 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scalable Customization and Deployment of Multi-Agent Systems for Enterprise Applications
Jun 16, 2026Large language model (LLM)-based multi-agent systems demonstrate strong performance on complex reasoning and task execution, enabling broad enterprise applications. However, production deployment remains challenging due to domain-specific customization requirements and high latency and inference costs in agentic workflows. We propose a unified framework for customization and efficient deployment of multi-agent systems in real-world settings. The first stage, Agentic Model Customization, combines continual pretraining, supervised fine-tuning, and preference optimization to adapt a compact model to specialized domains while retaining strong agentic capabilities. The second stage, Inference Optimization, integrates speculative decoding and FP8 quantization with targeted calibration to enable cost-efficient serving with minimal quality loss. Across enterprise workloads, our framework enables rapid domain adaptation and achieves a 4.48x speedup in throughput while maintaining performance and improving robustness on long-tail scenarios.
T1-Bench: Benchmarking Multi-Scenario Agents in Real-World Domains
Jun 09, 2026Recent advances in reasoning and tool-calling capabilities of large language models (LLMs) have enabled increasingly capable agentic systems. However, existing benchmarks remain limited in task complexity, realism, and domain diversity, and often fail to capture interactions that span multiple domains, limiting their ability to evaluate agents in realistic multi-step settings that require sustained reasoning and coordination. To address these limitations, we introduce T1-Bench, a high-fidelity, comprehensive benchmark for evaluating agentic systems in realistic customer-facing, multi-domain environments, featuring interleaved scenarios that require structured reasoning across multi-turn user-assistant interactions and substantially increasing both compositional complexity and evaluative rigor across 25 domains of varying difficulty. We evaluate T1-Bench using 12 proprietary and open-weight models, providing a reproducible and standardized framework for assessing agent behavior, tool utilization, and conversational quality in complex, multi-step environments. We further complement automatic evaluation with human judgments to strengthen the assessment of qualitative performance. Overall, T1-Bench substantially advances prior benchmarks by increasing task complexity, interaction depth, and domain coverage in simulated multi-domain environments. To facilitate future research on agentic systems, we will publicly release data and evaluation code as open source.
MemGym: a Long-Horizon Memory Environment for LLM Agents
May 20, 2026Memory is a central capability for LLM agents operating across long-horizon tasks. Existing memory benchmarks predominantly evaluate retention of personalized information in multi-turn chat scenarios, overlooking the dynamic memory formation that occurs during extended agent execution. Consequently, the memory systems they produce transfer poorly to realistic agentic environments, such as coding and web navigation. We present MemGym, a benchmark for agentic memory that unifies existing agent gyms and in-house memory-grounded pipelines behind one memory-reasoning interface. MemGym spans five evaluation tracks grouped into four agentic regimes: tool-use dialogue (tau2-bench), multi-turn deep-research search (MEMGYM-DR), coding (SWE-Gym and MEMGYM-CODEQA), and computer use (WebArena-Infinity). MemGym reports memory-isolated scores that decouple memory performance from reasoning, retrieval, and tool-use ability, so memory strategies can be ranked without those confounders. Our synthetic pipelines for MEMGYM-CODEQA and MEMGYM-DR are length-controllable, ablation-verified at every stage, and tightly aligned with downstream scenarios. To make evaluation on coding environments academically tractable, we train MemRM, a lightweight reward model (Qwen3-1.7B fine-tuned with QLoRA) that scores compression quality as a fast scalar read in place of full Docker rollouts.
Your Model Diversity, Not Method, Determines Reasoning Strategy
Apr 12, 2026Compute scaling for LLM reasoning requires allocating budget between exploring solution approaches ($breadth$) and refining promising solutions ($depth$). Most methods implicitly trade off one for the other, yet why a given trade-off works remains unclear, and validation on a single model obscures the role of the model itself. We argue that $\textbf{the optimal strategy depends on the model's diversity profile, the spread of probability mass across solution approaches, and that this must be characterized before any exploration strategy is adopted.}$ We formalize this through a theoretical framework decomposing reasoning uncertainty and derive conditions under which tree-style depth refinement outperforms parallel sampling. We validate it on Qwen-3 4B and Olmo-3 7B families, showing that lightweight signals suffice for depth-based refinement on low-diversity aligned models while yielding limited utility for high-diversity base models, which we hypothesize require stronger compensation for lower exploration coverage.
DIAL-SUMMER: A Structured Evaluation Framework of Hierarchical Errors in Dialogue Summaries
Feb 08, 2026Dialogues are a predominant mode of communication for humans, and it is immensely helpful to have automatically generated summaries of them (e.g., to revise key points discussed in a meeting, to review conversations between customer agents and product users). Prior works on dialogue summary evaluation largely ignore the complexities specific to this task: (i) shift in structure, from multiple speakers discussing information in a scattered fashion across several turns, to a summary's sentences, and (ii) shift in narration viewpoint, from speakers' first/second-person narration, standardized third-person narration in the summary. In this work, we introduce our framework DIALSUMMER to address the above. We propose DIAL-SUMMER's taxonomy of errors to comprehensively evaluate dialogue summaries at two hierarchical levels: DIALOGUE-LEVEL that focuses on the broader speakers/turns, and WITHIN-TURN-LEVEL that focuses on the information talked about inside a turn. We then present DIAL-SUMMER's dataset composed of dialogue summaries manually annotated with our taxonomy's fine-grained errors. We conduct empirical analyses of these annotated errors, and observe interesting trends (e.g., turns occurring in middle of the dialogue are the most frequently missed in the summary, extrinsic hallucinations largely occur at the end of the summary). We also conduct experiments on LLM-Judges' capability at detecting these errors, through which we demonstrate the challenging nature of our dataset, the robustness of our taxonomy, and the need for future work in this field to enhance LLMs' performance in the same. Code and inference dataset coming soon.
Routing with Generated Data: Annotation-Free LLM Skill Estimation and Expert Selection
Jan 14, 2026Large Language Model (LLM) routers dynamically select optimal models for given inputs. Existing approaches typically assume access to ground-truth labeled data, which is often unavailable in practice, especially when user request distributions are heterogeneous and unknown. We introduce Routing with Generated Data (RGD), a challenging setting in which routers are trained exclusively on generated queries and answers produced from high-level task descriptions by generator LLMs. We evaluate query-answer routers (using both queries and labels) and query-only routers across four diverse benchmarks and 12 models, finding that query-answer routers degrade faster than query-only routers as generator quality decreases. Our analysis reveals two crucial characteristics of effective generators: they must accurately respond to their own questions, and their questions must produce sufficient performance differentiation among the model pool. We then show how filtering for these characteristics can improve the quality of generated data. We further propose CASCAL, a novel query-only router that estimates model correctness through consensus voting and identifies model-specific skill niches via hierarchical clustering. CASCAL is substantially more robust to generator quality, outperforming the best query-answer router by 4.6% absolute accuracy when trained on weak generator data.
Lessons from the Field: An Adaptable Lifecycle Approach to Applied Dialogue Summarization
Jan 13, 2026Summarization of multi-party dialogues is a critical capability in industry, enhancing knowledge transfer and operational effectiveness across many domains. However, automatically generating high-quality summaries is challenging, as the ideal summary must satisfy a set of complex, multi-faceted requirements. While summarization has received immense attention in research, prior work has primarily utilized static datasets and benchmarks, a condition rare in practical scenarios where requirements inevitably evolve. In this work, we present an industry case study on developing an agentic system to summarize multi-party interactions. We share practical insights spanning the full development lifecycle to guide practitioners in building reliable, adaptable summarization systems, as well as to inform future research, covering: 1) robust methods for evaluation despite evolving requirements and task subjectivity, 2) component-wise optimization enabled by the task decomposition inherent in an agentic architecture, 3) the impact of upstream data bottlenecks, and 4) the realities of vendor lock-in due to the poor transferability of LLM prompts.
Temporal Tokenization Strategies for Event Sequence Modeling with Large Language Models
Dec 16, 2025Representing continuous time is a critical and under-explored challenge in modeling temporal event sequences with large language models (LLMs). Various strategies like byte-level representations or calendar tokens have been proposed. However, the optimal approach remains unclear, especially given the diverse statistical distributions of real-world event data, which range from smooth log-normal to discrete, spiky patterns. This paper presents the first empirical study of temporal tokenization for event sequences, comparing distinct encoding strategies: naive numeric strings, high-precision byte-level representations, human-semantic calendar tokens, classic uniform binning, and adaptive residual scalar quantization. We evaluate these strategies by fine-tuning LLMs on real-world datasets that exemplify these diverse distributions. Our analysis reveals that no single strategy is universally superior; instead, prediction performance depends heavily on aligning the tokenizer with the data's statistical properties, with log-based strategies excelling on skewed distributions and human-centric formats proving robust for mixed modalities.
Leveraging Parameter Space Symmetries for Reasoning Skill Transfer in LLMs
Nov 13, 2025Task arithmetic is a powerful technique for transferring skills between Large Language Models (LLMs), but it often suffers from negative interference when models have diverged during training. We address this limitation by first aligning the models' parameter spaces, leveraging the inherent permutation, rotation, and scaling symmetries of Transformer architectures. We adapt parameter space alignment for modern Grouped-Query Attention (GQA) and SwiGLU layers, exploring both weight-based and activation-based approaches. Using this alignment-first strategy, we successfully transfer advanced reasoning skills to a non-reasoning model. Experiments on challenging reasoning benchmarks show that our method consistently outperforms standard task arithmetic. This work provides an effective approach for merging and transferring specialized skills across evolving LLM families, reducing redundant fine-tuning and enhancing model adaptability.
T1: A Tool-Oriented Conversational Dataset for Multi-Turn Agentic Planning
May 22, 2025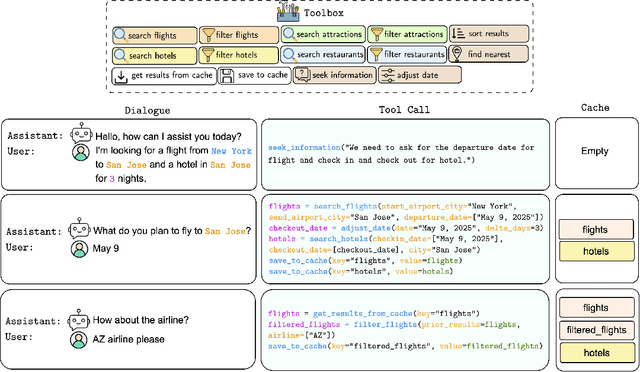
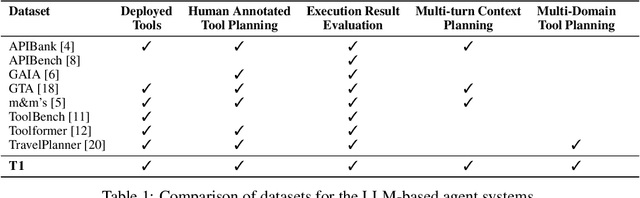


Large Language Models (LLMs) have demonstrated impressive capabilities as intelligent agents capable of solving complex problems. However, effective planning in scenarios involving dependencies between API or tool calls-particularly in multi-turn conversations-remains a significant challenge. To address this, we introduce T1, a tool-augmented, multi-domain, multi-turn conversational dataset specifically designed to capture and manage inter-tool dependencies across diverse domains. T1 enables rigorous evaluation of agents' ability to coordinate tool use across nine distinct domains (4 single domain and 5 multi-domain) with the help of an integrated caching mechanism for both short- and long-term memory, while supporting dynamic replanning-such as deciding whether to recompute or reuse cached results. Beyond facilitating research on tool use and planning, T1 also serves as a benchmark for evaluating the performance of open-source language models. We present results powered by T1-Agent, highlighting their ability to plan and reason in complex, tool-dependent scenarios.