 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Generative Models Meet Compressed Sensing, with Applications to Image Data and Financial Time Series
Sep 04, 2025



This paper develops dimension reduction techniques for accelerating diffusion model inference in the context of synthetic data generation. The idea is to integrate compressed sensing into diffusion models: (i) compress the data into a latent space, (ii) train a diffusion model in the latent space, and (iii) apply a compressed sensing algorithm to the samples generated in the latent space, facilitating the efficiency of both model training and inference. Under suitable sparsity assumptions on data, the proposed algorithm is proved to enjoy faster convergence by combining diffusion model inference with sparse recovery. As a byproduct, we obtain an optimal value for the latent space dimension. We also conduct numerical experiments on a range of datasets, including image data (handwritten digits, medical images, and climate data) and financial time series for stress testing.
Fine-Tuning Diffusion Generative Models via Rich Preference Optimization
Mar 13, 2025
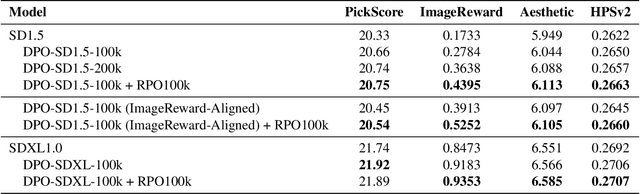
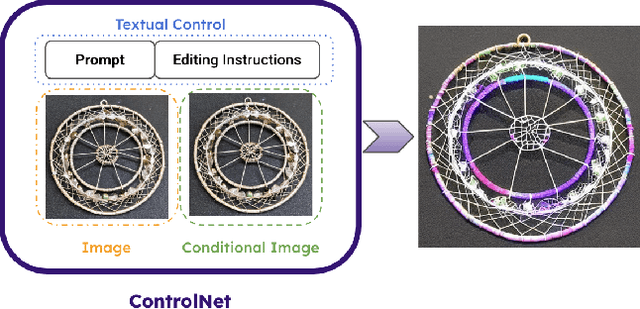
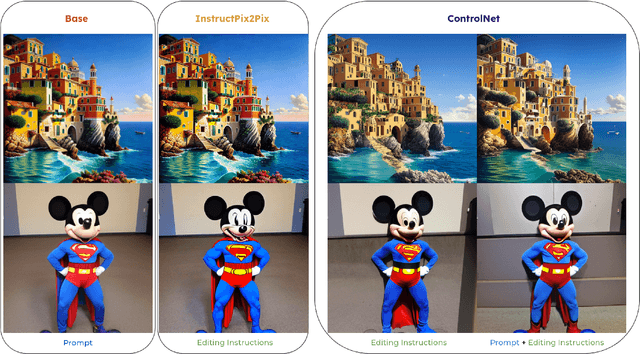
We introduce Rich Preference Optimization (RPO), a novel pipeline that leverages rich feedback signals to improve the curation of preference pairs for fine-tuning text-to-image diffusion models. Traditional methods, like Diffusion-DPO, often rely solely on reward model labeling, which can be opaque, offer limited insights into the rationale behind preferences, and are prone to issues such as reward hacking or overfitting. In contrast, our approach begins with generating detailed critiques of synthesized images to extract reliable and actionable image editing instructions. By implementing these instructions, we create refined images, resulting in synthetic, informative preference pairs that serve as enhanced tuning datasets. We demonstrate the effectiveness of our pipeline and the resulting datasets in fine-tuning state-of-the-art diffusion models.
Score as Action: Fine-Tuning Diffusion Generative Models by Continuous-time Reinforcement Learning
Feb 03, 2025



Reinforcement learning from human feedback (RLHF), which aligns a diffusion model with input prompt, has become a crucial step in building reliable generative AI models. Most works in this area use a discrete-time formulation, which is prone to induced errors, and often not applicable to models with higher-order/black-box solvers. The objective of this study is to develop a disciplined approach to fine-tune diffusion models using continuous-time RL, formulated as a stochastic control problem with a reward function that aligns the end result (terminal state) with input prompt. The key idea is to treat score matching as controls or actions, and thereby making connections to policy optimization and regularization in continuous-time RL. To carry out this idea, we lay out a new policy optimization framework for continuous-time RL, and illustrate its potential in enhancing the value networks design space via leveraging the structural property of diffusion models. We validate the advantages of our method by experiments in downstream tasks of fine-tuning large-scale Text2Image models of Stable Diffusion v1.5.
RainbowPO: A Unified Framework for Combining Improvements in Preference Optimization
Oct 05, 2024



Recently, numerous preference optimization algorithms have been introduced as extensions to the Direct Preference Optimization (DPO) family. While these methods have successfully aligned models with human preferences, there is a lack of understanding regarding the contributions of their additional components. Moreover, fair and consistent comparisons are scarce, making it difficult to discern which components genuinely enhance downstream performance. In this work, we propose RainbowPO, a unified framework that demystifies the effectiveness of existing DPO methods by categorizing their key components into seven broad directions. We integrate these components into a single cohesive objective, enhancing the performance of each individual element. Through extensive experiments, we demonstrate that RainbowPO outperforms existing DPO variants. Additionally, we provide insights to guide researchers in developing new DPO methods and assist practitioners in their implementations.
Preference Tuning with Human Feedback on Language, Speech, and Vision Tasks: A Survey
Sep 17, 2024



Preference tuning is a crucial process for aligning deep generative models with human preferences. This survey offers a thorough overview of recent advancements in preference tuning and the integration of human feedback. The paper is organized into three main sections: 1) introduction and preliminaries: an introduction to reinforcement learning frameworks, preference tuning tasks, models, and datasets across various modalities: language, speech, and vision, as well as different policy approaches, 2) in-depth examination of each preference tuning approach: a detailed analysis of the methods used in preference tuning, and 3) applications, discussion, and future directions: an exploration of the applications of preference tuning in downstream tasks, including evaluation methods for different modalities, and an outlook on future research directions. Our objective is to present the latest methodologies in preference tuning and model alignment, enhancing the understanding of this field for researchers and practitioners. We hope to encourage further engagement and innovation in this area.
Scores as Actions: a framework of fine-tuning diffusion models by continuous-time reinforcement learning
Sep 12, 2024Reinforcement Learning from human feedback (RLHF) has been shown a promising direction for aligning generative models with human intent and has also been explored in recent works for alignment of diffusion generative models. In this work, we provide a rigorous treatment by formulating the task of fine-tuning diffusion models, with reward functions learned from human feedback, as an exploratory continuous-time stochastic control problem. Our key idea lies in treating the score-matching functions as controls/actions, and upon this, we develop a unified framework from a continuous-time perspective, to employ reinforcement learning (RL) algorithms in terms of improving the generation quality of diffusion models. We also develop the corresponding continuous-time RL theory for policy optimization and regularization under assumptions of stochastic different equations driven environment. Experiments on the text-to-image (T2I) generation will be reported in the accompanied paper.
Policy Optimization for Continuous Reinforcement Learning
Jun 02, 2023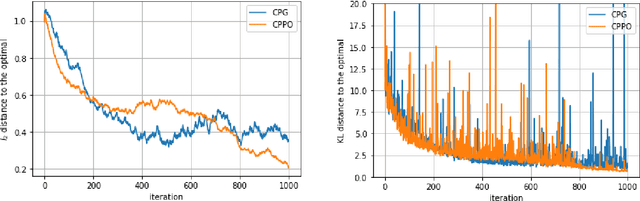
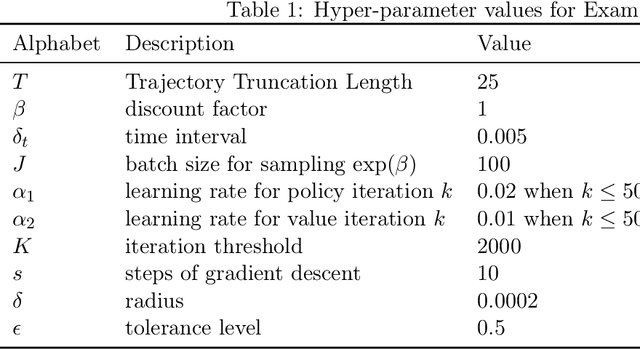


We study reinforcement learning (RL) in the setting of continuous time and space, for an infinite horizon with a discounted objective and the underlying dynamics driven by a stochastic differential equation. Built upon recent advances in the continuous approach to RL, we develop a notion of occupation time (specifically for a discounted objective), and show how it can be effectively used to derive performance-difference and local-approximation formulas. We further extend these results to illustrate their applications in the PG (policy gradient) and TRPO/PPO (trust region policy optimization/ proximal policy optimization) methods, which have been familiar and powerful tools in the discrete RL setting but under-developed in continuous RL. Through numerical experiments, we demonstrate the effectiveness and advantages of our approach.