 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Passive Radar via an Uncertainty-Aware Fusion of Wi-Fi Sensing Data
Jul 01, 2024Wi-Fi devices can effectively be used as passive radar systems that sense what happens in the surroundings and can even discern human activity. We propose, for the first time, a principled architecture which employs Variational Auto-Encoders for estimating a latent distribution responsible for generating the data, and Evidential Deep Learning for its ability to sense out-of-distribution activities. We verify that the fused data processed by different antennas of the same Wi-Fi receiver results in increased accuracy of human activity recognition compared with the most recent benchmarks, while still being informative when facing out-of-distribution samples and enabling semantic interpretation of latent variables in terms of physical phenomena. The results of this paper are a first contribution toward the ultimate goal of providing a flexible, semantic characterisation of black-swan events, i.e., events for which we have limited to no training data.
Neuro-Symbolic Fusion of Wi-Fi Sensing Data for Passive Radar with Inter-Modal Knowledge Transfer
Jul 01, 2024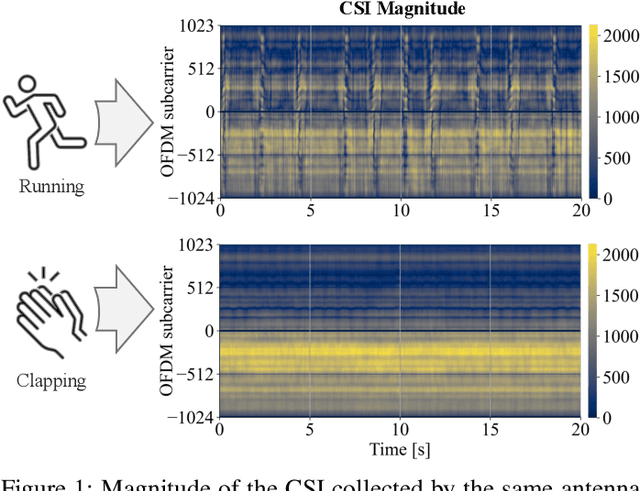
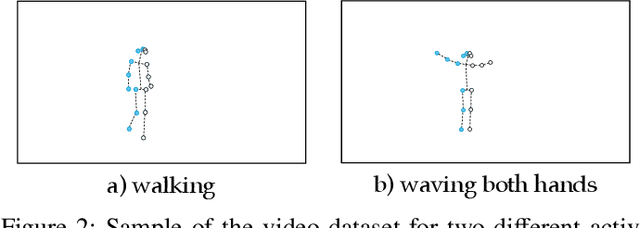
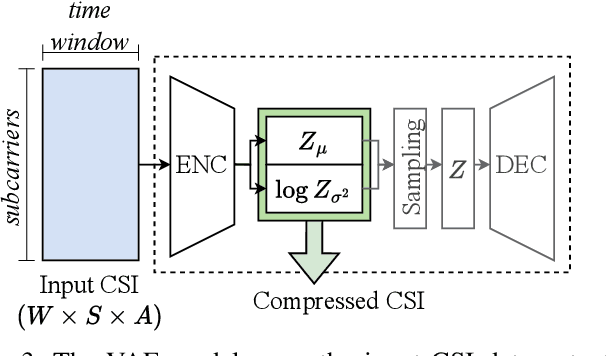
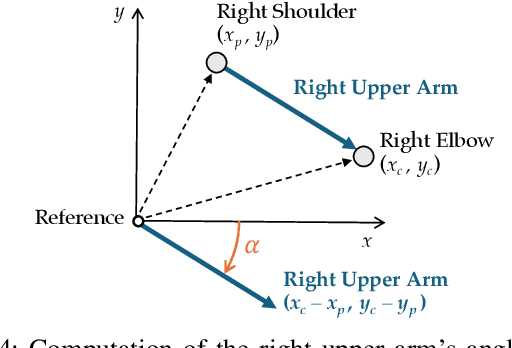
Wi-Fi devices, akin to passive radars, can discern human activities within indoor settings due to the human body's interaction with electromagnetic signals. Current Wi-Fi sensing applications predominantly employ data-driven learning techniques to associate the fluctuations in the physical properties of the communication channel with the human activity causing them. However, these techniques often lack the desired flexibility and transparency. This paper introduces DeepProbHAR, a neuro-symbolic architecture for Wi-Fi sensing, providing initial evidence that Wi-Fi signals can differentiate between simple movements, such as leg or arm movements, which are integral to human activities like running or walking. The neuro-symbolic approach affords gathering such evidence without needing additional specialised data collection or labelling. The training of DeepProbHAR is facilitated by declarative domain knowledge obtained from a camera feed and by fusing signals from various antennas of the Wi-Fi receivers. DeepProbHAR achieves results comparable to the state-of-the-art in human activity recognition. Moreover, as a by-product of the learning process, DeepProbHAR generates specialised classifiers for simple movements that match the accuracy of models trained on finely labelled datasets, which would be particularly costly.
An Empirical Evaluation of Neural and Neuro-symbolic Approaches to Real-time Multimodal Complex Event Detection
Feb 17, 2024Robots and autonomous systems require an understanding of complex events (CEs) from sensor data to interact with their environments and humans effectively. Traditional end-to-end neural architectures, despite processing sensor data efficiently, struggle with long-duration events due to limited context sizes and reasoning capabilities. Recent advances in neuro-symbolic methods, which integrate neural and symbolic models leveraging human knowledge, promise improved performance with less data. This study addresses the gap in understanding these approaches' effectiveness in complex event detection (CED), especially in temporal reasoning. We investigate neural and neuro-symbolic architectures' performance in a multimodal CED task, analyzing IMU and acoustic data streams to recognize CE patterns. Our methodology includes (i) end-to-end neural architectures for direct CE detection from sensor embeddings, (ii) two-stage concept-based neural models mapping sensor embeddings to atomic events (AEs) before CE detection, and (iii) a neuro-symbolic approach using a symbolic finite-state machine for CE detection from AEs. Empirically, the neuro-symbolic architecture significantly surpasses purely neural models, demonstrating superior performance in CE recognition, even with extensive training data and ample temporal context for neural approaches.
Deep Residual Neural Networks for Audio Spoofing Detection
Jun 30, 2019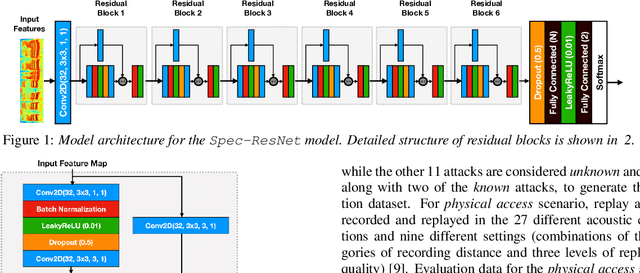
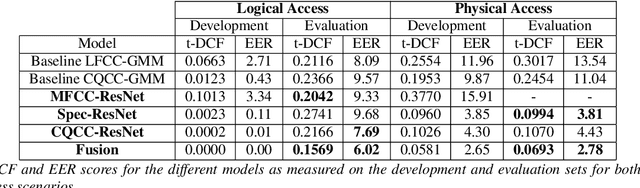
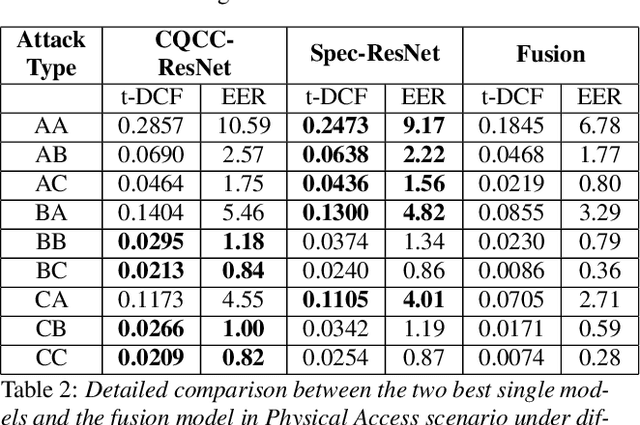
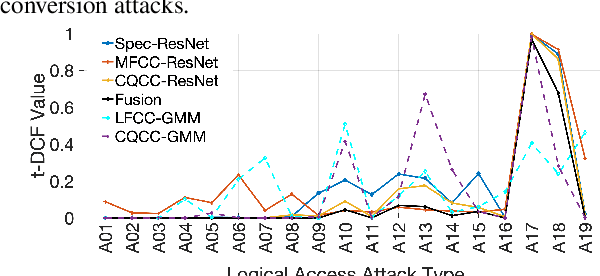
The state-of-art models for speech synthesis and voice conversion are capable of generating synthetic speech that is perceptually indistinguishable from bonafide human speech. These methods represent a threat to the automatic speaker verification (ASV) systems. Additionally, replay attacks where the attacker uses a speaker to replay a previously recorded genuine human speech are also possible. We present our solution for the ASVSpoof2019 competition, which aims to develop countermeasure systems that distinguish between spoofing attacks and genuine speeches. Our model is inspired by the success of residual convolutional networks in many classification tasks. We build three variants of a residual convolutional neural network that accept different feature representations (MFCC, Log-magnitude STFT, and CQCC) of input. We compare the performance achieved by our model variants and the competition baseline models. In the logical access scenario, the fusion of our models has zero t-DCF cost and zero equal error rate (EER), as evaluated on the development set. On the evaluation set, our model fusion improves the t-DCF and EER by 25% compared to the baseline algorithms. Against physical access replay attacks, our model fusion improves the baseline algorithms t-DCF and EER scores by 71% and 75% on the evaluation set, respectively.
SenseGen: A Deep Learning Architecture for Synthetic Sensor Data Generation
Jan 31, 2017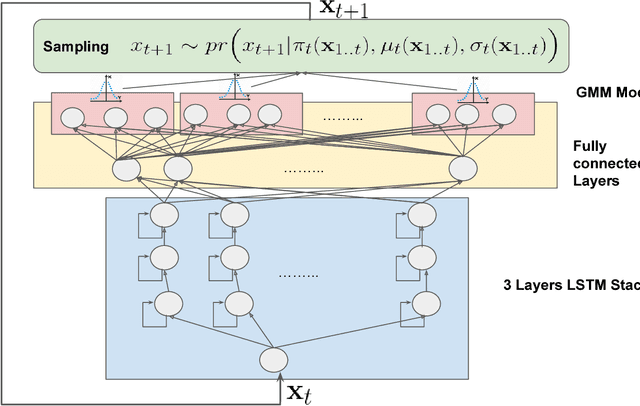
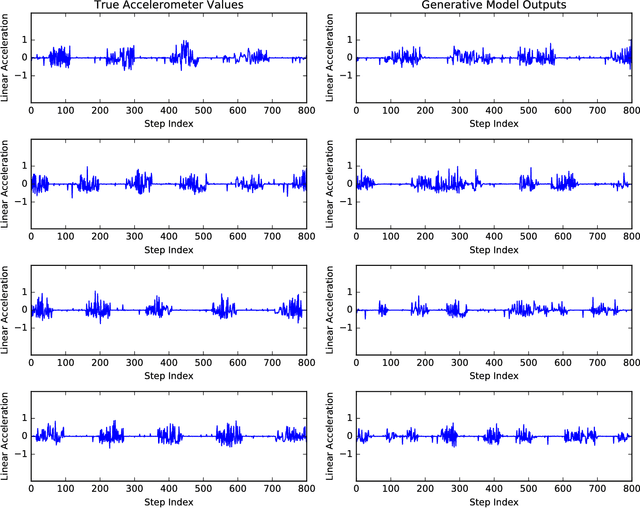
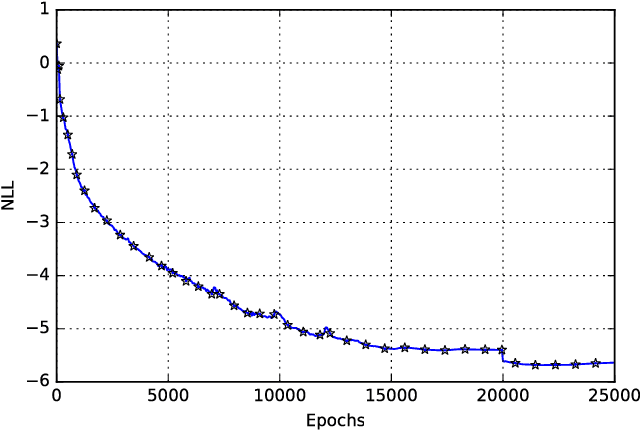
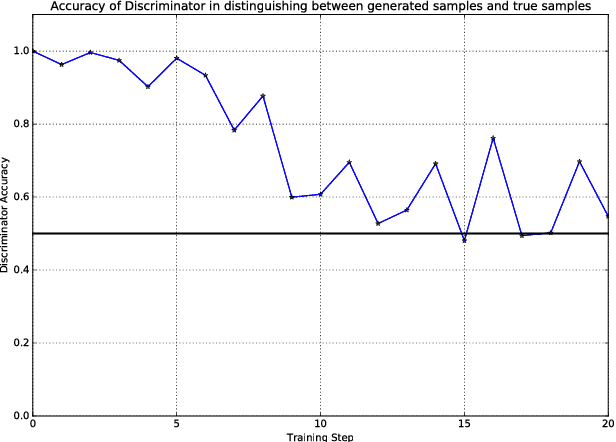
Our ability to synthesize sensory data that preserves specific statistical properties of the real data has had tremendous implications on data privacy and big data analytics. The synthetic data can be used as a substitute for selective real data segments,that are sensitive to the user, thus protecting privacy and resulting in improved analytics.However, increasingly adversarial roles taken by data recipients such as mobile apps, or other cloud-based analytics services, mandate that the synthetic data, in addition to preserving statistical properties, should also be difficult to distinguish from the real data. Typically, visual inspection has been used as a test to distinguish between datasets. But more recently, sophisticated classifier models (discriminators), corresponding to a set of events, have also been employed to distinguish between synthesized and real data. The model operates on both datasets and the respective event outputs are compared for consistency. In this paper, we take a step towards generating sensory data that can pass a deep learning based discriminator model test, and make two specific contributions: first, we present a deep learning based architecture for synthesizing sensory data. This architecture comprises of a generator model, which is a stack of multiple Long-Short-Term-Memory (LSTM) networks and a Mixture Density Network. second, we use another LSTM network based discriminator model for distinguishing between the true and the synthesized data. Using a dataset of accelerometer traces, collected using smartphones of users doing their daily activities, we show that the deep learning based discriminator model can only distinguish between the real and synthesized traces with an accuracy in the neighborhood of 50%.