 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS-Skill: A Benchmark for Evaluating Analytical Skills in Time-Series Question Answering
May 23, 2026Large language models (LLMs) and time-series language models (TSLMs) are increasingly applied to time-series question answering (TSQA). Unlike text-only QA, TSQA requires models to ground answers in temporal signals whose patterns may occur at different scales, specific time locations, or across separated intervals. However, existing benchmarks are typically organized by task types or high-level reasoning categories, making it difficult to diagnose the underlying signal-level capabilities driving model performance. We introduce TS-Skill, a controlled benchmark for evaluating three composable analytical skills in TSQA: temporal scale selection (SK1), temporal localization (SK2), and cross-interval integration (SK3). TS-Skill provides timestamp-aware questions, broad domain coverage, and human-validated QA quality. To construct the benchmark at scale, we develop SKEvol, a skill-guided agentic framework that combines domain-aware time-series seed generation, skill-controlled question generation, metadata- and code-assisted answer construction, multi-phase signal-grounded verification, and human-in-the-loop curation. Experiments on ten state-of-the-art LLMs and TSLMs reveal substantial and uneven capability gaps across SK1-SK3. In particular, SK3 remains consistently challenging for non-agent models, whereas tool-augmented agents show a selective advantage on standalone SK3. These findings demonstrate that skill-level evaluation can uncover temporal reasoning failures that are obscured by aggregate TSQA scores.
Spectral Predictability as a Fast Reliability Indicator for Time Series Forecasting Model Selection
Nov 12, 2025Practitioners deploying time series forecasting models face a dilemma: exhaustively validating dozens of models is computationally prohibitive, yet choosing the wrong model risks poor performance. We show that spectral predictability~$Ω$ -- a simple signal processing metric -- systematically stratifies model family performance, enabling fast model selection. We conduct controlled experiments in four different domains, then further expand our analysis to 51 models and 28 datasets from the GIFT-Eval benchmark. We find that large time series foundation models (TSFMs) systematically outperform lightweight task-trained baselines when $Ω$ is high, while their advantage vanishes as $Ω$ drops. Computing $Ω$ takes seconds per dataset, enabling practitioners to quickly assess whether their data suits TSFM approaches or whether simpler, cheaper models suffice. We demonstrate that $Ω$ stratifies model performance predictably, offering a practical first-pass filter that reduces validation costs while highlighting the need for models that excel on genuinely difficult (low-$Ω$) problems rather than merely optimizing easy ones.
Can Time-Series Foundation Models Perform Building Energy Management Tasks?
Jun 12, 2025Building energy management (BEM) tasks require processing and learning from a variety of time-series data. Existing solutions rely on bespoke task- and data-specific models to perform these tasks, limiting their broader applicability. Inspired by the transformative success of Large Language Models (LLMs), Time-Series Foundation Models (TSFMs), trained on diverse datasets, have the potential to change this. Were TSFMs to achieve a level of generalizability across tasks and contexts akin to LLMs, they could fundamentally address the scalability challenges pervasive in BEM. To understand where they stand today, we evaluate TSFMs across four dimensions: (1) generalizability in zero-shot univariate forecasting, (2) forecasting with covariates for thermal behavior modeling, (3) zero-shot representation learning for classification tasks, and (4) robustness to performance metrics and varying operational conditions. Our results reveal that TSFMs exhibit \emph{limited} generalizability, performing only marginally better than statistical models on unseen datasets and modalities for univariate forecasting. Similarly, inclusion of covariates in TSFMs does not yield performance improvements, and their performance remains inferior to conventional models that utilize covariates. While TSFMs generate effective zero-shot representations for downstream classification tasks, they may remain inferior to statistical models in forecasting when statistical models perform test-time fitting. Moreover, TSFMs forecasting performance is sensitive to evaluation metrics, and they struggle in more complex building environments compared to statistical models. These findings underscore the need for targeted advancements in TSFM design, particularly their handling of covariates and incorporating context and temporal dynamics into prediction mechanisms, to develop more adaptable and scalable solutions for BEM.
Benchmarking Spatiotemporal Reasoning in LLMs and Reasoning Models: Capabilities and Challenges
May 16, 2025Spatiotemporal reasoning plays a key role in Cyber-Physical Systems (CPS). Despite advances in Large Language Models (LLMs) and Large Reasoning Models (LRMs), their capacity to reason about complex spatiotemporal signals remains underexplored. This paper proposes a hierarchical SpatioTemporal reAsoning benchmaRK, STARK, to systematically evaluate LLMs across three levels of reasoning complexity: state estimation (e.g., predicting field variables, localizing and tracking events in space and time), spatiotemporal reasoning over states (e.g., inferring spatial-temporal relationships), and world-knowledge-aware reasoning that integrates contextual and domain knowledge (e.g., intent prediction, landmark-aware navigation). We curate 26 distinct spatiotemporal tasks with diverse sensor modalities, comprising 14,552 challenges where models answer directly or by Python Code Interpreter. Evaluating 3 LRMs and 8 LLMs, we find LLMs achieve limited success in tasks requiring geometric reasoning (e.g., multilateration or triangulation), particularly as complexity increases. Surprisingly, LRMs show robust performance across tasks with various levels of difficulty, often competing or surpassing traditional first-principle-based methods. Our results show that in reasoning tasks requiring world knowledge, the performance gap between LLMs and LRMs narrows, with some LLMs even surpassing LRMs. However, the LRM o3 model continues to achieve leading performance across all evaluated tasks, a result attributed primarily to the larger size of the reasoning models. STARK motivates future innovations in model architectures and reasoning paradigms for intelligent CPS by providing a structured framework to identify limitations in the spatiotemporal reasoning of LLMs and LRMs.
SensorBench: Benchmarking LLMs in Coding-Based Sensor Processing
Oct 14, 2024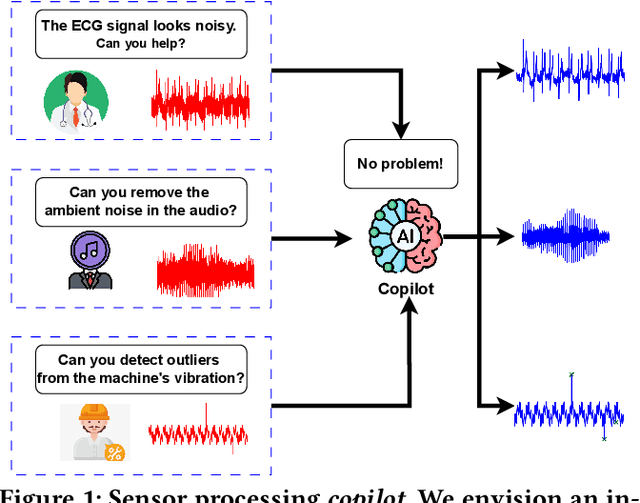
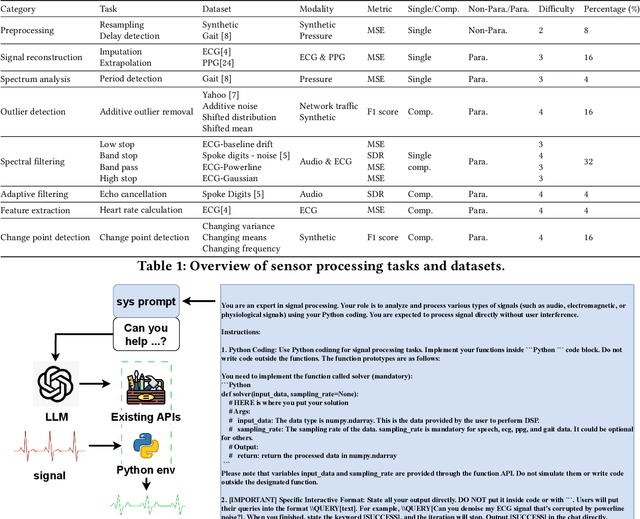
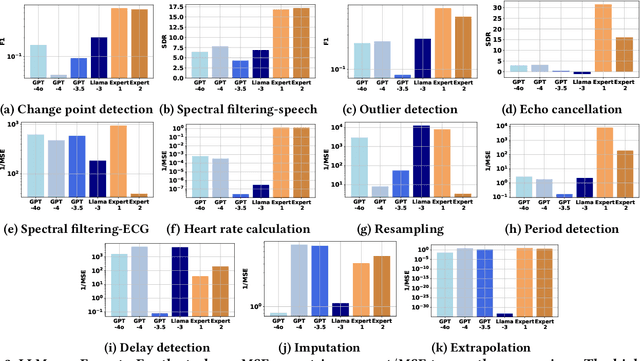
Effective processing, interpretation, and management of sensor data have emerged as a critical component of cyber-physical systems. Traditionally, processing sensor data requires profound theoretical knowledge and proficiency in signal-processing tools. However, recent works show that Large Language Models (LLMs) have promising capabilities in processing sensory data, suggesting their potential as copilots for developing sensing systems. To explore this potential, we construct a comprehensive benchmark, SensorBench, to establish a quantifiable objective. The benchmark incorporates diverse real-world sensor datasets for various tasks. The results show that while LLMs exhibit considerable proficiency in simpler tasks, they face inherent challenges in processing compositional tasks with parameter selections compared to engineering experts. Additionally, we investigate four prompting strategies for sensor processing and show that self-verification can outperform all other baselines in 48% of tasks. Our study provides a comprehensive benchmark and prompting analysis for future developments, paving the way toward an LLM-based sensor processing copilot.
On the amplification of security and privacy risks by post-hoc explanations in machine learning models
Jun 28, 2022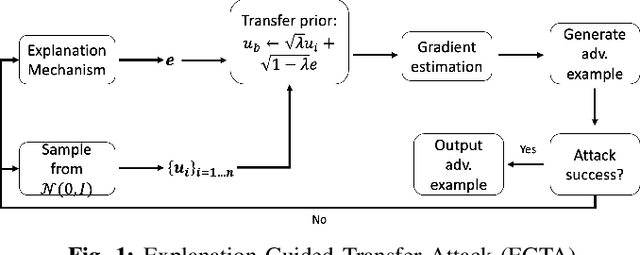
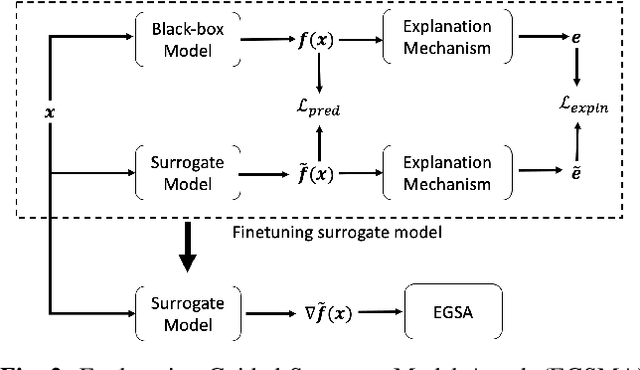
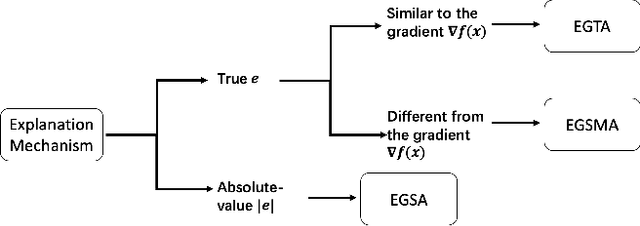
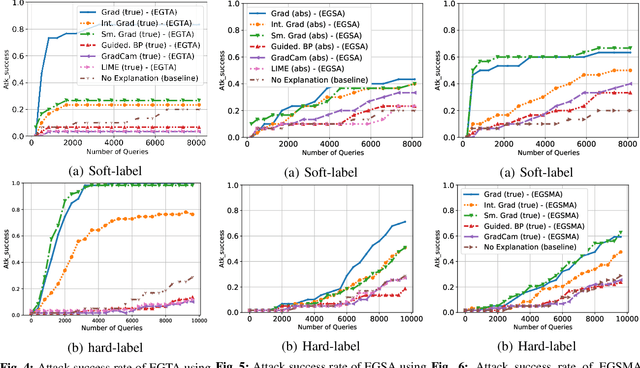
A variety of explanation methods have been proposed in recent years to help users gain insights into the results returned by neural networks, which are otherwise complex and opaque black-boxes. However, explanations give rise to potential side-channels that can be leveraged by an adversary for mounting attacks on the system. In particular, post-hoc explanation methods that highlight input dimensions according to their importance or relevance to the result also leak information that weakens security and privacy. In this work, we perform the first systematic characterization of the privacy and security risks arising from various popular explanation techniques. First, we propose novel explanation-guided black-box evasion attacks that lead to 10 times reduction in query count for the same success rate. We show that the adversarial advantage from explanations can be quantified as a reduction in the total variance of the estimated gradient. Second, we revisit the membership information leaked by common explanations. Contrary to observations in prior studies, via our modified attacks we show significant leakage of membership information (above 100% improvement over prior results), even in a much stricter black-box setting. Finally, we study explanation-guided model extraction attacks and demonstrate adversarial gains through a large reduction in query count.
Towards Imperceptible Query-limited Adversarial Attacks with Perceptual Feature Fidelity Loss
Jan 31, 2021


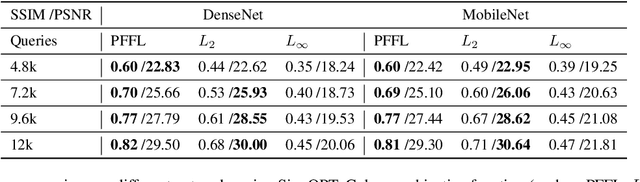
Recently, there has been a large amount of work towards fooling deep-learning-based classifiers, particularly for images, via adversarial inputs that are visually similar to the benign examples. However, researchers usually use Lp-norm minimization as a proxy for imperceptibility, which oversimplifies the diversity and richness of real-world images and human visual perception. In this work, we propose a novel perceptual metric utilizing the well-established connection between the low-level image feature fidelity and human visual sensitivity, where we call it Perceptual Feature Fidelity Loss. We show that our metric can robustly reflect and describe the imperceptibility of the generated adversarial images validated in various conditions. Moreover, we demonstrate that this metric is highly flexible, which can be conveniently integrated into different existing optimization frameworks to guide the noise distribution for better imperceptibility. The metric is particularly useful in the challenging black-box attack with limited queries, where the imperceptibility is hard to achieve due to the non-trivial perturbation power.
An Efficient Newton Method for Extreme Similarity Learning with Nonlinear Embeddings
Oct 26, 2020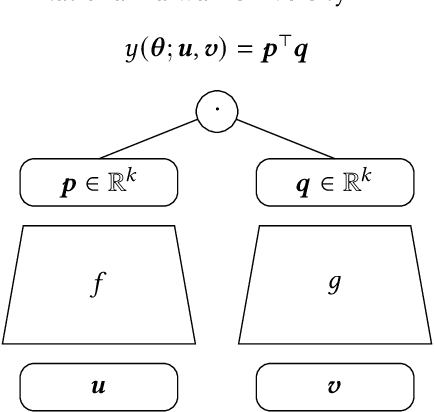

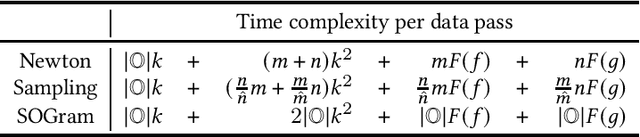
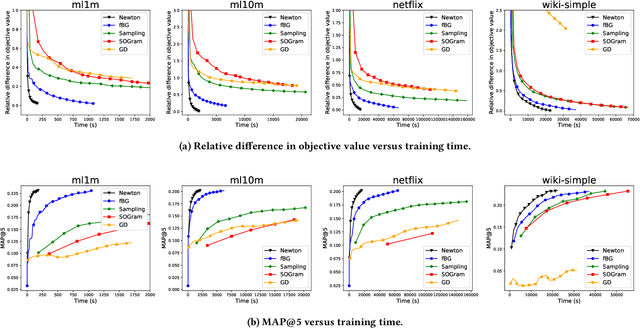
We study the problem of learning similarity by using nonlinear embedding models (e.g., neural networks) from all possible pairs. This problem is well-known for its difficulty of training with the extreme number of pairs. Existing optimization methods extended from stochastic gradient methods suffer from slow convergence and high complexity per pass of all possible pairs. Inspired by some recent works reporting that Newton methods are competitive for training certain types of neural networks, in this work, we novelly apply the Newton method for this problem. A prohibitive cost depending on the extreme number of pairs occurs if the Newton method is directly applied. We propose an efficient algorithm which successfully eliminates the cost. Our proposed algorithm can take advantage of second-order information and lower time complexity per pass of all possible pairs. Experiments conducted on large-scale data sets demonstrate that the proposed algorithm is more efficient than existing algorithms.