 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation
May 03, 2024Traditional recommender systems such as matrix factorization methods rely on learning a shared dense embedding space to represent both items and user preferences. Sequence models such as RNN, GRUs, and, recently, Transformers have also excelled in the task of sequential recommendation. This task requires understanding the sequential structure present in users' historical interactions to predict the next item they may like. Building upon the success of Large Language Models (LLMs) in a variety of tasks, researchers have recently explored using LLMs that are pretrained on vast corpora of text for sequential recommendation. To use LLMs in sequential recommendations, both the history of user interactions and the model's prediction of the next item are expressed in text form. We propose CALRec, a two-stage LLM finetuning framework that finetunes a pretrained LLM in a two-tower fashion using a mixture of two contrastive losses and a language modeling loss: the LLM is first finetuned on a data mixture from multiple domains followed by another round of target domain finetuning. Our model significantly outperforms many state-of-the-art baselines (+37% in Recall@1 and +24% in NDCG@10) and systematic ablation studies reveal that (i) both stages of finetuning are crucial, and, when combined, we achieve improved performance, and (ii) contrastive alignment is effective among the target domains explored in our experiments.
PhysioGAN: Training High Fidelity Generative Model for Physiological Sensor Readings
Apr 25, 2022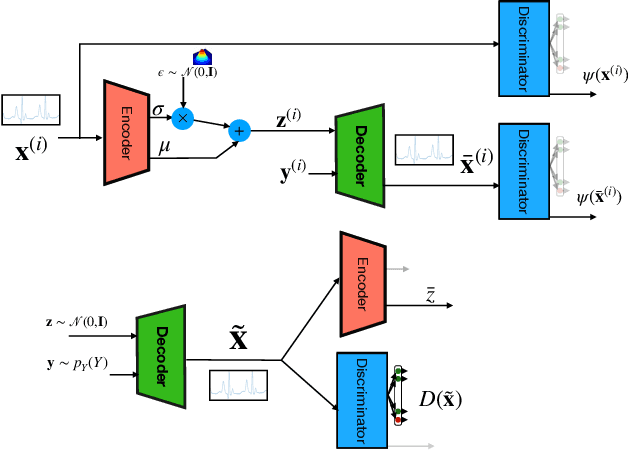
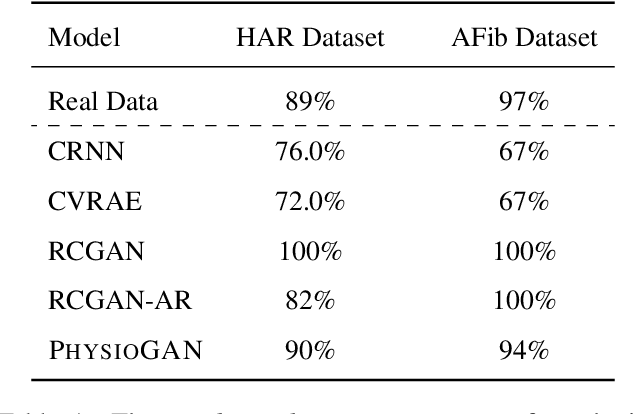
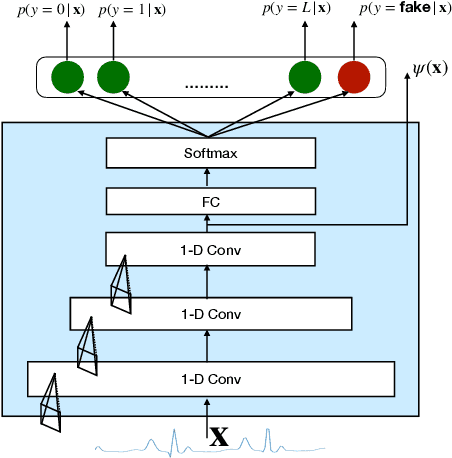
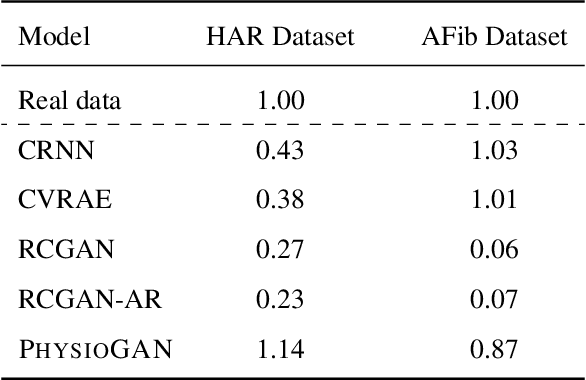
Generative models such as the variational autoencoder (VAE) and the generative adversarial networks (GAN) have proven to be incredibly powerful for the generation of synthetic data that preserves statistical properties and utility of real-world datasets, especially in the context of image and natural language text. Nevertheless, until now, there has no successful demonstration of how to apply either method for generating useful physiological sensory data. The state-of-the-art techniques in this context have achieved only limited success. We present PHYSIOGAN, a generative model to produce high fidelity synthetic physiological sensor data readings. PHYSIOGAN consists of an encoder, decoder, and a discriminator. We evaluate PHYSIOGAN against the state-of-the-art techniques using two different real-world datasets: ECG classification and activity recognition from motion sensors datasets. We compare PHYSIOGAN to the baseline models not only the accuracy of class conditional generation but also the sample diversity and sample novelty of the synthetic datasets. We prove that PHYSIOGAN generates samples with higher utility than other generative models by showing that classification models trained on only synthetic data generated by PHYSIOGAN have only 10% and 20% decrease in their classification accuracy relative to classification models trained on the real data. Furthermore, we demonstrate the use of PHYSIOGAN for sensor data imputation in creating plausible results.
Mondegreen: A Post-Processing Solution to Speech Recognition Error Correction for Voice Search Queries
May 20, 2021
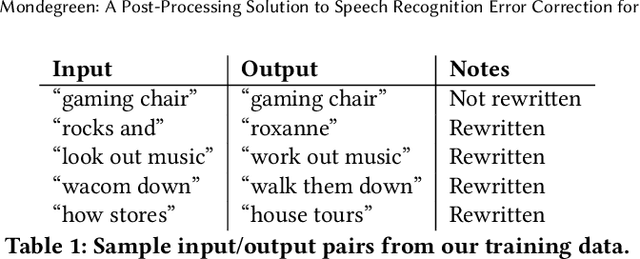


As more and more online search queries come from voice, automatic speech recognition becomes a key component to deliver relevant search results. Errors introduced by automatic speech recognition (ASR) lead to irrelevant search results returned to the user, thus causing user dissatisfaction. In this paper, we introduce an approach, Mondegreen, to correct voice queries in text space without depending on audio signals, which may not always be available due to system constraints or privacy or bandwidth (for example, some ASR systems run on-device) considerations. We focus on voice queries transcribed via several proprietary commercial ASR systems. These queries come from users making internet, or online service search queries. We first present an analysis showing how different the language distribution coming from user voice queries is from that in traditional text corpora used to train off-the-shelf ASR systems. We then demonstrate that Mondegreen can achieve significant improvements in increased user interaction by correcting user voice queries in one of the largest search systems in Google. Finally, we see Mondegreen as complementing existing highly-optimized production ASR systems, which may not be frequently retrained and thus lag behind due to vocabulary drifts.
NeuronInspect: Detecting Backdoors in Neural Networks via Output Explanations
Nov 18, 2019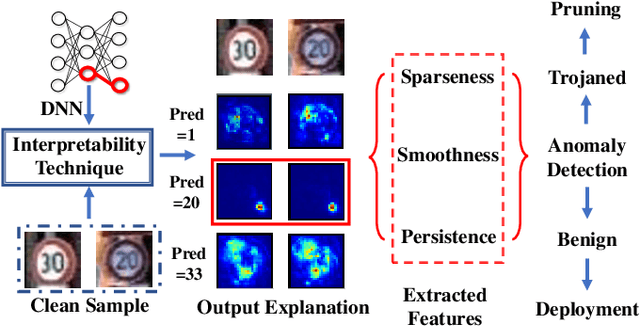
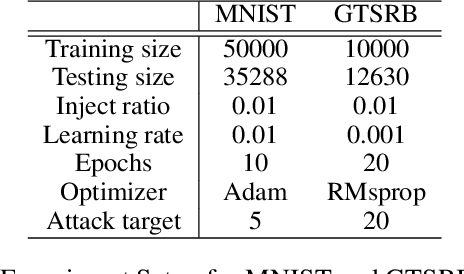
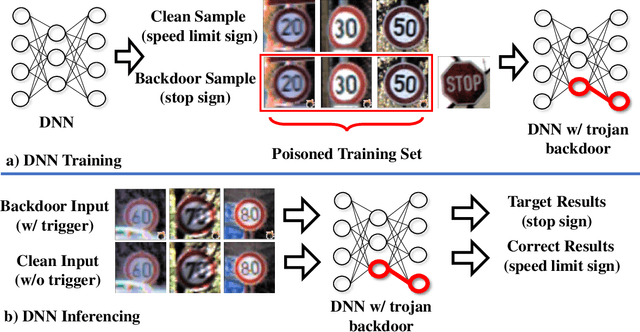
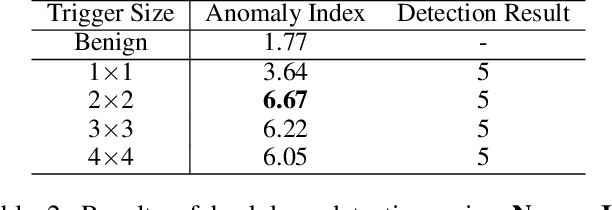
Deep neural networks have achieved state-of-the-art performance on various tasks. However, lack of interpretability and transparency makes it easier for malicious attackers to inject trojan backdoor into the neural networks, which will make the model behave abnormally when a backdoor sample with a specific trigger is input. In this paper, we propose NeuronInspect, a framework to detect trojan backdoors in deep neural networks via output explanation techniques. NeuronInspect first identifies the existence of backdoor attack targets by generating the explanation heatmap of the output layer. We observe that generated heatmaps from clean and backdoored models have different characteristics. Therefore we extract features that measure the attributes of explanations from an attacked model namely: sparse, smooth and persistent. We combine these features and use outlier detection to figure out the outliers, which is the set of attack targets. We demonstrate the effectiveness and efficiency of NeuronInspect on MNIST digit recognition dataset and GTSRB traffic sign recognition dataset. We extensively evaluate NeuronInspect on different attack scenarios and prove better robustness and effectiveness over state-of-the-art trojan backdoor detection techniques Neural Cleanse by a great margin.
NeuroMask: Explaining Predictions of Deep Neural Networks through Mask Learning
Aug 05, 2019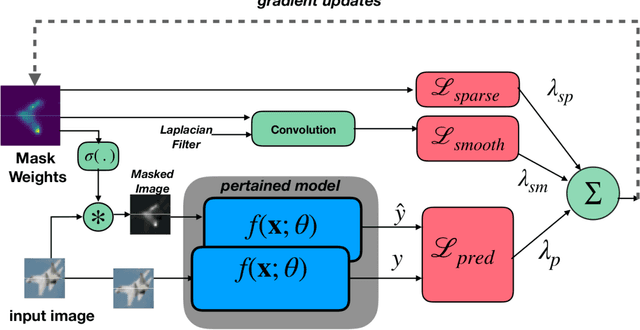



Deep Neural Networks (DNNs) deliver state-of-the-art performance in many image recognition and understanding applications. However, despite their outstanding performance, these models are black-boxes and it is hard to understand how they make their decisions. Over the past few years, researchers have studied the problem of providing explanations of why DNNs predicted their results. However, existing techniques are either obtrusive, requiring changes in model training, or suffer from low output quality. In this paper, we present a novel method, NeuroMask, for generating an interpretable explanation of classification model results. When applied to image classification models, NeuroMask identifies the image parts that are most important to classifier results by applying a mask that hides/reveals different parts of the image, before feeding it back into the model. The mask values are tuned by minimizing a properly designed cost function that preserves the classification result and encourages producing an interpretable mask. Experiments using state-of-the-art Convolutional Neural Networks for image recognition on different datasets (CIFAR-10 and ImageNet) show that NeuroMask successfully localizes the parts of the input image which are most relevant to the DNN decision. By showing a visual quality comparison between NeuroMask explanations and those of other methods, we find NeuroMask to be both accurate and interpretable.
Deep Residual Neural Networks for Audio Spoofing Detection
Jun 30, 2019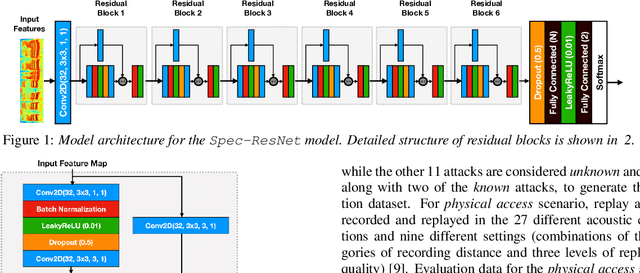
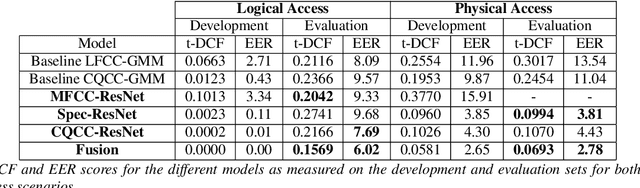
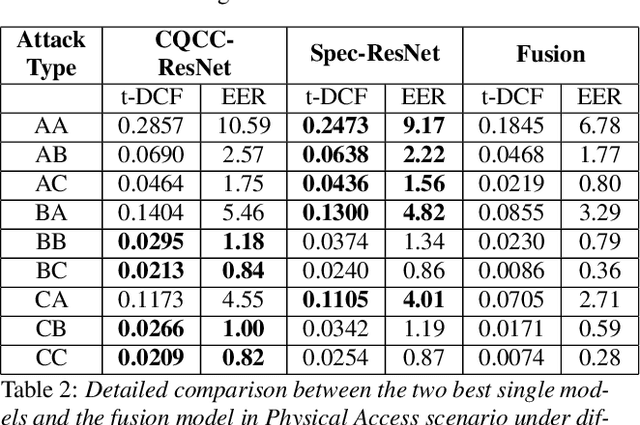
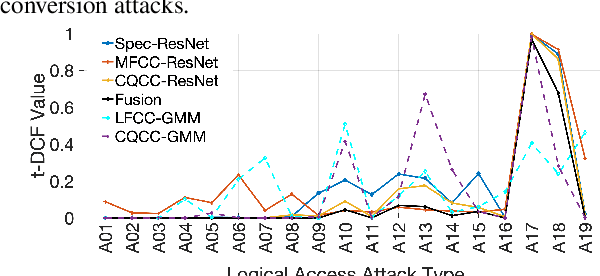
The state-of-art models for speech synthesis and voice conversion are capable of generating synthetic speech that is perceptually indistinguishable from bonafide human speech. These methods represent a threat to the automatic speaker verification (ASV) systems. Additionally, replay attacks where the attacker uses a speaker to replay a previously recorded genuine human speech are also possible. We present our solution for the ASVSpoof2019 competition, which aims to develop countermeasure systems that distinguish between spoofing attacks and genuine speeches. Our model is inspired by the success of residual convolutional networks in many classification tasks. We build three variants of a residual convolutional neural network that accept different feature representations (MFCC, Log-magnitude STFT, and CQCC) of input. We compare the performance achieved by our model variants and the competition baseline models. In the logical access scenario, the fusion of our models has zero t-DCF cost and zero equal error rate (EER), as evaluated on the development set. On the evaluation set, our model fusion improves the t-DCF and EER by 25% compared to the baseline algorithms. Against physical access replay attacks, our model fusion improves the baseline algorithms t-DCF and EER scores by 71% and 75% on the evaluation set, respectively.
CAAD 2018: Generating Transferable Adversarial Examples
Sep 29, 2018
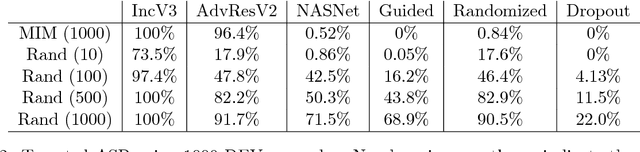

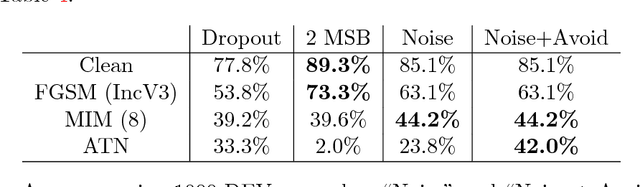
Deep neural networks (DNNs) are vulnerable to adversarial examples, perturbations carefully crafted to fool the targeted DNN, in both the non-targeted and targeted case. In the non-targeted case, the attacker simply aims to induce misclassification. In the targeted case, the attacker aims to induce classification to a specified target class. In addition, it has been observed that strong adversarial examples can transfer to unknown models, yielding a serious security concern. The NIPS 2017 competition was organized to accelerate research in adversarial attacks and defenses, taking place in the realistic setting where submitted adversarial attacks attempt to transfer to submitted defenses. The CAAD 2018 competition took place with nearly identical rules to the NIPS 2017 one. Given the requirement that the NIPS 2017 submissions were to be open-sourced, participants in the CAAD 2018 competition were able to directly build upon previous solutions, and thus improve the state-of-the-art in this setting. Our team participated in the CAAD 2018 competition, and won 1st place in both attack subtracks, non-targeted and targeted adversarial attacks, and 3rd place in defense. We outline our solutions and development results in this article. We hope our results can inform researchers in both generating and defending against adversarial examples.
Generating Natural Language Adversarial Examples
Sep 24, 2018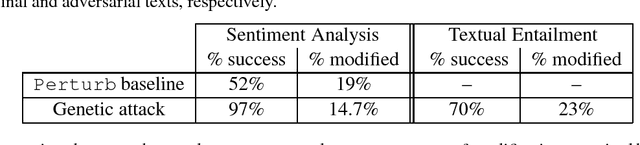
Deep neural networks (DNNs) are vulnerable to adversarial examples, perturbations to correctly classified examples which can cause the model to misclassify. In the image domain, these perturbations are often virtually indistinguishable to human perception, causing humans and state-of-the-art models to disagree. However, in the natural language domain, small perturbations are clearly perceptible, and the replacement of a single word can drastically alter the semantics of the document. Given these challenges, we use a black-box population-based optimization algorithm to generate semantically and syntactically similar adversarial examples that fool well-trained sentiment analysis and textual entailment models with success rates of 97% and 70%, respectively. We additionally demonstrate that 92.3% of the successful sentiment analysis adversarial examples are classified to their original label by 20 human annotators, and that the examples are perceptibly quite similar. Finally, we discuss an attempt to use adversarial training as a defense, but fail to yield improvement, demonstrating the strength and diversity of our adversarial examples. We hope our findings encourage researchers to pursue improving the robustness of DNNs in the natural language domain.
GenAttack: Practical Black-box Attacks with Gradient-Free Optimization
May 28, 2018



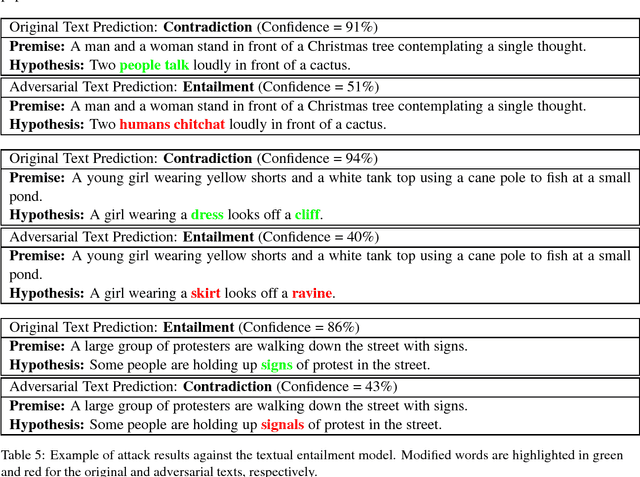
Deep neural networks (DNNs) are vulnerable to adversarial examples, even in the black-box case, where the attacker is limited to solely query access. Existing blackbox approaches to generating adversarial examples typically require a significant amount of queries, either for training a substitute network or estimating gradients from the output scores. We introduce GenAttack, a gradient-free optimization technique which uses genetic algorithms for synthesizing adversarial examples in the black-box setting. Our experiments on the MNIST, CIFAR-10, and ImageNet datasets show that GenAttack can successfully generate visually imperceptible adversarial examples against state-of-the-art image recognition models with orders of magnitude fewer queries than existing approaches. For example, in our CIFAR-10 experiments, GenAttack required roughly 2,568 times less queries than the current state-of-the-art black-box attack. Furthermore, we show that GenAttack can successfully attack both the state-of-the-art ImageNet defense, ensemble adversarial training, and non-differentiable, randomized input transformation defenses. GenAttack's success against ensemble adversarial training demonstrates that its query efficiency enables it to exploit the defense's weakness to direct black-box attacks. GenAttack's success against non-differentiable input transformations indicates that its gradient-free nature enables it to be applicable against defenses which perform gradient masking/obfuscation to confuse the attacker. Our results suggest that population-based optimization opens up a promising area of research into effective gradient-free black-box attacks.
Did you hear that? Adversarial Examples Against Automatic Speech Recognition
Jan 02, 2018
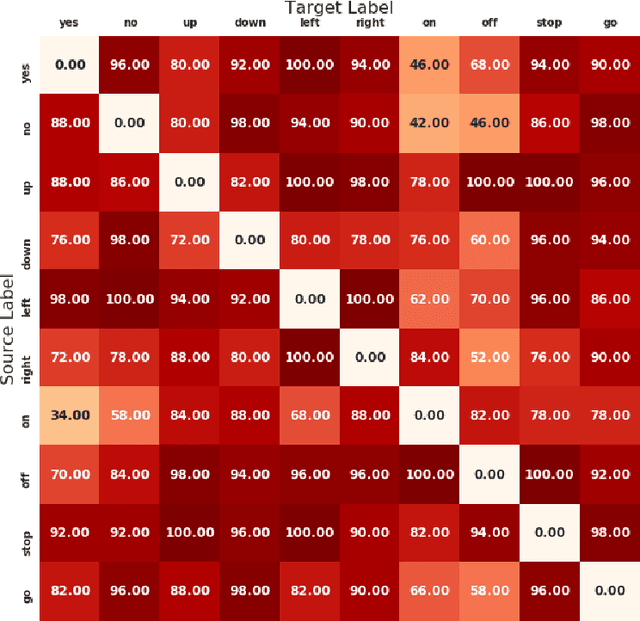
Speech is a common and effective way of communication between humans, and modern consumer devices such as smartphones and home hubs are equipped with deep learning based accurate automatic speech recognition to enable natural interaction between humans and machines. Recently, researchers have demonstrated powerful attacks against machine learning models that can fool them to produceincorrect results. However, nearly all previous research in adversarial attacks has focused on image recognition and object detection models. In this short paper, we present a first of its kind demonstration of adversarial attacks against speech classification model. Our algorithm performs targeted attacks with 87% success by adding small background noise without having to know the underlying model parameter and architecture. Our attack only changes the least significant bits of a subset of audio clip samples, and the noise does not change 89% the human listener's perception of the audio clip as evaluated in our human study.