 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Backpropagation Improves Training for Sparse Mixture-of-Experts
Apr 18, 2025Mixture of Experts (MoE) pretraining is more scalable than dense Transformer pretraining, because MoEs learn to route inputs to a sparse set of their feedforward parameters. However, this means that MoEs only receive a sparse backward update, leading to training instability and suboptimal performance. We present a lightweight approximation method that gives the MoE router a dense gradient update while continuing to sparsely activate its parameters. Our method, which we refer to as Default MoE, substitutes missing expert activations with default outputs consisting of an exponential moving average of expert outputs previously seen over the course of training. This allows the router to receive signals from every expert for each token, leading to significant improvements in training performance. Our Default MoE outperforms standard TopK routing in a variety of settings without requiring significant computational overhead. Code: https://github.com/vatsal0/default-moe.
Continual Pre-training of MoEs: How robust is your router?
Mar 06, 2025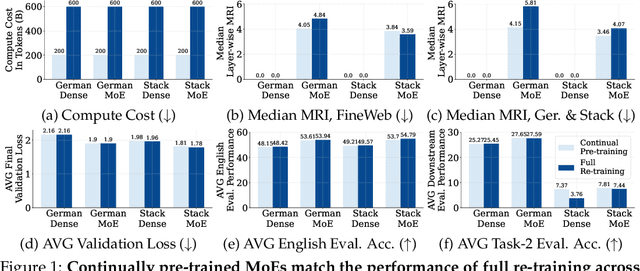
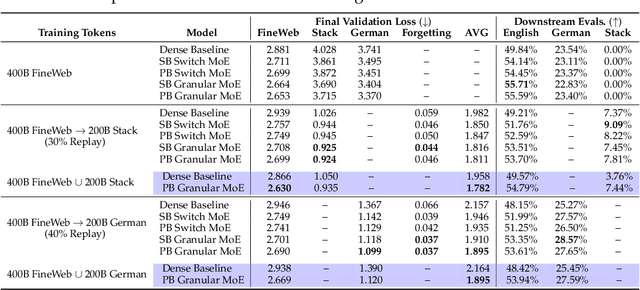
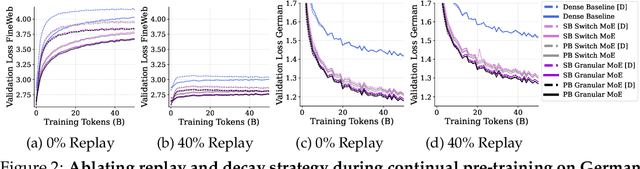
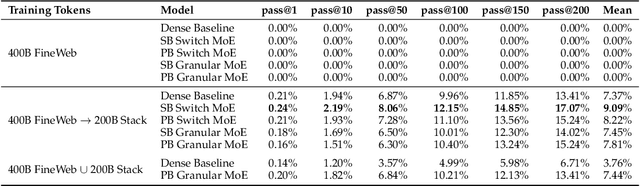
Sparsely-activated Mixture of Experts (MoE) transformers are promising architectures for foundation models. Compared to dense transformers that require the same amount of floating point operations (FLOPs) per forward pass, MoEs benefit from improved sample efficiency at training time and achieve much stronger performance. Many closed-source and open-source frontier language models have thus adopted an MoE architecture. Naturally, practitioners will want to extend the capabilities of these models with large amounts of newly collected data without completely re-training them. Prior work has shown that a simple combination of replay and learning rate re-warming and re-decaying can enable the continual pre-training (CPT) of dense decoder-only transformers with minimal performance degradation compared to full re-training. In the case of decoder-only MoE transformers, however, it is unclear how the routing algorithm will impact continual pre-training performance: 1) do the MoE transformer's routers exacerbate forgetting relative to a dense model?; 2) do the routers maintain a balanced load on previous distributions after CPT?; 3) are the same strategies applied to dense models sufficient to continually pre-train MoE LLMs? In what follows, we conduct a large-scale (>2B parameter switch and DeepSeek MoE LLMs trained for 600B tokens) empirical study across four MoE transformers to answer these questions. Our results establish a surprising robustness to distribution shifts for both Sinkhorn-Balanced and Z-and-Aux-loss-balanced routing algorithms, even in MoEs continually pre-trained without replay. Moreover, we show that MoE LLMs maintain their sample efficiency (relative to a FLOP-matched dense model) during CPT and that they can match the performance of a fully re-trained MoE at a fraction of the cost.
MYCROFT: Towards Effective and Efficient External Data Augmentation
Oct 11, 2024



Machine learning (ML) models often require large amounts of data to perform well. When the available data is limited, model trainers may need to acquire more data from external sources. Often, useful data is held by private entities who are hesitant to share their data due to propriety and privacy concerns. This makes it challenging and expensive for model trainers to acquire the data they need to improve model performance. To address this challenge, we propose Mycroft, a data-efficient method that enables model trainers to evaluate the relative utility of different data sources while working with a constrained data-sharing budget. By leveraging feature space distances and gradient matching, Mycroft identifies small but informative data subsets from each owner, allowing model trainers to maximize performance with minimal data exposure. Experimental results across four tasks in two domains show that Mycroft converges rapidly to the performance of the full-information baseline, where all data is shared. Moreover, Mycroft is robust to noise and can effectively rank data owners by utility. Mycroft can pave the way for democratized training of high performance ML models.
Deepfake Text Detection: Limitations and Opportunities
Oct 17, 2022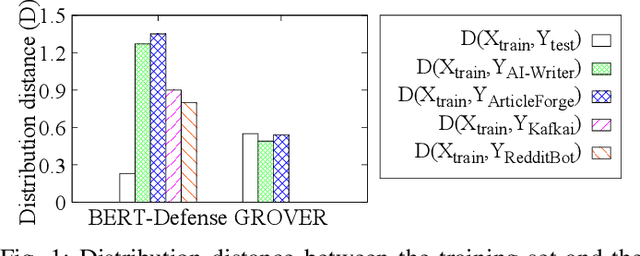
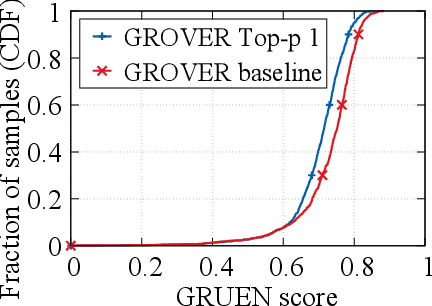
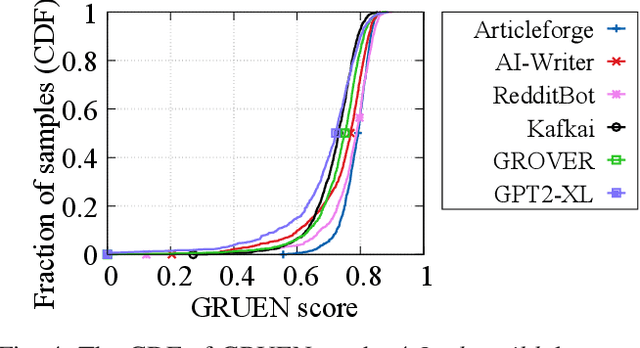
Recent advances in generative models for language have enabled the creation of convincing synthetic text or deepfake text. Prior work has demonstrated the potential for misuse of deepfake text to mislead content consumers. Therefore, deepfake text detection, the task of discriminating between human and machine-generated text, is becoming increasingly critical. Several defenses have been proposed for deepfake text detection. However, we lack a thorough understanding of their real-world applicability. In this paper, we collect deepfake text from 4 online services powered by Transformer-based tools to evaluate the generalization ability of the defenses on content in the wild. We develop several low-cost adversarial attacks, and investigate the robustness of existing defenses against an adaptive attacker. We find that many defenses show significant degradation in performance under our evaluation scenarios compared to their original claimed performance. Our evaluation shows that tapping into the semantic information in the text content is a promising approach for improving the robustness and generalization performance of deepfake text detection schemes.