 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText to Automata Diagrams: Comparing TikZ Code Generation with Direct Image Synthesis
Mar 09, 2026Diagrams are widely used in teaching computer science courses. They are useful in subjects such as automata and formal languages, data structures, etc. These diagrams, often drawn by students during exams or assignments, vary in structure, layout, and correctness. This study examines whether current vision-language and large language models can process such diagrams and produce accurate textual and digital representations. In this study, scanned student-drawn diagrams are used as input. Then, textual descriptions are generated from these images using a vision-language model. The descriptions are checked and revised by human reviewers to make them accurate. Both the generated and the revised descriptions are then fed to a large language model to generate TikZ code. The resulting diagrams are compiled and then evaluated against the original scanned diagrams. We found descriptions generated directly from images using vision-language models are often incorrect and human correction can substantially improve the quality of vision language model generated descriptions. This research can help computer science education by paving the way for automated grading and feedback and creating more accessible instructional materials.
SaViD: Spectravista Aesthetic Vision Integration for Robust and Discerning 3D Object Detection in Challenging Environments
Mar 26, 2025



The fusion of LiDAR and camera sensors has demonstrated significant effectiveness in achieving accurate detection for short-range tasks in autonomous driving. However, this fusion approach could face challenges when dealing with long-range detection scenarios due to disparity between sparsity of LiDAR and high-resolution camera data. Moreover, sensor corruption introduces complexities that affect the ability to maintain robustness, despite the growing adoption of sensor fusion in this domain. We present SaViD, a novel framework comprised of a three-stage fusion alignment mechanism designed to address long-range detection challenges in the presence of natural corruption. The SaViD framework consists of three key elements: the Global Memory Attention Network (GMAN), which enhances the extraction of image features through offering a deeper understanding of global patterns; the Attentional Sparse Memory Network (ASMN), which enhances the integration of LiDAR and image features; and the KNNnectivity Graph Fusion (KGF), which enables the entire fusion of spatial information. SaViD achieves superior performance on the long-range detection Argoverse-2 (AV2) dataset with a performance improvement of 9.87% in AP value and an improvement of 2.39% in mAPH for L2 difficulties on the Waymo Open dataset (WOD). Comprehensive experiments are carried out to showcase its robustness against 14 natural sensor corruptions. SaViD exhibits a robust performance improvement of 31.43% for AV2 and 16.13% for WOD in RCE value compared to other existing fusion-based methods while considering all the corruptions for both datasets. Our code is available at \href{https://github.com/sanjay-810/SAVID}
Comparative Analysis of OpenAI GPT-4o and DeepSeek R1 for Scientific Text Categorization Using Prompt Engineering
Mar 03, 2025



This study examines how large language models categorize sentences from scientific papers using prompt engineering. We use two advanced web-based models, GPT-4o (by OpenAI) and DeepSeek R1, to classify sentences into predefined relationship categories. DeepSeek R1 has been tested on benchmark datasets in its technical report. However, its performance in scientific text categorization remains unexplored. To address this gap, we introduce a new evaluation method designed specifically for this task. We also compile a dataset of cleaned scientific papers from diverse domains. This dataset provides a platform for comparing the two models. Using this dataset, we analyze their effectiveness and consistency in categorization.
Quantum Inverse Contextual Vision Transformers (Q-ICVT): A New Frontier in 3D Object Detection for AVs
Aug 20, 2024



The field of autonomous vehicles (AVs) predominantly leverages multi-modal integration of LiDAR and camera data to achieve better performance compared to using a single modality. However, the fusion process encounters challenges in detecting distant objects due to the disparity between the high resolution of cameras and the sparse data from LiDAR. Insufficient integration of global perspectives with local-level details results in sub-optimal fusion performance.To address this issue, we have developed an innovative two-stage fusion process called Quantum Inverse Contextual Vision Transformers (Q-ICVT). This approach leverages adiabatic computing in quantum concepts to create a novel reversible vision transformer known as the Global Adiabatic Transformer (GAT). GAT aggregates sparse LiDAR features with semantic features in dense images for cross-modal integration in a global form. Additionally, the Sparse Expert of Local Fusion (SELF) module maps the sparse LiDAR 3D proposals and encodes position information of the raw point cloud onto the dense camera feature space using a gating point fusion approach. Our experiments show that Q-ICVT achieves an mAPH of 82.54 for L2 difficulties on the Waymo dataset, improving by 1.88% over current state-of-the-art fusion methods. We also analyze GAT and SELF in ablation studies to highlight the impact of Q-ICVT. Our code is available at https://github.com/sanjay-810/Qicvt Q-ICVT
A Critical Analysis of the Limitation of Deep Learning based 3D Dental Mesh Segmentation Methods in Segmenting Partial Scans
Apr 29, 2023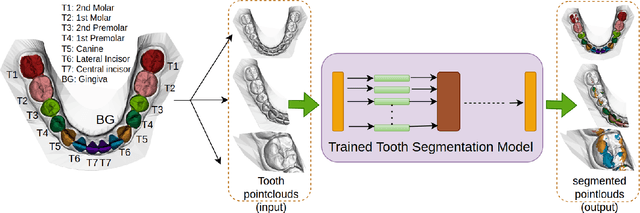

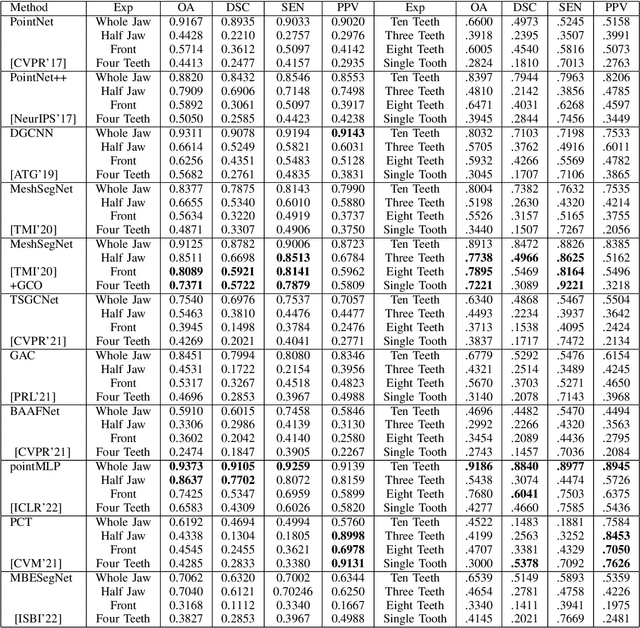
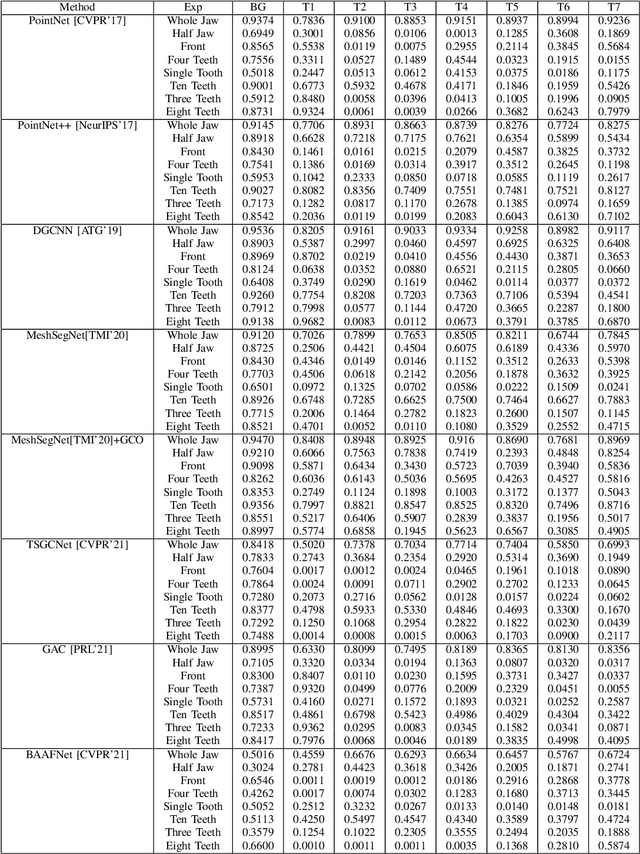
Tooth segmentation from intraoral scans is a crucial part of digital dentistry. Many Deep Learning based tooth segmentation algorithms have been developed for this task. In most of the cases, high accuracy has been achieved, although, most of the available tooth segmentation techniques make an implicit restrictive assumption of full jaw model and they report accuracy based on full jaw models. Medically, however, in certain cases, full jaw tooth scan is not required or may not be available. Given this practical issue, it is important to understand the robustness of currently available widely used Deep Learning based tooth segmentation techniques. For this purpose, we applied available segmentation techniques on partial intraoral scans and we discovered that the available deep Learning techniques under-perform drastically. The analysis and comparison presented in this work would help us in understanding the severity of the problem and allow us to develop robust tooth segmentation technique without strong assumption of full jaw model.