 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDid you hear that? Adversarial Examples Against Automatic Speech Recognition
Paper and Code
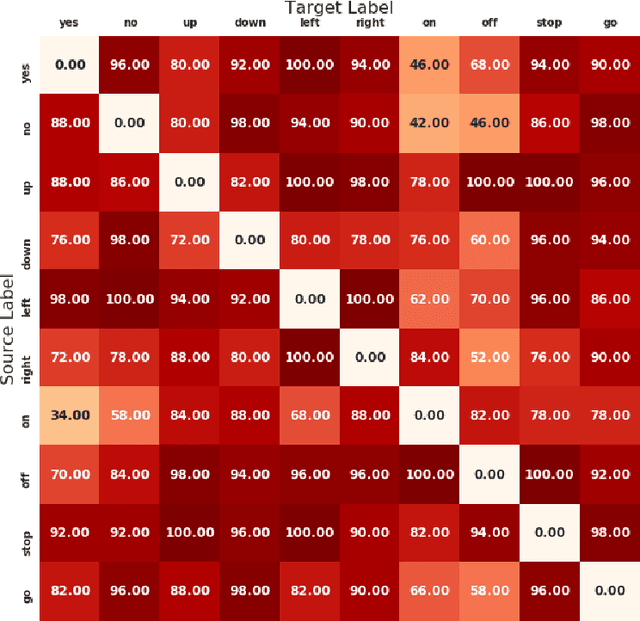
Speech is a common and effective way of communication between humans, and modern consumer devices such as smartphones and home hubs are equipped with deep learning based accurate automatic speech recognition to enable natural interaction between humans and machines. Recently, researchers have demonstrated powerful attacks against machine learning models that can fool them to produceincorrect results. However, nearly all previous research in adversarial attacks has focused on image recognition and object detection models. In this short paper, we present a first of its kind demonstration of adversarial attacks against speech classification model. Our algorithm performs targeted attacks with 87% success by adding small background noise without having to know the underlying model parameter and architecture. Our attack only changes the least significant bits of a subset of audio clip samples, and the noise does not change 89% the human listener's perception of the audio clip as evaluated in our human study.