 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting with Generated Data: Annotation-Free LLM Skill Estimation and Expert Selection
Jan 14, 2026Large Language Model (LLM) routers dynamically select optimal models for given inputs. Existing approaches typically assume access to ground-truth labeled data, which is often unavailable in practice, especially when user request distributions are heterogeneous and unknown. We introduce Routing with Generated Data (RGD), a challenging setting in which routers are trained exclusively on generated queries and answers produced from high-level task descriptions by generator LLMs. We evaluate query-answer routers (using both queries and labels) and query-only routers across four diverse benchmarks and 12 models, finding that query-answer routers degrade faster than query-only routers as generator quality decreases. Our analysis reveals two crucial characteristics of effective generators: they must accurately respond to their own questions, and their questions must produce sufficient performance differentiation among the model pool. We then show how filtering for these characteristics can improve the quality of generated data. We further propose CASCAL, a novel query-only router that estimates model correctness through consensus voting and identifies model-specific skill niches via hierarchical clustering. CASCAL is substantially more robust to generator quality, outperforming the best query-answer router by 4.6% absolute accuracy when trained on weak generator data.
Leveraging Parameter Space Symmetries for Reasoning Skill Transfer in LLMs
Nov 13, 2025Task arithmetic is a powerful technique for transferring skills between Large Language Models (LLMs), but it often suffers from negative interference when models have diverged during training. We address this limitation by first aligning the models' parameter spaces, leveraging the inherent permutation, rotation, and scaling symmetries of Transformer architectures. We adapt parameter space alignment for modern Grouped-Query Attention (GQA) and SwiGLU layers, exploring both weight-based and activation-based approaches. Using this alignment-first strategy, we successfully transfer advanced reasoning skills to a non-reasoning model. Experiments on challenging reasoning benchmarks show that our method consistently outperforms standard task arithmetic. This work provides an effective approach for merging and transferring specialized skills across evolving LLM families, reducing redundant fine-tuning and enhancing model adaptability.
SPEAR-MM: Selective Parameter Evaluation and Restoration via Model Merging for Efficient Financial LLM Adaptation
Nov 11, 2025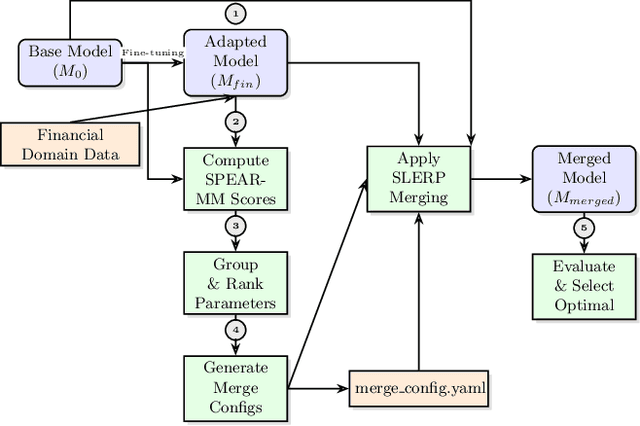


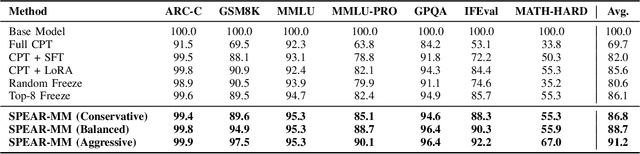
Large language models (LLMs) adapted to financial domains often suffer from catastrophic forgetting of general reasoning capabilities essential for customer interactions and complex financial analysis. We introduce Selective Parameter Evaluation and Restoration via Model Merging (SPEAR-MM), a practical framework that preserves critical capabilities while enabling domain adaptation. Our method approximates layer-wise impact on external benchmarks through post-hoc analysis, then selectively freezes or restores transformer layers via spherical interpolation merging. Applied to LLaMA-3.1-8B for financial tasks, SPEAR-MM achieves 91.2% retention of general capabilities versus 69.7% for standard continual pretraining, while maintaining 94% of domain adaptation gains. The approach provides interpretable trade-off control and reduces computational costs by 90% crucial for resource-constrained financial institutions.
Optimizing Reasoning Efficiency through Prompt Difficulty Prediction
Nov 05, 2025Reasoning language models perform well on complex tasks but are costly to deploy due to their size and long reasoning traces. We propose a routing approach that assigns each problem to the smallest model likely to solve it, reducing compute without sacrificing accuracy. Using intermediate representations from s1.1-32B, we train lightweight predictors of problem difficulty or model correctness to guide routing across a pool of reasoning models. On diverse math benchmarks, routing improves efficiency over random assignment and matches s1.1-32B's performance while using significantly less compute. Our results demonstrate that difficulty-aware routing is effective for cost-efficient deployment of reasoning models.
On Understanding of the Dynamics of Model Capacity in Continual Learning
Aug 11, 2025The stability-plasticity dilemma, closely related to a neural network's (NN) capacity-its ability to represent tasks-is a fundamental challenge in continual learning (CL). Within this context, we introduce CL's effective model capacity (CLEMC) that characterizes the dynamic behavior of the stability-plasticity balance point. We develop a difference equation to model the evolution of the interplay between the NN, task data, and optimization procedure. We then leverage CLEMC to demonstrate that the effective capacity-and, by extension, the stability-plasticity balance point is inherently non-stationary. We show that regardless of the NN architecture or optimization method, a NN's ability to represent new tasks diminishes when incoming task distributions differ from previous ones. We conduct extensive experiments to support our theoretical findings, spanning a range of architectures-from small feedforward network and convolutional networks to medium-sized graph neural networks and transformer-based large language models with millions of parameters.
Training Dynamics Underlying Language Model Scaling Laws: Loss Deceleration and Zero-Sum Learning
Jun 05, 2025This work aims to understand how scaling improves language models, specifically in terms of training dynamics. We find that language models undergo loss deceleration early in training; an abrupt slowdown in the rate of loss improvement, resulting in piecewise linear behaviour of the loss curve in log-log space. Scaling up the model mitigates this transition by (1) decreasing the loss at which deceleration occurs, and (2) improving the log-log rate of loss improvement after deceleration. We attribute loss deceleration to a type of degenerate training dynamics we term zero-sum learning (ZSL). In ZSL, per-example gradients become systematically opposed, leading to destructive interference in per-example changes in loss. As a result, improving loss on one subset of examples degrades it on another, bottlenecking overall progress. Loss deceleration and ZSL provide new insights into the training dynamics underlying language model scaling laws, and could potentially be targeted directly to improve language models independent of scale. We make our code and artefacts available at: https://github.com/mirandrom/zsl
Critique-Guided Distillation: Improving Supervised Fine-tuning via Better Distillation
May 16, 2025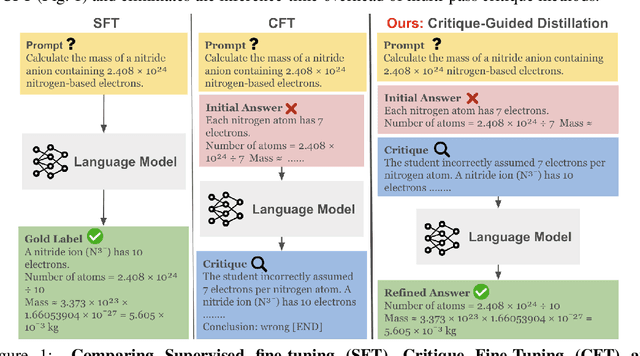



Supervised fine-tuning (SFT) using expert demonstrations often suffer from the imitation problem, where the model learns to reproduce the correct responses without \emph{understanding} the underlying rationale. To address this limitation, we propose \textsc{Critique-Guided Distillation (CGD)}, a novel multi-stage framework that integrates teacher model generated \emph{explanatory critiques} and \emph{refined responses} into the SFT process. A student model is then trained to map the triplet of prompt, teacher critique, and its own initial response to the corresponding refined teacher response, thereby learning both \emph{what} to imitate and \emph{why}. Using entropy-based analysis, we show that \textsc{CGD} reduces refinement uncertainty and can be interpreted as a Bayesian posterior update. We perform extensive empirical evaluation of \textsc{CGD}, on variety of benchmark tasks, and demonstrate significant gains on both math (AMC23 +17.5%) and language understanding tasks (MMLU-Pro +6.3%), while successfully mitigating the format drift issues observed in previous critique fine-tuning (CFT) techniques.
Dense Backpropagation Improves Training for Sparse Mixture-of-Experts
Apr 18, 2025Mixture of Experts (MoE) pretraining is more scalable than dense Transformer pretraining, because MoEs learn to route inputs to a sparse set of their feedforward parameters. However, this means that MoEs only receive a sparse backward update, leading to training instability and suboptimal performance. We present a lightweight approximation method that gives the MoE router a dense gradient update while continuing to sparsely activate its parameters. Our method, which we refer to as Default MoE, substitutes missing expert activations with default outputs consisting of an exponential moving average of expert outputs previously seen over the course of training. This allows the router to receive signals from every expert for each token, leading to significant improvements in training performance. Our Default MoE outperforms standard TopK routing in a variety of settings without requiring significant computational overhead. Code: https://github.com/vatsal0/default-moe.
SaViD: Spectravista Aesthetic Vision Integration for Robust and Discerning 3D Object Detection in Challenging Environments
Mar 26, 2025



The fusion of LiDAR and camera sensors has demonstrated significant effectiveness in achieving accurate detection for short-range tasks in autonomous driving. However, this fusion approach could face challenges when dealing with long-range detection scenarios due to disparity between sparsity of LiDAR and high-resolution camera data. Moreover, sensor corruption introduces complexities that affect the ability to maintain robustness, despite the growing adoption of sensor fusion in this domain. We present SaViD, a novel framework comprised of a three-stage fusion alignment mechanism designed to address long-range detection challenges in the presence of natural corruption. The SaViD framework consists of three key elements: the Global Memory Attention Network (GMAN), which enhances the extraction of image features through offering a deeper understanding of global patterns; the Attentional Sparse Memory Network (ASMN), which enhances the integration of LiDAR and image features; and the KNNnectivity Graph Fusion (KGF), which enables the entire fusion of spatial information. SaViD achieves superior performance on the long-range detection Argoverse-2 (AV2) dataset with a performance improvement of 9.87% in AP value and an improvement of 2.39% in mAPH for L2 difficulties on the Waymo Open dataset (WOD). Comprehensive experiments are carried out to showcase its robustness against 14 natural sensor corruptions. SaViD exhibits a robust performance improvement of 31.43% for AV2 and 16.13% for WOD in RCE value compared to other existing fusion-based methods while considering all the corruptions for both datasets. Our code is available at \href{https://github.com/sanjay-810/SAVID}
MYCROFT: Towards Effective and Efficient External Data Augmentation
Oct 11, 2024



Machine learning (ML) models often require large amounts of data to perform well. When the available data is limited, model trainers may need to acquire more data from external sources. Often, useful data is held by private entities who are hesitant to share their data due to propriety and privacy concerns. This makes it challenging and expensive for model trainers to acquire the data they need to improve model performance. To address this challenge, we propose Mycroft, a data-efficient method that enables model trainers to evaluate the relative utility of different data sources while working with a constrained data-sharing budget. By leveraging feature space distances and gradient matching, Mycroft identifies small but informative data subsets from each owner, allowing model trainers to maximize performance with minimal data exposure. Experimental results across four tasks in two domains show that Mycroft converges rapidly to the performance of the full-information baseline, where all data is shared. Moreover, Mycroft is robust to noise and can effectively rank data owners by utility. Mycroft can pave the way for democratized training of high performance ML models.