist `in the loop' during data collection to dynamically identify and address gaps in the data by introducing novel constraints on the task. We directly compare three data collection protocols: (i) a baseline protocol, (ii) a linguist-in-the-loop intervention with iteratively-updated constraints on the task, and (iii) an extension of linguist-in-the-loop that provides direct interaction between linguists and crowdworkers via a chatroom. The datasets collected with linguist involvement are more reliably challenging than baseline, without loss of quality. But we see no evidence that using this data in training leads to better out-of-domain model performance, and the addition of a chat platform has no measurable effect on the resulting dataset. We suggest integrating expert analysis \textit{during} data collection so that the expert can dynamically address gaps and biases in the dataset.
Counterfactually-Augmented SNLI Training Data Does Not Yield Better Generalization Than Unaugmented Data
Oct 09, 2020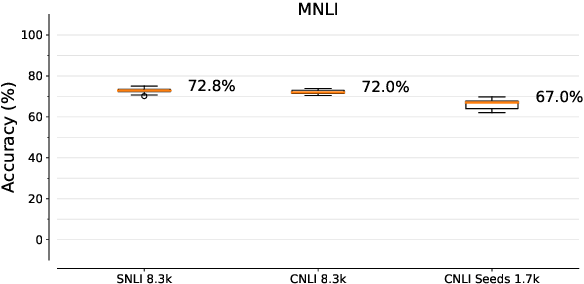


A growing body of work shows that models exploit annotation artifacts to achieve state-of-the-art performance on standard crowdsourced benchmarks---datasets collected from crowdworkers to create an evaluation task---while still failing on out-of-domain examples for the same task. Recent work has explored the use of counterfactually-augmented data---data built by minimally editing a set of seed examples to yield counterfactual labels---to augment training data associated with these benchmarks and build more robust classifiers that generalize better. However, Khashabi et al. (2020) find that this type of augmentation yields little benefit on reading comprehension tasks when controlling for dataset size and cost of collection. We build upon this work by using English natural language inference data to test model generalization and robustness and find that models trained on a counterfactually-augmented SNLI dataset do not generalize better than unaugmented datasets of similar size and that counterfactual augmentation can hurt performance, yielding models that are less robust to challenge examples. Counterfactual augmentation of natural language understanding data through standard crowdsourcing techniques does not appear to be an effective way of collecting training data and further innovation is required to make this general line of work viable.
Precise Task Formalization Matters in Winograd Schema Evaluations
Oct 08, 2020

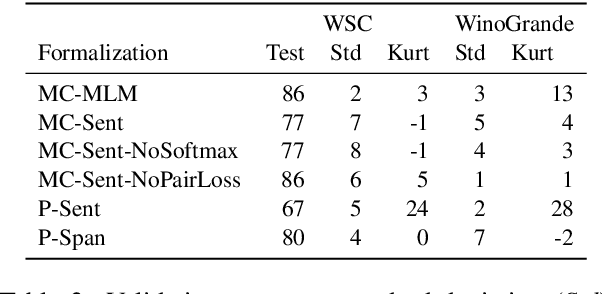
Performance on the Winograd Schema Challenge (WSC), a respected English commonsense reasoning benchmark, recently rocketed from chance accuracy to 89% on the SuperGLUE leaderboard, with relatively little corroborating evidence of a correspondingly large improvement in reasoning ability. We hypothesize that much of this improvement comes from recent changes in task formalization---the combination of input specification, loss function, and reuse of pretrained parameters---by users of the dataset, rather than improvements in the pretrained model's reasoning ability. We perform an ablation on two Winograd Schema datasets that interpolates between the formalizations used before and after this surge, and find (i) framing the task as multiple choice improves performance by 2-6 points and (ii) several additional techniques, including the reuse of a pretrained language modeling head, can mitigate the model's extreme sensitivity to hyperparameters. We urge future benchmark creators to impose additional structure to minimize the impact of formalization decisions on reported results.