 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Task Formalization Matters in Winograd Schema Evaluations
Oct 08, 2020

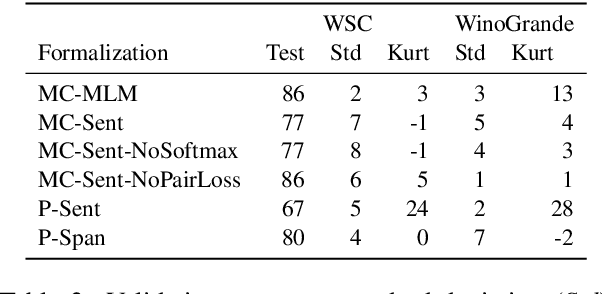
Performance on the Winograd Schema Challenge (WSC), a respected English commonsense reasoning benchmark, recently rocketed from chance accuracy to 89% on the SuperGLUE leaderboard, with relatively little corroborating evidence of a correspondingly large improvement in reasoning ability. We hypothesize that much of this improvement comes from recent changes in task formalization---the combination of input specification, loss function, and reuse of pretrained parameters---by users of the dataset, rather than improvements in the pretrained model's reasoning ability. We perform an ablation on two Winograd Schema datasets that interpolates between the formalizations used before and after this surge, and find (i) framing the task as multiple choice improves performance by 2-6 points and (ii) several additional techniques, including the reuse of a pretrained language modeling head, can mitigate the model's extreme sensitivity to hyperparameters. We urge future benchmark creators to impose additional structure to minimize the impact of formalization decisions on reported results.