 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuick Question: Interrupting Users for Microtasks with Reinforcement Learning
Jul 18, 2020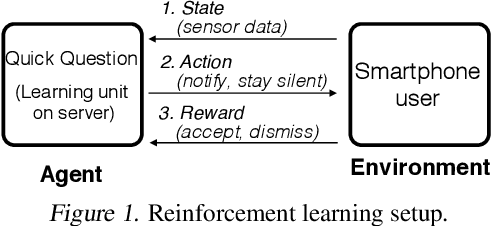
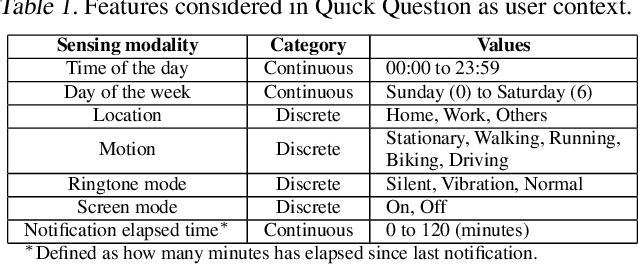
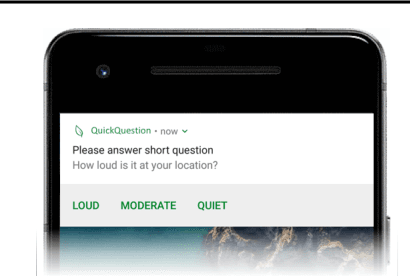

Human attention is a scarce resource in modern computing. A multitude of microtasks vie for user attention to crowdsource information, perform momentary assessments, personalize services, and execute actions with a single touch. A lot gets done when these tasks take up the invisible free moments of the day. However, an interruption at an inappropriate time degrades productivity and causes annoyance. Prior works have exploited contextual cues and behavioral data to identify interruptibility for microtasks with much success. With Quick Question, we explore use of reinforcement learning (RL) to schedule microtasks while minimizing user annoyance and compare its performance with supervised learning. We model the problem as a Markov decision process and use Advantage Actor Critic algorithm to identify interruptible moments based on context and history of user interactions. In our 5-week, 30-participant study, we compare the proposed RL algorithm against supervised learning methods. While the mean number of responses between both methods is commensurate, RL is more effective at avoiding dismissal of notifications and improves user experience over time.
Generating Natural Language Adversarial Examples
Sep 24, 2018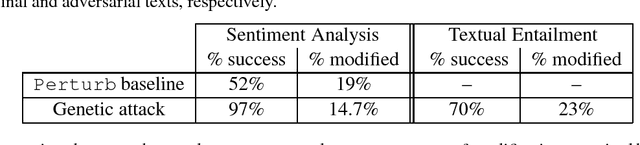
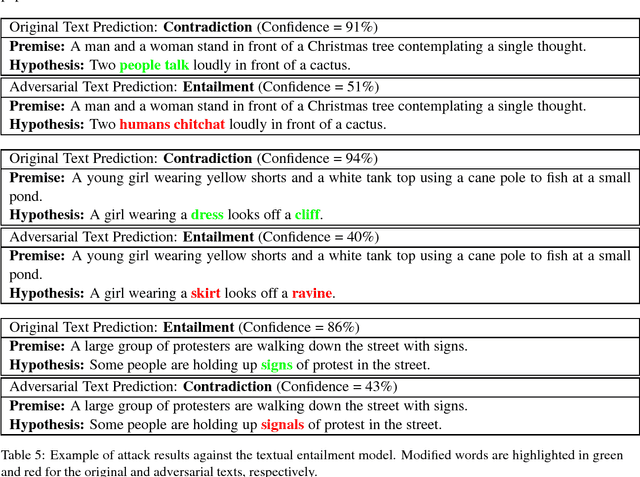
Deep neural networks (DNNs) are vulnerable to adversarial examples, perturbations to correctly classified examples which can cause the model to misclassify. In the image domain, these perturbations are often virtually indistinguishable to human perception, causing humans and state-of-the-art models to disagree. However, in the natural language domain, small perturbations are clearly perceptible, and the replacement of a single word can drastically alter the semantics of the document. Given these challenges, we use a black-box population-based optimization algorithm to generate semantically and syntactically similar adversarial examples that fool well-trained sentiment analysis and textual entailment models with success rates of 97% and 70%, respectively. We additionally demonstrate that 92.3% of the successful sentiment analysis adversarial examples are classified to their original label by 20 human annotators, and that the examples are perceptibly quite similar. Finally, we discuss an attempt to use adversarial training as a defense, but fail to yield improvement, demonstrating the strength and diversity of our adversarial examples. We hope our findings encourage researchers to pursue improving the robustness of DNNs in the natural language domain.