 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaViD: Spectravista Aesthetic Vision Integration for Robust and Discerning 3D Object Detection in Challenging Environments
Mar 26, 2025



The fusion of LiDAR and camera sensors has demonstrated significant effectiveness in achieving accurate detection for short-range tasks in autonomous driving. However, this fusion approach could face challenges when dealing with long-range detection scenarios due to disparity between sparsity of LiDAR and high-resolution camera data. Moreover, sensor corruption introduces complexities that affect the ability to maintain robustness, despite the growing adoption of sensor fusion in this domain. We present SaViD, a novel framework comprised of a three-stage fusion alignment mechanism designed to address long-range detection challenges in the presence of natural corruption. The SaViD framework consists of three key elements: the Global Memory Attention Network (GMAN), which enhances the extraction of image features through offering a deeper understanding of global patterns; the Attentional Sparse Memory Network (ASMN), which enhances the integration of LiDAR and image features; and the KNNnectivity Graph Fusion (KGF), which enables the entire fusion of spatial information. SaViD achieves superior performance on the long-range detection Argoverse-2 (AV2) dataset with a performance improvement of 9.87% in AP value and an improvement of 2.39% in mAPH for L2 difficulties on the Waymo Open dataset (WOD). Comprehensive experiments are carried out to showcase its robustness against 14 natural sensor corruptions. SaViD exhibits a robust performance improvement of 31.43% for AV2 and 16.13% for WOD in RCE value compared to other existing fusion-based methods while considering all the corruptions for both datasets. Our code is available at \href{https://github.com/sanjay-810/SAVID}
AYDIV: Adaptable Yielding 3D Object Detection via Integrated Contextual Vision Transformer
Feb 12, 2024Combining LiDAR and camera data has shown potential in enhancing short-distance object detection in autonomous driving systems. Yet, the fusion encounters difficulties with extended distance detection due to the contrast between LiDAR's sparse data and the dense resolution of cameras. Besides, discrepancies in the two data representations further complicate fusion methods. We introduce AYDIV, a novel framework integrating a tri-phase alignment process specifically designed to enhance long-distance detection even amidst data discrepancies. AYDIV consists of the Global Contextual Fusion Alignment Transformer (GCFAT), which improves the extraction of camera features and provides a deeper understanding of large-scale patterns; the Sparse Fused Feature Attention (SFFA), which fine-tunes the fusion of LiDAR and camera details; and the Volumetric Grid Attention (VGA) for a comprehensive spatial data fusion. AYDIV's performance on the Waymo Open Dataset (WOD) with an improvement of 1.24% in mAPH value(L2 difficulty) and the Argoverse2 Dataset with a performance improvement of 7.40% in AP value demonstrates its efficacy in comparison to other existing fusion-based methods. Our code is publicly available at https://github.com/sanjay-810/AYDIV2
Left-right Discrepancy for Adversarial Attack on Stereo Networks
Jan 14, 2024Stereo matching neural networks often involve a Siamese structure to extract intermediate features from left and right images. The similarity between these intermediate left-right features significantly impacts the accuracy of disparity estimation. In this paper, we introduce a novel adversarial attack approach that generates perturbation noise specifically designed to maximize the discrepancy between left and right image features. Extensive experiments demonstrate the superior capability of our method to induce larger prediction errors in stereo neural networks, e.g. outperforming existing state-of-the-art attack methods by 219% MAE on the KITTI dataset and 85% MAE on the Scene Flow dataset. Additionally, we extend our approach to include a proxy network black-box attack method, eliminating the need for access to stereo neural network. This method leverages an arbitrary network from a different vision task as a proxy to generate adversarial noise, effectively causing the stereo network to produce erroneous predictions. Our findings highlight a notable sensitivity of stereo networks to discrepancies in shallow layer features, offering valuable insights that could guide future research in enhancing the robustness of stereo vision systems.
Model Generalization in Arrival Runway Occupancy Time Prediction by Feature Equivalences
Jan 25, 2022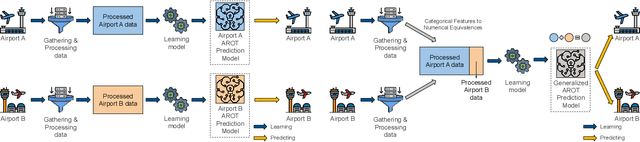
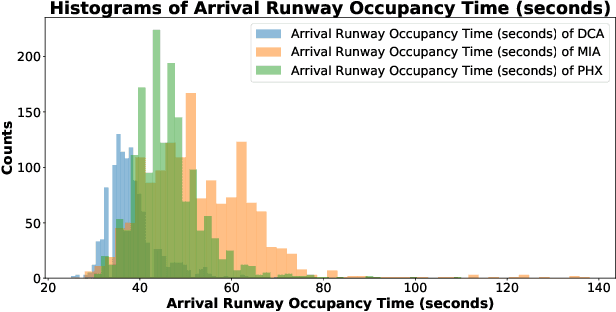

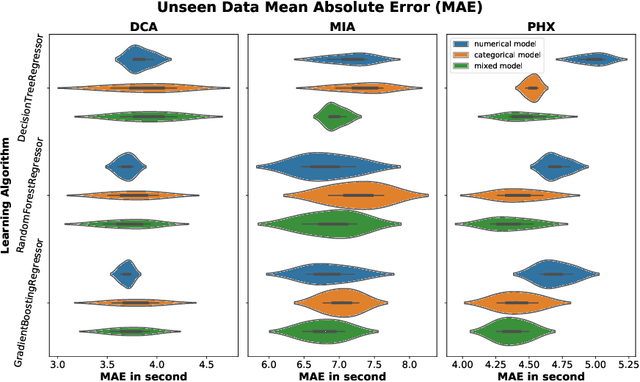
General real-time runway occupancy time prediction modelling for multiple airports is a current research gap. An attempt to generalize a real-time prediction model for Arrival Runway Occupancy Time (AROT) is presented in this paper by substituting categorical features by their numerical equivalences. Three days of data, collected from Saab Sensis' Aerobahn system at three US airports, has been used for this work. Three tree-based machine learning algorithms: Decision Tree, Random Forest and Gradient Boosting are used to assess the generalizability of the model using numerical equivalent features. We have shown that the model trained on numerical equivalent features not only have performances at least on par with models trained on categorical features but also can make predictions on unseen data from other airports.
Deep4Air: A Novel Deep Learning Framework for Airport Airside Surveillance
Oct 02, 2020
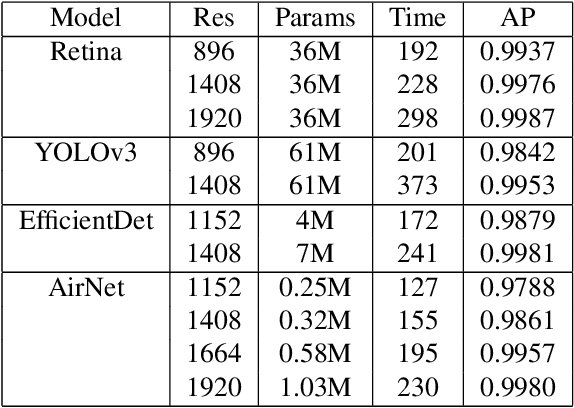
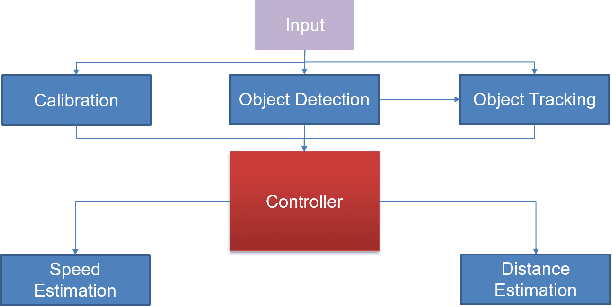

An airport runway and taxiway (airside) area is a highly dynamic and complex environment featuring interactions between different types of vehicles (speed and dimension), under varying visibility and traffic conditions. Airport ground movements are deemed safety-critical activities, and safe-separation procedures must be maintained by Air Traffic Controllers (ATCs). Large airports with complicated runway-taxiway systems use advanced ground surveillance systems. However, these systems have inherent limitations and a lack of real-time analytics. In this paper, we propose a novel computer-vision based framework, namely "Deep4Air", which can not only augment the ground surveillance systems via the automated visual monitoring of runways and taxiways for aircraft location, but also provide real-time speed and distance analytics for aircraft on runways and taxiways. The proposed framework includes an adaptive deep neural network for efficiently detecting and tracking aircraft. The experimental results show an average precision of detection and tracking of up to 99.8% on simulated data with validations on surveillance videos from the digital tower at George Bush Intercontinental Airport. The results also demonstrate that "Deep4Air" can locate aircraft positions relative to the airport runway and taxiway infrastructure with high accuracy. Furthermore, aircraft speed and separation distance are monitored in real-time, providing enhanced safety management.